Architecture and Terminology
Coral was designed with extensibility in mind. We aim to provide a generic framework for building automation, but we don't want to couple to that automation.
This is why we decided that all automation logic would be implemented in separate modules, outside of the core service. This way, we allow different teams to both reuse existing functionality, but also easily implement their own if something is not available or is very specific to their needs.
Here's a diagram of Coral architecture:
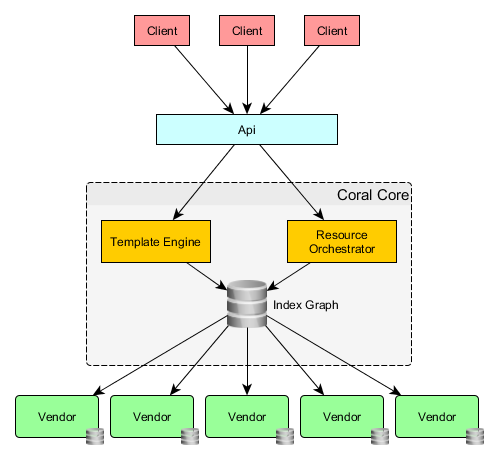
Clients
Coral itself is a standalone service which has no dependency on other services, but can integrate with other services and environments. This integration can be done by implementing different clients.
At the moment, we only have a single client implementation, the Azure DevOps extension. The reason for this is historical. Most of the resources we use for software delivery are hosted in ADO, and we wanted management of those to be automated. We leverage their authentication and authorization to ADO resources through the ADO extension SDK. This allows us to seamlessly integrate into the ADO UX with native look and feel.
We are planning to have a standalone client as well. Prerequisite for this is inbound OAuth for Coral API which currently doesn't exist, but is in the plans.
Api
In order to keep the complexity, coupling and maintenance cost to the minimum, Api declares a fixed contract for clients. We aim to keep the number of changes to this contract to a minimum. This would allow us to minimize the cost of maintenance of clients as well.
The API exposes 3 generic primitives. Each primitive is uniquely identifiable by a custom URI that Coral knows how to interpret. These will be explained in the following sections. These basic primitives are managed by Coral Core.
The full API can be explored with Swagger.
Core
The responsibility of Coral Core is to orchestrate creation and management of resources. In order to do this, Coral stores an index of interdependent URI references to the primitives that are hosted by Vendors.
Index Graph
To understand what Coral Core is and does, it is best to look at its storage model:
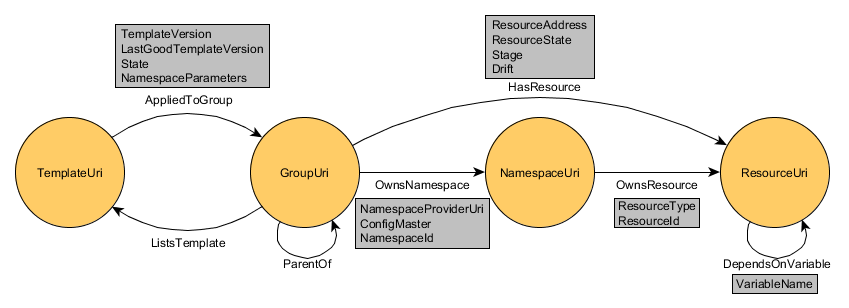
Here are the general principles of the model:
- Each vertex represents a single Coral primitive that is hosted by any vendor.
- Vertices store a URI to the primitive. This URI will be used to contact the vendor and interact with that primitive when necessary. For example, when Coral decides it is time to create a resource (e.g. a Git Repository or an ADO Build Definition), it will use the URI stored in a vertex to reference the resource primitive hosted by the ADO vendor, and will ask the vendor to provision the given resource.
- Vertices must not store any other properties. This way, we ensure that the state of all primitives is kept entirely in the vendors which is where it belongs.
- All the Coral required state is stored in edges.
Coral Core uses a graph database backed by Azure Cosmos DB.
Resource
Automated Resource management is what Coral is all about. In order to support that, Coral needs to keep track of all the resources it's managing. This is the responsibility of the resource primitive. This primitive is used for creation, deletion and updating resources managed by Coral.
When a vendor creates a resource, it persists its resource model. This model is stored in the vendor, and Coral Core has no direct access to it. This model stores information about the created resource. Properties from this model can be referenced by other resources. We call these references dynamic variables.
Dynamic variables implicitly declare dependencies between resources. For example, when automating creation of branch policies in ADO, we need to know the id of the git repository we will be applying said policies. Since this id is not present before the repository is created, we can declare this dependency on the repository id using a dynamic variable. This will let Coral know that repository needs to be created before policies can be. This information will be used to orchestrate automated creation of these resources.
Resource Orchestrator
Each resource in the graph contains a state that is persisted in the graph store. This state, along with the states of inbound/outbound dependencies are used to orchestrate operations against any particular resource.
