Text Sequence Classification with Huggingface models
You can use pymarlin.plugins.hf_seq_classification for out-of-the-box training of Huggingface models on a downstream sequence classification task. The plugin comes with a golden config file (YAML based). Simply modify a few arguments for your dataset and you're ready to go.
Walk-thru with a Kaggle dataset#
Let us walk through a sample task to better understand the usage. Download the dataset for the Coronavirus tweets NLP - Text Classification Kaggle challenge.
The plugin uses pandas to read the file into a dataframe, however the expected encoding is utf-8. This dataset has a different encoding so we will need to do some preprocessing and create a train-val split.
Set up the YAML config file#
The dataset contains 2 columns OriginalTweet, Sentiment. The goal is to predict the sentiment of the tweet i.e. text classification with a single sequence. We will try out Huggingface's RoBERTa model for this. For the sake of this tutorial, we will directly use OriginalTweet as the text sequence input to the model with no additional data processing steps.
Copy the config.yaml file from here to your working directory. You can choose to either edit the config file directly, or override the arguments from commandline. Below is the list of arguments that you need to modify for this dataset.
You can also override the default values in the config through CLI. For example:
Training#
Create a python script (say run.py) with the following lines of code. Alternatively, you can run it through Python interpreter.
This experiment may be too slow to run on local machine (without gpu). You can switch between trainer backends: sp (singleprocess), sp-amp, ddp, ddp-amp (ddp with mixed precision).
Command to run using DistributedDataParallel:
A logs folder should have been created which contains tensorboard log.
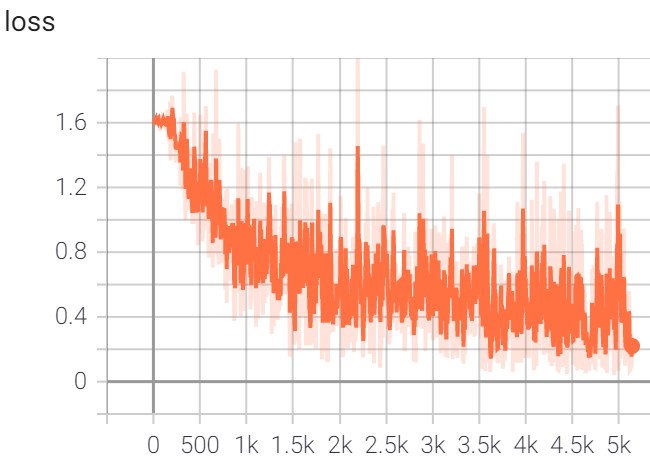
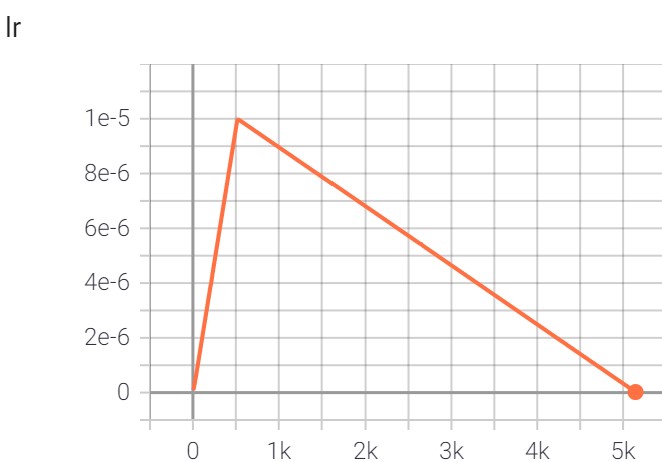
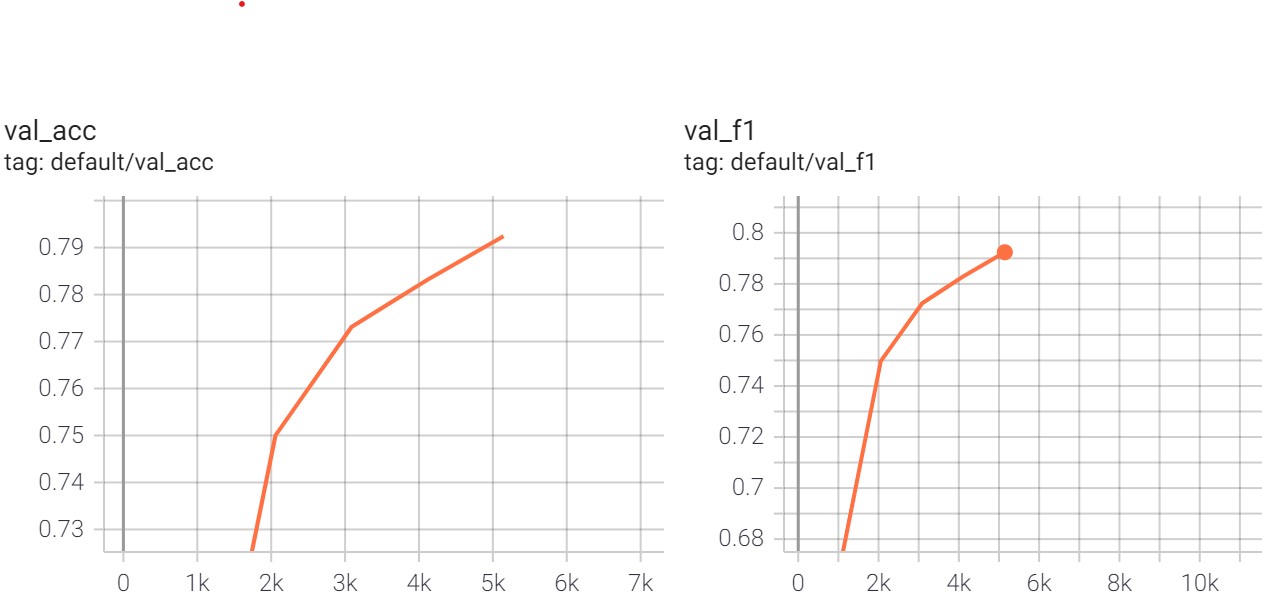
Evaluate the finetuned model on the test set#
The config.yaml file has a section ckpt which contains all checkpointer related arguments. The path specified in model_state_save_dir should contain your Pytorch model checkpoints.
The model state dict will contain the prefix model to all the keys of the Huggingface model state dict. This is because the HfSeqClassificationModuleInterface holds the Huggingface model in the variable model and the pymarlin module_interface itself is a torch.nn.Module.
First we will modify the state dict to remove the extra model prefix so it can be re-loaded into Huggingface Roberta.
Next, we need to edit the config.yaml file to point to this model file and the test dataset.
Run the following line of code to evaluate the finetuned model and compute accuracy and f1 on the test set:
Knowledge distillation#
Additionally, you can also distill the finetuned 12 layer Roberta model to a Roberta student, or even a different Huggingface transformer architecture. Only reduction in depth is supported for the plugin. The plugin offers a few loss types: soft labels (logits), hard labels, representations loss (attentions, hidden states).