Experience
Motivation
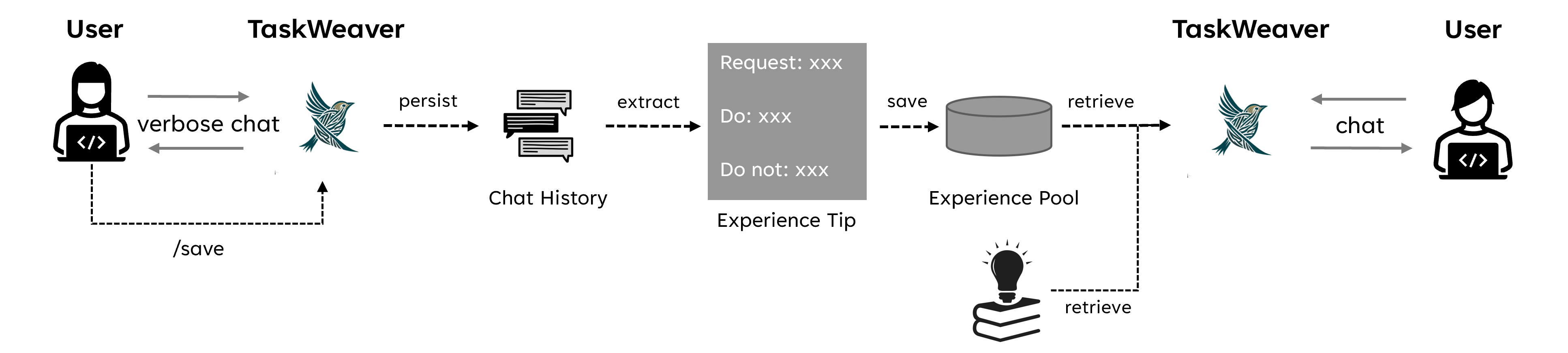
The agent developers can add examples to guide the planning and code generation. Alternatively, we also provide another way of saving user experiences to long-term memory. In practice, if the user asks TaskWeaver to solve a hard problem. TaskWeaver can first go wrong. But after several attempts or the user gives more instructions, the agent can finally solve the problem. However, next time, if the user asks a similar problem or even exactly the same problem. The agent is still hard to come up with the right solution at first because it does not memorize the experiences. Therefore, we proposed a mechanism called experience memory. Here is the basic idea. A user can issue a command to TaskWeaver to save chat history and then extract experience tips from it and save them into the experience pool. Later, when the agent sees similar requests, it will retrieve the experience from the memory to guide its planning and code generation. An experience tip is about what should do or should not do when seeing a request like this. We will add the retrieved experiences to the prompt when received a similar request afterward.
Quick start
In this quick start tutorial, we are going to show you how to enable the experience feature and save the chat history to the experience pool.
-
To enable the experience feature, you need to set the
planner.use_experienceandcode_generator.use_experienceparameter in the configuration file totrue. So, both the Planner and CodeInterpreter can use the experience to guide the planning and code generation. -
Start a new conversation with TaskWeaver. You will find
experiencedirectory is created in your project directory. Note that it is empty now because we have not saved any chat history yet. -
If you think the current chat history is worth saving, you can save it by typing command
/savein the console chat interface. And you will find a new file namedraw_exp_{session_id}.yamlcreated in theexperiencedirectory. -
Restart TaskWeaver and start a new conversation. In the initialization stage, TaskWeaver will read the
raw_exp_{session_id}.yamlfile and make a summarization in a new file namedexp_{session_id}.yaml. This process may take a while because TaskWeaver needs to call the LLM model to extract the experience tips from the chat history. -
Next time, when user send a similar query to TaskWeaver, it will retrieve the relevant experience and load it into the system prompt (for Planner and CodeInterpreter). In this way, the experience can be used to guide the future conversation.
The experience folder is created in the project directory.
You can change the location of the experience folder by setting the session.experience_dir parameter
in the configuration file.
A walk-through example
- Start a new conversation with TaskWeaver. Send a request "calculate the mean value of ./project/sample_data/data_demo.csv" to TaskWeaver.
- You will find TaskWeaver made a mistake, calculating the mean value of the non-numerical column. After several attempts, TaskWeaver fixed this issue.
