Tracing with LLM application#
Authored by: 
Tracing is a powerful tool for understanding the behavior of your LLM application, prompt flow tracing capability supports instrumentation for such scenario.
This notebook will demonstrate how to use prompt flow to instrument and understand your LLM application.
Learning Objective - Upon completion of this notebook, you will be able to:
Trace LLM application and visualize with prompt flow.
Requirements#
To run this notebook example, please install required dependencies.
%%capture --no-stderr
%pip install -r ./requirements.txt
Please configure your API key using an .env file, we have provided an example .env.example for reference.
# load api key and endpoint from .env to environ
from dotenv import load_dotenv
load_dotenv()
Create your LLM application#
This notebook example will build a LLM application with Azure OpenAI service.
from openai import AzureOpenAI
# in this notebook example, we will use model "gpt-35-turbo-16k"
deployment_name = "gpt-35-turbo-16k"
client = AzureOpenAI(
azure_deployment=deployment_name,
api_version="2024-02-01",
)
# prepare one classic question for LLM
conversation = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the meaning of life?"},
]
response = client.chat.completions.create(
messages=conversation,
model=deployment_name,
)
print(response.choices[0].message.content)
Start trace using promptflow.tracing.start_trace to leverage prompt flow tracing capability; this will print a link to trace UI, where you can visualize the trace.
from promptflow.tracing import start_trace
# start a trace session, and print a url for user to check trace
start_trace(collection="trace-llm")
Run the LLM application again, and you should be able to see new trace logged in the trace UI, and it is clickable to see more details.
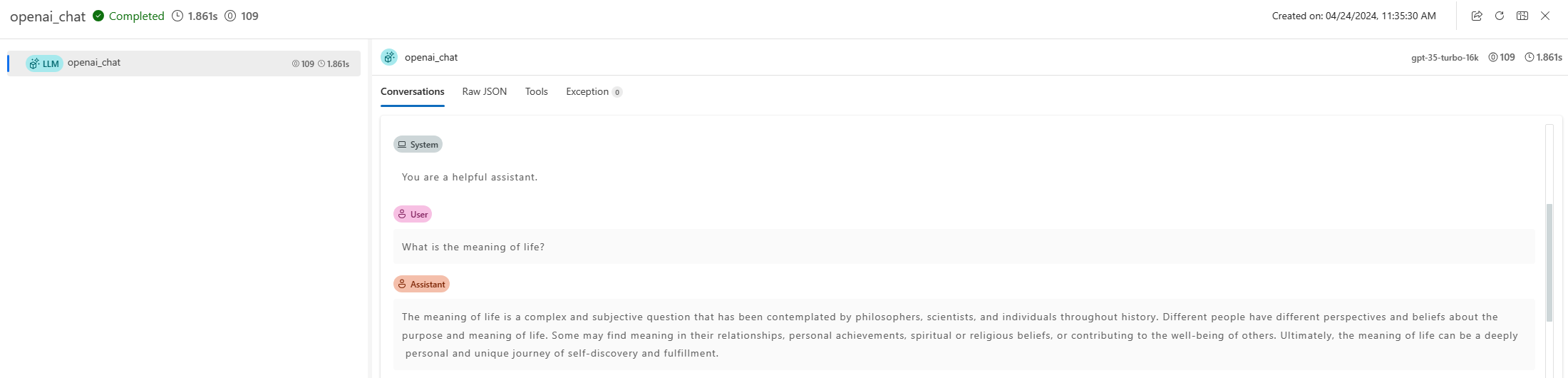
response = client.chat.completions.create(
messages=conversation,
model=deployment_name,
)
print(response.choices[0].message.content)
Next Steps#
By now you have successfully tracing your LLM application with prompt flow.
You can check out more examples:
Trace LangChain: tracing
LangChainand visualize leveraging prompt flow.Trace AutoGen: tracing
AutoGenand visualize leveraging prompt flow.Trace your flow: using promptflow @trace to structurally tracing your app and do evaluation on it with batch run.