Run flows in Azure ML pipeline#
Authored by: 

Why use Azure machine learning(ML) pipelines to run your flows on the cloud?#
In real-world scenarios, flows serve various purposes. For example, consider a flow designed to evaluate the relevance score for a communication session between humans and agents. Suppose you want to trigger this flow every night to assess today’s performance and avoid peak hours for LLM (Language Model) endpoints. In this common scenario, people often encounter the following needs:
Handling Large Data Inputs: Running flows with thousands or millions of data inputs at once.
Scalability and Efficiency: Requiring a scalable, efficient, and resilient platform to ensure success.
Automations: Automatically triggering batch flows when upstream data is ready or at fixed intervals.
Azure ML pipelines address all these offline requirements effectively. With the integration of prompt flows and Azure ML pipeline, flow users could very easily achieve above goals and in this tutorial, you can learn:
How to use python SDK to automatically convert your flow into a ‘step’ in Azure ML pipeline.
How to feed your data into pipeline to trigger the batch flow runs.
How to build other pipeline steps ahead or behind your prompt flow step. e.g. data preprocessing or result aggregation.
How to setup a simple scheduler on my pipeline.
How to deploy pipeline to an Azure ML batch endpoint. Then I can invoke it with new data when needed.
Before you begin, consider the following prerequisites:
Introduction to Azure ML Platform:
Understand what Azure ML pipelines and component are.
Azure cloud setup:
An Azure account with an active subscription - Create an account for free
Create an Azure ML resource from Azure portal - Create a Azure ML workspace
Connect to your workspace then setup a basic computer cluster - Configure workspace
Local environment setup:
A python environment
Installed Azure Machine Learning Python SDK v2 - install instructions - check the getting started section and make sure version of ‘azure-ai-ml’ is higher than
1.12.0
1. Connect to Azure Machine Learning Workspace#
The workspace is the top-level resource for Azure Machine Learning, providing a centralized place to work with all the artifacts you create when you use Azure Machine Learning. In this section we will connect to the workspace in which the job will be run.
1.1 Import the required libraries#
# import required libraries
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
from azure.ai.ml import MLClient, load_component, Input, Output
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
1.2 Configure credential#
We are using DefaultAzureCredential to get access to workspace.
DefaultAzureCredential should be capable of handling most Azure SDK authentication scenarios.
Reference for more available credentials if it does not work for you: configure credential example, azure-identity reference doc.
try:
credential = DefaultAzureCredential()
# Check if given credential can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential not work
credential = InteractiveBrowserCredential()
1.3 Get a handle to the workspace#
We use ‘config file’ to connect to your workspace. Check this notebook to get your config file from Azure ML workspace portal and paste it into this folder. Then if you pass the next code block, you’ve all set for the environment.
# Get a handle to workspace
ml_client = MLClient.from_config(credential=credential)
# Retrieve an already attached Azure Machine Learning Compute.
cluster_name = "cpu-cluster"
print(ml_client.compute.get(cluster_name))
2. Load flow as component#
If you’ve already authored a flow using the Promptflow SDK or portal, you can locate the flow.dag.yaml file within the flow folder. This YAML specification is essential for loading your flow into an Azure ML component.
REMARK: To use
load_componentfunction with flow.dag.yaml, please ensure the following:
The
$schemashould be defined in target DAG yaml file. For example:$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Flow.schema.json.Flow metadata must be generated and kept up-to-date by verifying the file ‘
/.promptflow/flow.tools.json’. If it doesn’t exist, run the following command to generate and update it: pf flow validate --source <my-flow-directory>.