=========================================================
_____ _ _ __
|_ _|_ _ ___| | _ | | / /__ ____ __ _____ _____
| |/ _` / __| |/ /| | /| / / _ \/ __ `/ | / / _ \/ ___/
| | (_| \__ \ < | |/ |/ / __/ /_/ /| |/ / __/ /
|_|\__,_|___/_|\_\|__/|__/\___/\__,_/ |___/\___/_/
=========================================================
TaskWeaver ▶ I am TaskWeaver, an AI assistant. To get started, could you please enter your request?
Human ▶ calculate the mean value of d:/demo_data.csv
╭───< Planner >
├─► [init_plan]
│ 1. load the data file
│ 2. calculate the mean value of the loaded data <sequentially depends on 1>
│ 3. report the result to the user <interactively depends on 2>
├─► [plan]
│ 1. instruct CodeInterpreter to load the data file and calculate the mean value of the loaded data
│ 2. report the result to the user
├─► [current_plan_step] 1. instruct CodeInterpreter to load the data file and calculate the mean value of the loaded data
├──● Please load the data file d:/demo_data.csv and calculate the mean value of the loaded data
╰──● sending message to CodeInterpreter
╭───< CodeInterpreter >
├─► [thought] ProgramApe will generate a code snippet to load the data file d:/demo_data.csv and calculate the mean value of the loaded data using pandas.
├─► [python]
│ import pandas as pd
│
│ data_file_path = "d:/demo_data.csv"
│ data_df = pd.read_csv(data_file_path)
│ mean_value = data_df.mean()
│ mean_value
├─► [verification] NONE
├─► [code_error] No code verification is performed.
├─► [execution_status] FAILURE
├─► [execution_result]
│ The execution of the generated python code above has failed
│
│ During execution, the following messages were logged:
│ Traceback (most recent call last):
│
│ Cell In[1], line 5
│ mean_value = data_df.mean()
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\frame.py:11335 in mean
│ result = super().mean(axis, skipna, numeric_only, **kwargs)
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\generic.py:11984 in mean
│ return self._stat_function(
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\generic.py:11941 in _stat_function
│ return self._reduce(
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\frame.py:11204 in _reduce
│ res = df._mgr.reduce(blk_func)
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\internals\managers.py:1459 in reduce
│ nbs = blk.reduce(func)
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\internals\blocks.py:377 in reduce
│ result = func(self.values)
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\frame.py:11136 in blk_func
│ ret
│
├─► [artifact_paths] []
├──● The following python code has been executed:
│ ```python
│ import pandas as pd
│
│ data_file_path = "d:/demo_data.csv"
│ data_df = pd.read_csv(data_file_path)
│ mean_value = data_df.mean()
│ mean_value
│ ```
│
│
│ The execution of the generated python code above has failed
│
│ During execution, the following messages were logged:
│ Traceback (most recent call last):
│
│ Cell In[1], line 5
│ mean_value = data_df.mean()
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\frame.py:11335 in mean
│ result = super().mean(axis, skipna, numeric_only, **kwargs)
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\generic.py:11984 in mean
│ return self._stat_function(
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\generic.py:11941 in _stat_function
│ return self._reduce(
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\frame.py:11204 in _reduce
│ res = df._mgr.reduce(blk_func)
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\internals\managers.py:1459 in reduce
│ nbs = blk.reduce(func)
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\internals\blocks.py:377 in reduce
│ result = func(self.values)
│
│ File D:\python_project\Octopus\venv\Lib\site-packages\pandas\core\frame.py:11136 in blk_func
│ ret
│
├─► [revise_message]
│ The execution of the previous generated code has failed. If you think you can fix the problem by rewriting the code, please generate code and run it again.
│ Otherwise, please explain the problem to me.
╰──● sending message to CodeInterpreter
╭───< CodeInterpreter >
├─► [thought] ProgramApe will generate a code snippet to load the data file d:/demo_data.csv and calculate the mean value of the loaded data using pandas, considering the execution
│ error.
├─► [python]
│ import pandas as pd
│
│ data_file_path = "d:/demo_data.csv"
│ data_df = pd.read_csv(data_file_path)
│ mean_value = data_df.mean(axis=0, numeric_only=True)
│ mean_value
├─► [verification] NONE
├─► [code_error] No code verification is performed.
