Chat with PDF - test, evaluation and experimentation#
Authored by: 

We will walk you through how to use prompt flow Python SDK to test, evaluate and experiment with the “Chat with PDF” flow.
0. Install dependencies#
%pip install -r requirements.txt
1. Create connections#
Connection in prompt flow is for managing settings of your application behaviors incl. how to talk to different services (Azure OpenAI for example).
import promptflow
pf = promptflow.PFClient()
# List all the available connections
for c in pf.connections.list():
print(c.name + " (" + c.type + ")")
You will need to have a connection named “open_ai_connection” to run the chat_with_pdf flow.
# create needed connection
from promptflow.entities import AzureOpenAIConnection, OpenAIConnection
try:
conn_name = "open_ai_connection"
conn = pf.connections.get(name=conn_name)
print("using existing connection")
except:
# Follow https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/create-resource?pivots=web-portal to create an Azure OpenAI resource.
connection = AzureOpenAIConnection(
name=conn_name,
api_key="<user-input>",
api_base="<test_base>",
api_type="azure",
api_version="<test_version>",
)
# use this if you have an existing OpenAI account
# connection = OpenAIConnection(
# name=conn_name,
# api_key="<user-input>",
# )
conn = pf.connections.create_or_update(connection)
print("successfully created connection")
print(conn)
2. Test the flow#
Note: this sample uses predownloaded PDFs and prebuilt FAISS Index to speed up execution time.
You can remove the folders to start a fresh run.
# ./chat_with_pdf/.pdfs/ stores predownloaded PDFs
# ./chat_with_pdf/.index/ stores prebuilt index files
output = pf.flows.test(
".",
inputs={
"chat_history": [],
"pdf_url": "https://arxiv.org/pdf/1810.04805.pdf",
"question": "what is BERT?",
},
)
print(output)
3. Run the flow with a data file#
flow_path = "."
data_path = "./data/bert-paper-qna-3-line.jsonl"
config_2k_context = {
"EMBEDDING_MODEL_DEPLOYMENT_NAME": "text-embedding-ada-002",
"CHAT_MODEL_DEPLOYMENT_NAME": "gpt-4", # change this to the name of your deployment if you're using Azure OpenAI
"PROMPT_TOKEN_LIMIT": 2000,
"MAX_COMPLETION_TOKENS": 256,
"VERBOSE": True,
"CHUNK_SIZE": 1024,
"CHUNK_OVERLAP": 64,
}
column_mapping = {
"question": "${data.question}",