flow_component = load_component("../../flows/standard/web-classification/flow.dag.yaml")
When using the load_component function and the flow YAML specification, your flow is automatically transformed into a parallel component. This parallel component is designed for large-scale, offline, parallelized processing with efficiency and resilience. Here are some key features of this auto-converted component:
Pre-defined input and output ports:
port name |
type |
description |
|---|---|---|
data |
uri_folder or uri_file |
Accepts batch data input to your flow. You can use either the |
flow_outputs |
uri_file |
Generates a single output file named parallel_run_step.jsonl. Each line in this data file corresponds to a JSON object representing the flow returns, along with an additional column called line_number indicating its position from the original file. |
debug_info |
uri_folder |
If you run your flow component in debug mode, this port provides debugging information for each run of your lines. E.g. intermediate outputs between steps, or LLM response and token usage. |
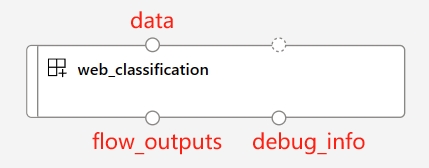
NOTE:
flow_outputsanddebug_infooutputs are required to be setmountmode as the output mode when you run pf component with multiple nodes.
Auto-generated parameters
These parameters represent all your flow inputs and connections associated with your flow steps. You can set default values in the flow/run definition, and they can be further customized during job submission. Use ‘web-classification’ sample flow for example, this flow has only one input named ‘url’ and 2 LLM steps ‘summarize_text_content’ and ‘classify_with_llm’. The input parameters of this flow component are:
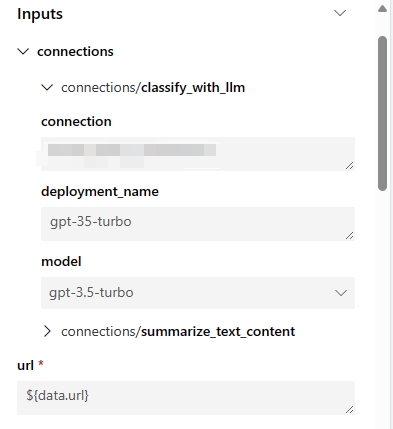
Auto-generated environment
The environment of the created component will be inherited by latest promptflow runtime image. User can include custom packages in the environment by specifying the
environmentattribute inflow.dag.yaml, along with a ‘requirements.txt’ file located under the same flow folder:... environment: python_requirements_txt: requirements.txt
3. Build your pipeline#
3.1 Declare input and output#
To supply your pipeline with data, you need to declare an input using the path, type, and mode properties. Please note: mount is the default and suggested mode for your file or folder data input.
Declaring the pipeline output is optional. However, if you require a customized output path in the cloud, you can follow the example below to set the path on the datastore. For more detailed information on valid path values, refer to this documentation - manage pipeline inputs outputs.
data_input = Input(
path="../../flows/standard/web-classification/data.jsonl",
type=AssetTypes.URI_FILE,
mode="mount",
)
pipeline_output = Output(
# Provide custom flow output file path if needed
# path="azureml://datastores/<data_store_name>/paths/<path>",
type=AssetTypes.URI_FOLDER,
# rw_mount is suggested for flow output
mode="rw_mount",
)
3.2.1 Run pipeline with single flow component#
Since all Promptflow components are based on Azure ML parallel components, users can leverage specific run settings to control the parallelization of flow runs. Below are some useful settings:
run settings |
description |
allowed values |
default value |
|---|---|---|---|
PF_INPUT_FORMAT |
When utilizing |
json, jsonl, csv, tsv |
jsonl |
compute |
Defines which compute cluster from your Azure ML workspace will be used for this job. |
||
instance_count |
Define how many nodes from your compute cluster will be assigned to this job. |
from 1 to node count of compute cluster. |
1 |
max_concurrency_per_instance |
Defines how many dedicated processors will run the flow in parallel on 1 node. When combined with the ‘instance_count’ setting, the total parallelization of your flow will be instance_count*max_concurrency_per_instance. |
>1 |
1 |
mini_batch_size |