├─► [execution_status] SUCCESS
├─► [execution_result]
│ The execution of the generated python code above has succeeded
│
│ The result of above Python code after execution is:
│ Count 78172.75
│ dtype: float64
├─► [artifact_paths] []
├──● The following python code has been executed:
│ ```python
│ import pandas as pd
│
│ data_file_path = "d:/demo_data.csv"
│ data_df = pd.read_csv(data_file_path)
│ mean_value = data_df.mean(axis=0, numeric_only=True)
│ mean_value
│ ```
│
│
│ The execution of the generated python code above has succeeded
│
│ The result of above Python code after execution is:
│ Count 78172.75
│ dtype: float64
╰──● sending message to Planner
╭───< Planner >
├─► [init_plan]
│ 1. load the data file
│ 2. calculate the mean value of the loaded data <sequentially depends on 1>
│ 3. report the result to the user <interactively depends on 2>
├─► [plan]
│ 1. instruct CodeInterpreter to load the data file and calculate the mean value of the loaded data
│ 2. report the result to the user
├─► [current_plan_step] 2. report the result to the user
├──● The mean value of the data in d:/demo_data.csv is 78172.75
╰──● sending message to User
TaskWeaver ▶ The mean value of the data in d:/demo_data.csv is 78172.75
- We can issue the
/savecommand from the console chat interface to save the chat history. Then, after we restart TaskWeaver, we can see the experience summarized from the last chat history is below:
exp_id: 20231228-073922-9b411afd
experience_text: "User Query: get the mean value of d:/demo_data.csv
Error Resolution:
- Error 1: The initial code failed to execute because it tried to calculate the mean value of all columns, including non-numeric columns.
- Resolution 1: The code was revised to check for non-numeric columns and only calculate the mean value for numeric columns.
Preferences:
- Preference 1: The user prefers to calculate the mean value of the "Count" column in the data."
raw_experience_path: D:\project\experience\raw_exp_20231228-073922-9b411afd.yaml
embedding_model: text-embedding-ada-002
embedding: ...
- Send a similar request "calculate the variance value of ./project/sample_data/data_demo.csv" to TaskWeaver. You will find TaskWeaver will not make the same mistake again. It will ask User to confirm the column name to calculate the variance value.
=========================================================
_____ _ _ __
|_ _|_ _ ___| | _ | | / /__ ____ __ _____ _____
| |/ _` / __| |/ /| | /| / / _ \/ __ `/ | / / _ \/ ___/
| | (_| \__ \ < | |/ |/ / __/ /_/ /| |/ / __/ /
|_|\__,_|___/_|\_\|__/|__/\___/\__,_/ |___/\___/_/
=========================================================
TaskWeaver ▶ I am TaskWeaver, an AI assistant. To get started, could you please enter your request?
Human ▶ calculate the variance value of d:/demo_data.csv
╭───< Planner >TaskWeaver] preparing <=�=>
├─► [init_plan]
│ 1. load the data file
│ 2. confirm the columns to calculate variance <interactively depends on 1>
│ 3. calculate the variance value for the selected columns <sequentially depends on 2>
│ 4. report the result to the user <interactively depends on 3>
├─► [plan] ▶ [Planner][plan] 1. instruct CodeInterpreter to load the data file 2. confirm the columns to calcu <=�=>
│ 1. instruct CodeInterpreter to load the data file
│ 2. confirm the columns to calculate variance
├─► [current_plan_step] 1. instruct CodeInterpreter to load the data file load the data file <=�=>
├──● Please load the data file d:/demo_data.csva file d:/demo_dat <=�=>
╰──● sending message to CodeInterpreter
╭───< CodeInterpreter >
├─► [thought] ProgramApe will generate a code snippet to load the data file d:/demo_data.csv using pandas.demo_data.csv using panda <=�=>
├─► [python]▶ [CodeInterpreter][python] import pandas as pd data_file_path = "d:/demo_data.csv" df = pd.read_csv(data_fil <=�=>
│ import pandas as pd
│
│ data_file_path = "d:/demo_data.csv"
│ df = pd.read_csv(data_file_path)
│ df
├─► [verification] NONE
├─► [code_error] No code verification is performed.
├─► [execution_status] SUCCESS] executing code <=�=>
├─► [execution_result]
│ The execution of the generated python code above has succeeded
│
│ The result of above Python code after execution is:
│ TimeBucket Count
│ 0 2023-02-01T00:00:00Z 67814
│ 1 2023-02-01T04:00:00Z 84569
│ .. ... ...