Supported resource operations are:
- Create
- Update
- Delete
- Import
All the operations by default require approval. For this, we use the following approval state machine:
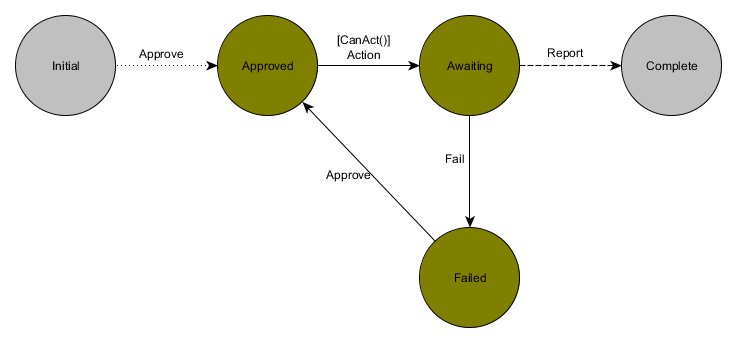
The CanAct() condition is used to check if dependencies (inbound or outbound) are in the expected state required for a particular operation. For example, one will not be able to transition from "CreateApproved" state to "AwaitingCreate" until all the outbound dependencies are in "Created" state. Similarly, the state machine will only allow the transition to "AwaitingDelete" once all the inbound dependencies have moved to "Deleted".
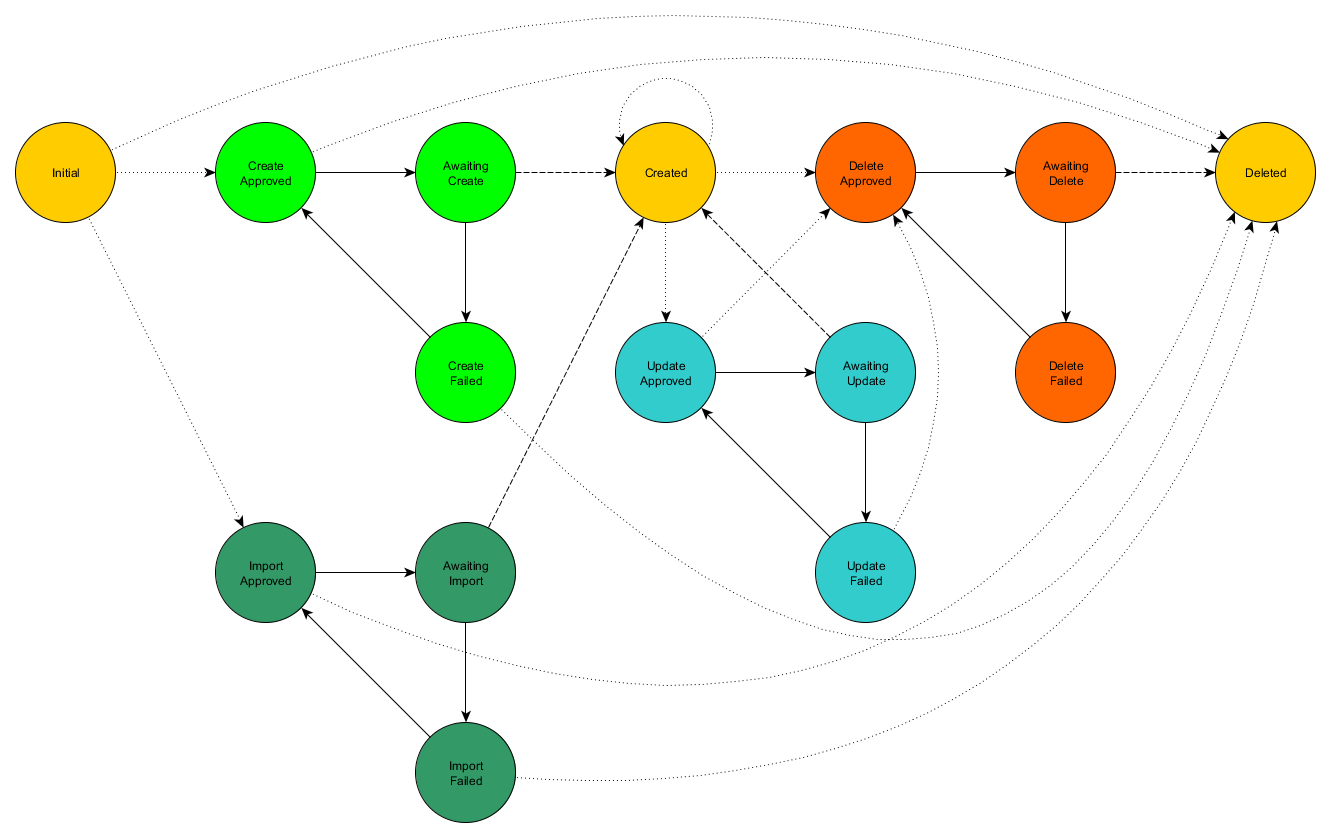
The full resource state machine consists of 3 approval flows (one for each operation) with some custom transitions:
Namespace
Namespaces are used to group tightly coupled resources together in order to simplify their configuration. For example, if we want Coral to create a Git Repository, we will most likely want branch policies for it to be configured in the same file. This will put these resources in the same namespace.