Define the number of lines for each mini-batches. A mini-batch is the basic granularity for processing full data with parallelization. Each worker processor handles one mini-batch at a time, and all workers work in parallel across different nodes. |
> 0 |
1 |
max_retries |
Defines the retry count if any mini-batch encounters an inner exception. Remark: The retry granularity is based on mini-batches. For instance, with the previous setting, you can set 100 lines per mini-batch. When one line execution encounters a transient issue or an unhandled exception, these 100 lines will be retried together, even if the remaining 99 lines are successful. Additionally, LLM responses with status code 429 will be handled internally for flow runs in most cases and will not trigger mini-batch failure. |
>= 0 |
3 |
error_threshold |
Defines how many failed lines are acceptable. If the count of failed lines exceeds this threshold, the job will be stopped and marked as failed. Set ‘-1’ to disable this failure check. |
-1 or >=0 |
-1 |
mini_batch_error_threshold |
Defines the maximum number of failed mini-batches that can be tolerated after all retries. Set ‘-1’ to disable this failure check. |
-1 or >=0 |
-1 |
logging_level |
Determines how parallel jobs save logs to disk. Setting to ‘DEBUG’ for the flow component allows the component to output intermediate flow logs into the ‘debug_info’ port. |
INFO, WARNING, DEBUG |
INFO |
timeout |
Sets the timeout checker for each mini-batch execution in milliseconds. If a mini-batch runs longer than this threshold, it will be marked as failed and trigger the next retry. Consider setting a higher value based on your mini-batch size and total traffic throughput for your LLM endpoints. |
> 0 |
600 |
# Define the pipeline as a function
@pipeline()
def pipeline_func_with_flow(
# Function inputs will be treated as pipeline input data or parameters.
# Pipeline input could be linked to step inputs to pass data between steps.
# Users are not required to define pipeline inputs.
# With pipeline inputs, user can provide the different data or values when they trigger different pipeline runs.
pipeline_input_data: Input,
parallel_node_count: int = 1,
):
# Declare pipeline step 'flow_node' by using flow component
flow_node = flow_component(
# Bind the pipeline intput data to the port 'data' of the flow component
# If you don't have pipeline input, you can directly pass the 'data_input' object to the 'data'
# But with this approach, you can't provide different data when you trigger different pipeline runs.
# data=data_input,
data=pipeline_input_data,
# Declare which column of input data should be mapped to flow input
# the value pattern follows ${data.<column_name_from_data_input>}
url="${data.url}",
# Provide the connection values of the flow component
# The value of connection and deployment_name should align with your workspace connection settings.
connections={
"summarize_text_content": {
"connection": "azure_open_ai_connection",
"deployment_name": "gpt-35-turbo",
},
"classify_with_llm": {
"connection": "azure_open_ai_connection",
"deployment_name": "gpt-35-turbo",
},
},
)
# Provide run settings of your flow component
# Only 'compute' is required and other setting will keep default value if not provided.
flow_node.environment_variables = {
"PF_INPUT_FORMAT": "jsonl",
}
flow_node.compute = "cpu-cluster"
flow_node.resources = {"instance_count": parallel_node_count}
flow_node.mini_batch_size = 5
flow_node.max_concurrency_per_instance = 2
flow_node.retry_settings = {
"max_retries": 1,
"timeout": 1200,
}
flow_node.error_threshold = -1
flow_node.mini_batch_error_threshold = -1
flow_node.logging_level = "DEBUG"
# Function return will be treated as pipeline output. This is not required.
return {"flow_result_folder": flow_node.outputs.flow_outputs}
# create pipeline instance
pipeline_job_def = pipeline_func_with_flow(pipeline_input_data=data_input)
pipeline_job_def.outputs.flow_result_folder = pipeline_output
Submit the pipeline job to your workspace then check the status of your job on UI through the link in the output.