"pdf_url": "${data.pdf_url}",
"chat_history": "${data.chat_history}",
"config": config_2k_context,
}
run_2k_context = pf.run(flow=flow_path, data=data_path, column_mapping=column_mapping)
pf.stream(run_2k_context)
print(run_2k_context)
pf.get_details(run_2k_context)
4. Evaluate the “groundedness”#
The eval-groundedness flow is using ChatGPT/GPT4 model to grade the answers generated by chat-with-pdf flow.
eval_groundedness_flow_path = "../../evaluation/eval-groundedness/"
eval_groundedness_2k_context = pf.run(
flow=eval_groundedness_flow_path,
run=run_2k_context,
column_mapping={
"question": "${run.inputs.question}",
"answer": "${run.outputs.answer}",
"context": "${run.outputs.context}",
},
display_name="eval_groundedness_2k_context",
)
pf.stream(eval_groundedness_2k_context)
print(eval_groundedness_2k_context)
pf.get_details(eval_groundedness_2k_context)
pf.get_metrics(eval_groundedness_2k_context)
pf.visualize(eval_groundedness_2k_context)
You will see a web page like this. It gives you detail about how each row is graded and even the details how the evaluation run executes:
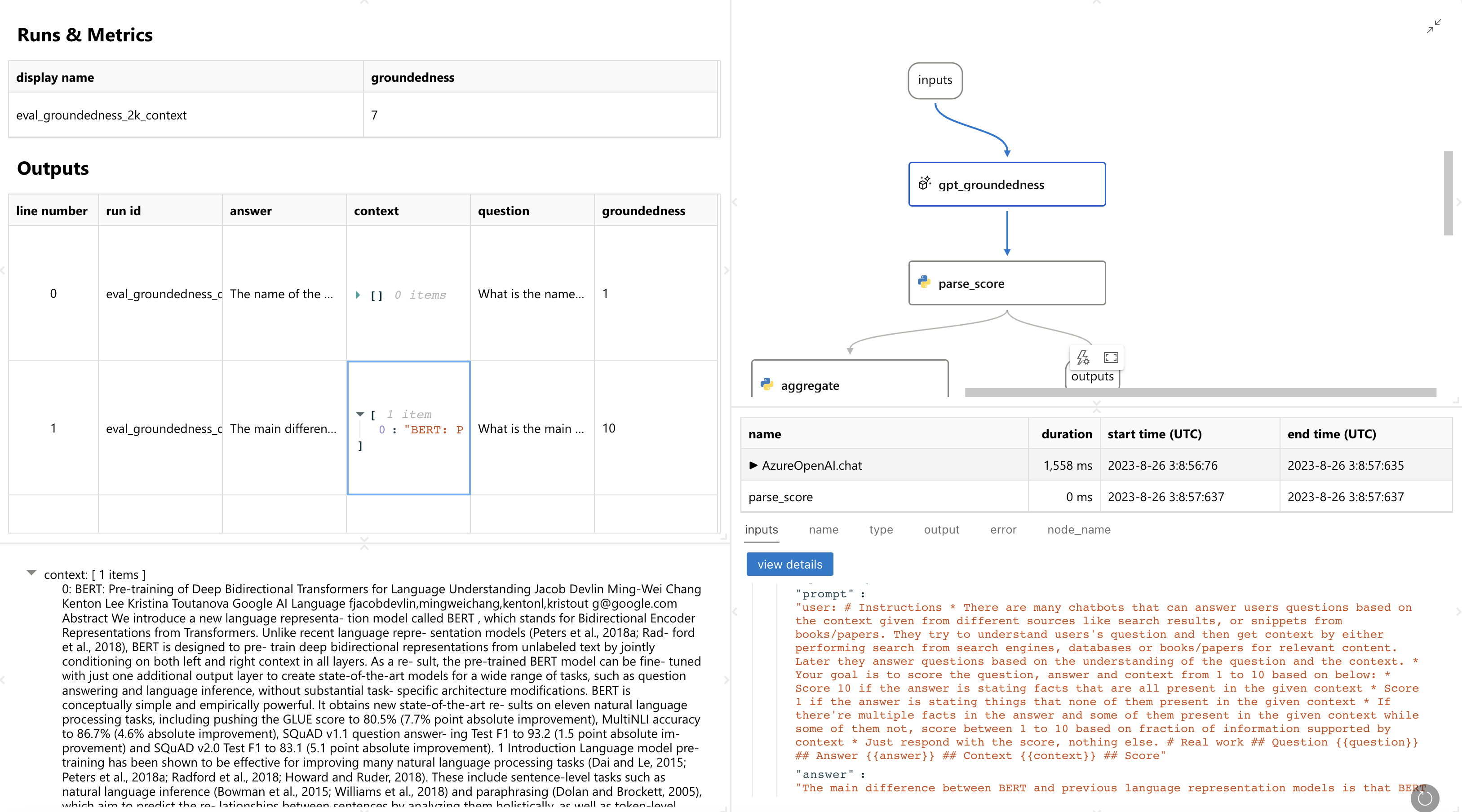
5. Try a different configuration and evaluate again - experimentation#
NOTE: since we only use 3 lines of test data in this example, and because of the non-deterministic nature of LLMs, don’t be surprised if you see exact same metrics when you run this process.
config_3k_context = {
"EMBEDDING_MODEL_DEPLOYMENT_NAME": "text-embedding-ada-002",
"CHAT_MODEL_DEPLOYMENT_NAME": "gpt-4", # change this to the name of your deployment if you're using Azure OpenAI
"PROMPT_TOKEN_LIMIT": 3000,
"MAX_COMPLETION_TOKENS": 256,
"VERBOSE": True,
"CHUNK_SIZE": 1024,
"CHUNK_OVERLAP": 64,
}
run_3k_context = pf.run(flow=flow_path, data=data_path, column_mapping=column_mapping)
pf.stream(run_3k_context)
print(run_3k_context)
eval_groundedness_3k_context = pf.run(
flow=eval_groundedness_flow_path,
run=run_3k_context,
column_mapping={
"question": "${run.inputs.question}",
"answer": "${run.outputs.answer}",
"context": "${run.outputs.context}",
},
display_name="eval_groundedness_3k_context",
)
pf.stream(eval_groundedness_3k_context)
print(eval_groundedness_3k_context)
pf.get_details(eval_groundedness_3k_context)
pf.visualize([eval_groundedness_2k_context, eval_groundedness_3k_context])