│ 718 2023-05-31T16:00:00Z 89912
│ 719 2023-05-31T20:00:00Z 87249
│
│ [720 rows x 2 columns]
├─► [artifact_paths] []
├──● The following python code has been executed:
│ ```python
│ import pandas as pd
│
│ data_file_path = "d:/demo_data.csv"
│ df = pd.read_csv(data_file_path)
│ df
│ ```
│
│
│ The execution of the generated python code above has succeeded
│
│ The result of above Python code after execution is:
│ TimeBucket Count
│ 0 2023-02-01T00:00:00Z 67814
│ 1 2023-02-01T04:00:00Z 84569
│ .. ... ...
│ 718 2023-05-31T16:00:00Z 89912
│ 719 2023-05-31T20:00:00Z 87249
│
│ [720 rows x 2 columns]
╰──● sending message to Planner
╭───< Planner >CodeInterpreter] finished <=�=>
├─► [init_plan]
│ 1. load the data file
│ 2. confirm the columns to calculate variance <interactively depends on 1>
│ 3. calculate the variance value for the selected columns <sequentially depends on 2>
│ 4. report the result to the user <interactively depends on 3>
├─► [plan] ▶ [Planner][plan] 1. instruct CodeInterpreter to load the data file 2. confirm the columns to calculate var <=�=>
│ 1. instruct CodeInterpreter to load the data file
│ 2. confirm the columns to calculate variance
├─► [current_plan_step] 2. confirm the columns to calculate variance calculate varia <=�=>
├──● The data file d:/demo_data.csv is loaded. The columns in the data are:
│
│ 1. TimeBucket
│ 2. Count
│
│ Please specify which column(s) you would like to calculate the variance for.
╰──● sending message to User
TaskWeaver ▶ The data file d:/demo_data.csv is loaded. The columns in the data are:
1. TimeBucket
2. Count
Please specify which column(s) you would like to calculate the variance for.
Human ▶ Count
╭───< Planner >TaskWeaver] preparing <=�=>
├─► [init_plan]
│ 1. load the data file
│ 2. confirm the columns to calculate variance <interactively depends on 1>
│ 3. calculate the variance value for the selected columns <sequentially depends on 2>
│ 4. report the result to the user <interactively depends on 3>
├─► [plan]
│ 1. instruct CodeInterpreter to load the data file
│ 2. confirm the columns to calculate variance
│ 3. instruct CodeInterpreter to calculate the variance value for the Count column
│ 4. report the result to the user
├─► [current_plan_step] 3. instruct CodeInterpreter to calculate the variance value for the Count columnor the Count col <=�=>
├──● Please calculate the variance value for the Count column in the loaded datalumn in the loaded <=�=>
╰──● sending message to CodeInterpreter
╭───< CodeInterpreter >
├─► [thought] ProgramApe will generate a code snippet to calculate the variance value for the Count column in the loaded data. column in the loaded dat <=�=>
├─► [python]▶ [CodeInterpreter][python] variance_count = df['Count'].var() varia <=�=>
│ variance_count = df['Count'].var()
│ variance_count
├─► [verification] NONE
├─► [code_error] No code verification is performed.
├─► [execution_status] SUCCESS] executing code <=�=>
├─► [execution_result]
│ The execution of the generated python code above has succeeded
│
│ The result of above Python code after execution is:
│ 263514550.45479834
├─► [artifact_paths] []
├──● The following python code has been executed:
│ ```python
│ variance_count = df['Count'].var()
│ variance_count
│ ```
│
│
│ The execution of the generated python code above has succeeded
│
│ The result of above Python code after execution is:
│ 263514550.45479834
╰──● sending message to Planner
╭───< Planner >CodeInterpreter] finished <=�=>
├─► [init_plan]
│ 1. load the data file
│ 2. confirm the columns to calculate variance <interactively depends on 1>
│ 3. calculate the variance value for the selected columns <sequentially depends on 2>
│ 4. report the result to the user <interactively depends on 3>
├─► [plan]
│ 1. instruct CodeInterpreter to load the data file
│ 2. confirm the columns to calculate variance
│ 3. instruct CodeInterpreter to calculate the variance value for the Count column
│ 4. report the result to the user
├─► [current_plan_step] 4. report the result to the user result to the u <=�=>
├──● The variance value for the Count column in the data file d:/demo_data.csv is 263,514,550.45a.csv is 263,51 <=�=>
╰──● sending message to User
TaskWeaver ▶ The variance value for the Count column in the data file d:/demo_data.csv is 263,514,550.45