# Submit the pipeline job to your workspace
pipeline_job_run = ml_client.jobs.create_or_update(
pipeline_job_def, experiment_name="Single_flow_component_pipeline_job"
)
pipeline_job_run
ml_client.jobs.stream(pipeline_job_run.name)
NOTE:
The choice of
mini_batch_sizesignificantly affects the efficiency of the flow job. Since the lines within each mini-batch run sequentially, setting a higher value for this parameter increases the chunk size, which reduces parallelization. On the other hand, larger batch sizes also raise the cost of retries, as retries are based on the entire mini-batch. Conversely, opting for the lowest value (e.g., mini_batch_size=1) may introduce additional overhead, affecting efficiency across multiple mini-batches during orchestration or result summarization. So it is recommended to start with a value between 10 and 100 and fine-tune it later based on your specific requirements.The
max_concurrency_per_instancesetting can significantly enhance parallel efficiency within a single compute node. However, it also introduces several potential issues: 1) increase the risk of running out of memory, 2) LLM endpoint may experience throttling when too many requests arrive simultaneously. In general, it is advisable to set the max_concurrency_per_instance number equal to the core count of your compute to strike a balance between parallelism and resource constraints.
3.2.2 Run complex pipeline with multiple component#
In a typical pipeline, you’ll find multiple steps that encompass all your offline business requirements. If you’re aiming to construct a more intricate pipeline for production, explore the following resources:
Various component types:
Additionally, consider the following sample code that loads two extra command components from a repository to construct a single offline pipeline:
data_prep_component : This dummy data preprocessing step performs simple data sampling.
result_parser_component: Combining source data, flow results, and debugging output, it generates a single file containing origin queries, LLM predictions, and LLM token usages.
# load Azure ML components
data_prep_component = load_component("./components/data-prep/data-prep.yaml")
result_parser_component = load_component(
"./components/result-parser/result-parser.yaml"
)
# load flow as component
flow_component = load_component("../../flows/standard/web-classification/flow.dag.yaml")
@pipeline()
def pipeline_func_with_flow(pipeline_input_data):
data_prep_node = data_prep_component(
input_data_file=pipeline_input_data,
)
data_prep_node.compute = "cpu-cluster"
flow_node = flow_component(
# Feed the output of data_prep_node to the flow component
data=data_prep_node.outputs.output_data_folder,
url="${data.url}",
connections={
"summarize_text_content": {
"connection": "azure_open_ai_connection",
"deployment_name": "gpt-35-turbo",
},
"classify_with_llm": {
"connection": "azure_open_ai_connection",
"deployment_name": "gpt-35-turbo",
},
},
)
flow_node.environment_variables = {"PF_INPUT_FORMAT": "csv"}
flow_node.compute = "cpu-cluster"
flow_node.mini_batch_size = 5
flow_node.max_concurrency_per_instance = 2
flow_node.resources = {"instance_count": 1}
flow_node.logging_level = "DEBUG"
# set output mode to 'mount'
# This is required for the flow component when the 'instance_count' is set higher than 1
flow_node.outputs.flow_outputs.mode = "mount"
flow_node.outputs.debug_info.mode = "mount"
result_parser_node = result_parser_component(
source_data=data_prep_node.outputs.output_data_folder,
pf_output_data=flow_node.outputs.flow_outputs,
pf_debug_data=flow_node.outputs.debug_info,
)
flow_node.retry_settings = {
"max_retries": 1,
"timeout": 6000,
}
result_parser_node.compute = "cpu-cluster"
return {"flow_result_folder": result_parser_node.outputs.merged_data}
# create pipeline instance
pipeline_job_def = pipeline_func_with_flow(pipeline_input_data=data_input)
pipeline_job_def.outputs.flow_result_folder = pipeline_output
Submit the pipeline job to your workspace then check the status of your job on UI through the link in the output.
# submit job to workspace
pipeline_job_run = ml_client.jobs.create_or_update(
pipeline_job_def, experiment_name="Complex_flow_component_pipeline_job"
)
pipeline_job_run
ml_client.jobs.stream(pipeline_job_run.name)
4 Next steps#
4.1 Next step - Setup scheduler for your pipeline#
Azure Machine Learning pipelines support native scheduler to help users regularly run their pipeline jobs with predefined time triggers. Here’s a code example for setting up a scheduler on a newly created pipeline using the flow component.