Group
Group is the central primitive of Coral Core. It serves the following purposes:
- Grouping of related Coral managed resources. All the resources within a group form a resource graph that is managed together because of the possible dependencies between them
- Provides the extension point for vendors to integrate Coral into hierarchies of external systems. For example, the ADO vendor declares the Account->Project->Pipeline hierarchy that maps to ADO accounts and projects, and additionally adds the concept of pipelines which the current ADO client uses to integrate Coral into the ADO Pipelines vertical. Coral can automatically deduce the ADO hierarchy context using the ADO vendor. If you send a request to Coral to create a pipeline under project P under account A, Coral will automatically assign P as the parent of the pipeline, and A as the parent of P.
At the current state, these are the only responsibilities of Coral Groups, but we have more plans for them in the future:
- Template parameter defaults: Templates should be as reusable as possible. Unfortunately, this means complex templates will require a lot of parameters. We need to tackle this problem because otherwise requesting a pipeline will be complex for users, and it would be hard to bring alignment into how a template is used under some group. For example, if you want to create a build definition in ADO, you need to select the agent pool and queue. It would be convenient if we could store these 2 parameter defaults for the whole ADO project to avoid having to pass it in for each pipeline request.
- Authorization: Leverage existing authorization mechanism of external services to allow Coral integrate to their security models. For example, the ADO vendor could choose to only allow project admins to create resources under a project group
- Elevation of privileges: Admins could choose to allow users without privileges in certain groups to controllably use their credentials to do certain tasks without the need for approval. For example, in ADO, project or account admins could choose to trust their access tokens with the Coral ADO Vendor which would safely store them in KeyVault. Then, admins could set rules for what this tokens can be used in that particular project or account. This would be dependant on authorization.
- Shared resources: A resource can be owned by a single group, but can be referenced by multiple. This allows for the resources to be shared between multiple groups. For example, if your org owns a cluster that is shared by multiple services, that cluster could be managed by Coral and assigned to an ADO account or project group. Then, you could create pipeline groups that don't manage their own clusters, but instead reference an existing one in the project or account group.
- Integration of custom hierarchy providers: Sometimes, a single hierarchy does not provide enough context about a certain group. In order to solve this problem, groups can have more than one parent. This allows for linking different hierarchies together. For example, a lot of teams in Microsoft today use ADO accounts and projects to manage the delivery lifecycle of their products, and in addition are required to register all of of this with Service Tree. By allowing linking of unrelated hierarchies in Coral, we wish to make it easier to automate these processes. Additionally, combined with other features of Coral Groups, more interesting opportunities arise. For example, we could automate registration of services with Service Tree, or leverage existing metadata in Service Tree to enforce certain policies that are currently hard to enforce.
- We believe there are more opportunities that we haven't thought of yet.
Template
Templates are the primary automation vehicle in Coral. They allow us to streamline creation and management of similar groups of resources. For example, we can have a template that allows us to get everything we need for development, building, and publishing of a NuGet package with all the compliance and other requirements. But this is just a simple scenario. Templates can be made for anything from a blank repository to a full blown service with sovereign clouds, different compliance requirements, cluster and monitoring setups, etc…
Templates can be provided by any vendor, but currently we only implement a single provider, which gets the templates from git repositories in ADO. Templates don't have to be source controlled, but it is recommended.
Vendors
Vendors are decoupled modules that externalize management of Coral primitives. They are plugins that allow Coral to interact with resources, groups and templates. Coral declares a contract which the vendors implement. This contract allows Coral to generically orchestrate primitives from potentially different vendors.
As was mentioned above, all vendorized primitives can be referenced by URIs that are stored in the index graph. These URIs need to make sense to Coral, but not necessarily to anyone else. We plan to support multiple URI schemes, but currently there is only one, local. The local scheme is used to reference vendors that are deployed along with the Coral Service. For example, in order to reference ADO primitives, you could use the vsts vendor that is currently being shipped with Coral. These primitives all have URIs starting with local://vsts/.
The reason for supporting local vendors is to speed up the development and allow us to churn on the contract without having to break external vendors. Once the contract stabilizes, we plan to support other vendor types. These could be in the form of Service Fabric Statefull services (since Coral runs in Service Fabric), or even completely separate REST, or RPC (e.g. gRPC) services hosted by anyone anywhere.