Let’s begin by declaring a scheduler with a customized recurrence pattern.
from datetime import datetime
from azure.ai.ml.entities import JobSchedule, RecurrenceTrigger, RecurrencePattern
from azure.ai.ml.constants import TimeZone
schedule_name = "simple_sdk_create_schedule_recurrence"
schedule_start_time = datetime.utcnow()
recurrence_trigger = RecurrenceTrigger(
frequency="day", # could accept "hour", "minute", "day", "week", "month"
interval=1,
schedule=RecurrencePattern(hours=10, minutes=[0, 1]),
start_time=schedule_start_time,
time_zone=TimeZone.UTC,
)
job_schedule = JobSchedule(
name=schedule_name,
trigger=recurrence_trigger,
# Declare the pipeline job to be scheduled. Here we uses the pipeline job created in previous example.
create_job=pipeline_job_def,
)
To initiate the scheduler, follow this example:
job_schedule = ml_client.schedules.begin_create_or_update(
schedule=job_schedule
).result()
print(job_schedule)
To review all your scheduled jobs, navigate to the Job List page within the Azure Machine Learning workspace UI. Any job triggered by the scheduler will have a display name following this format: <schedule_name>-<trigger_time>. For instance, if you have a schedule named “named-schedule”, a job triggered on January 1, 2021, at 06:00:00 UTC will have the display name “named-schedule-20210101T060000Z”.
To disable or shut down a running scheduler, follow this example:
job_schedule = ml_client.schedules.begin_disable(name=schedule_name).result()
job_schedule.is_enabled
To explore further details about scheduling Azure Machine Learning pipeline jobs, visit this article on how to schedule pipeline job
4.2 Next step - Deploy pipeline to an endpoint#
Azure Machine Learning also offers batch endpoints, which enable you to deploy pipelines to an endpoint for efficient operationalization. If you require scheduling for your flow pipeline using an external orchestrator, such as Azure Data Factory or Microsoft Fabric, utilizing batch endpoints is the optimal recommendation for your flow pipeline.
Let’s start by creating a new batch endpoint in your workspace.
from azure.ai.ml.entities import BatchEndpoint, PipelineComponentBatchDeployment
# from azure.ai.ml.entities import ModelBatchDeployment, ModelBatchDeploymentSettings, Model, AmlCompute, Data, BatchRetrySettings, CodeConfiguration, Environment, Data
# from azure.ai.ml.constants import BatchDeploymentOutputAction
endpoint_name = "hello-my-pipeline-endpoint"
endpoint = BatchEndpoint(
name=endpoint_name,
description="A hello world endpoint for pipeline",
)
ml_client.batch_endpoints.begin_create_or_update(endpoint).result()
Each endpoint can support multiple deployments, each associated with distinct pipelines. In this context, we initiate a new deployment using our flow pipeline job, targeting the recently established endpoint.
deployment = PipelineComponentBatchDeployment(
name="my-pipeline-deployment",
description="A hello world deployment with a pipeline job.",
endpoint_name=endpoint.name,
# Make sure 'pipeline_job_run' run successfully before deploying the endpoint
job_definition=pipeline_job_run,
settings={"default_compute": "cpu-cluster", "continue_on_step_failure": False},
)
ml_client.batch_deployments.begin_create_or_update(deployment).result()
# Refresh the default deployment to the latest one at our endpoint.
endpoint = ml_client.batch_endpoints.get(endpoint.name)
endpoint.defaults.deployment_name = deployment.name
ml_client.batch_endpoints.begin_create_or_update(endpoint).result()
Invoke the default deployment to target endpoint with proper data:
batch_endpoint_job = ml_client.batch_endpoints.invoke(
endpoint_name=endpoint.name,
inputs={"pipeline_input_data": data_input},
)
Finally, verify the invocation on the workspace UI using the following link:
ml_client.jobs.get(batch_endpoint_job.name)
To explore further details about Azure Machine Learning batch endpoint, visit this article on how-to-use-batch-pipeline-deployments