Responsible AI Mitigations Library
The goal of responsible AI is to create trustworthy AI systems that benefit people while mitigating harms, which can occur when AI systems fail to perform with fair, reliable, or safe outputs for various stakeholders. Teams tasked with developing AI systems must work to identify, diagnose, and mitigate potential harms as much as possible. In this initial release, the Responsible AI Mitigations Library helps AI practitioners explore different mitigation steps that may be most appropriate when the model underperforms for a given cohort. The library currently has three modules:
DataProcessing: offers mitigation techniques for improving model performance for specific cohorts.
DataBalanceAnalysis: provides metrics for diagnosing errors that originate from data imbalance either on class labels or feature values.
Cohort: provides classes for handling and managing cohorts, which allows the creation of custom pipelines for each cohort in an easy and intuitive interface. The module also provides techniques for learning different decoupled estimators (models) for different cohorts and combining them in a way that optimizes different definitions of group fairness.
Exploring potential mitigations
The Responsible AI Mitigations Library brings together in one interface and compatible end-to-end data-processing pipelines a series of well-known machine learning techniques (based on popular implementations in scikit-learn, mlxtend, sdv, among others) that have been adapted to help AI practitioners target problems after they have identified model errors using diagnostic tools such as those in the Responsible AI Toolbox. See more about how this library works with the Responsible AI Toolbox.
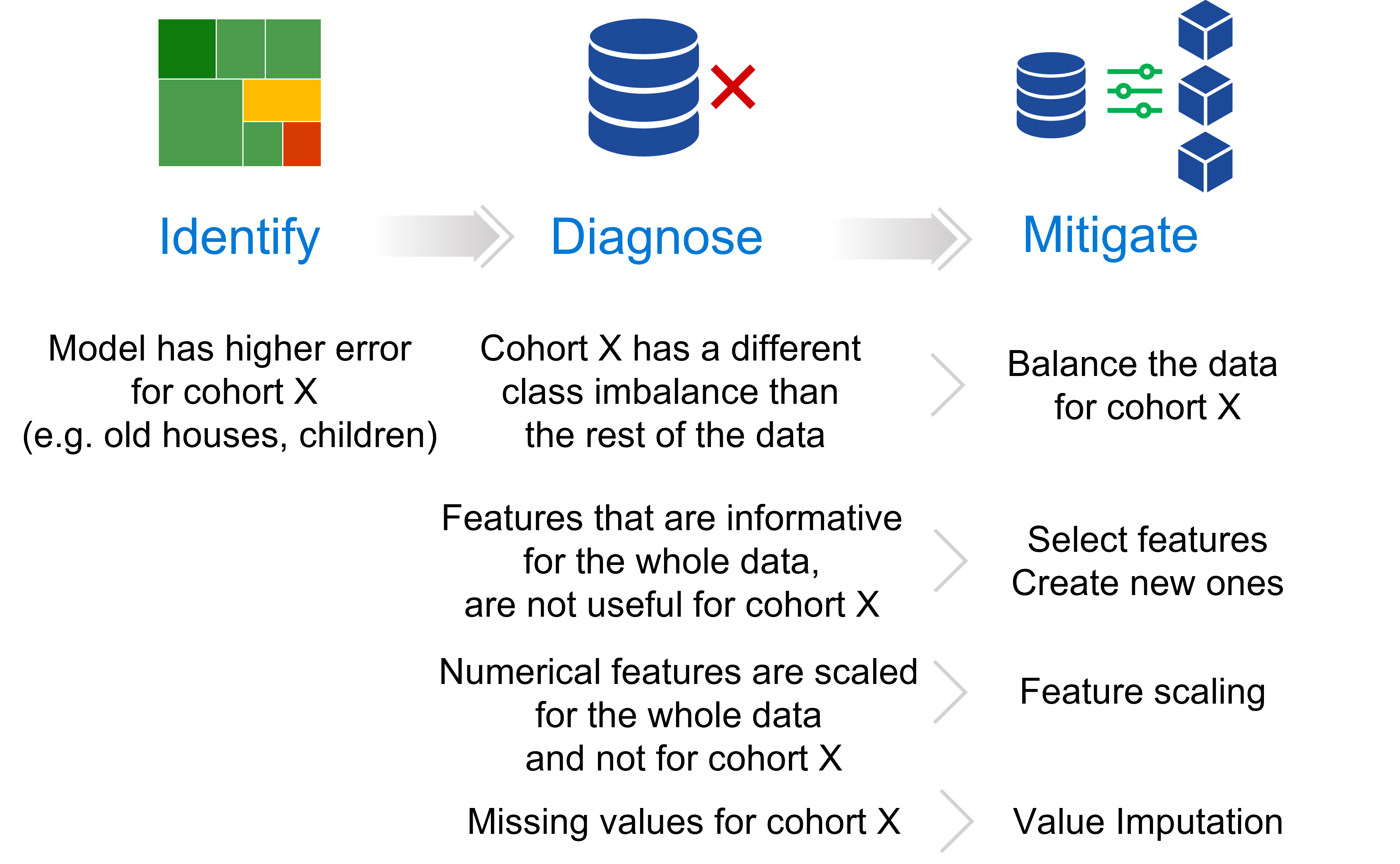
Figure 1 - The targeted approach to responsible AI mitigations focuses the mitigation process on previously identified and diagnosed failure modes.
After you’ve identified a model as underperforming for a specific cohort, the Responsible AI Mitigations Library can help inform your decisions for appropriate mitigation. The library enables you to explore potential mitigations for targeted cohorts and sub-cohorts through:
Balancing and synthesizing data.
Selecting or creating features with different encodings.
Scaling numerical features.
Imputing missing values.
Note: Although the Responsible AI Mitigations Library currently focuses on data problems, it will expand over time to include mitigations for model errors, through customized loss functions, architectures, and new training algorithms.
Terminology Note
The words “transformations” and “mitigations” are used interchangeably here, and both refer to an operation that changes the original dataset, with the goal of mitigating some issue in the data. We also use the words “estimator” and “model” interchangeably, where both words refer to the object that is trained over a dataset and then can be used to make predictions over new data.
Benefits of targeted error mitigations
Traditional methods of improving model performance often take a blanket approach, aiming at maximizing a single-score performance number, such as overall accuracy. Blanket approaches may involve increasing the size of training data or model architecture—approaches that are not only costly but also ineffective for improving the model in areas of poorest performance.
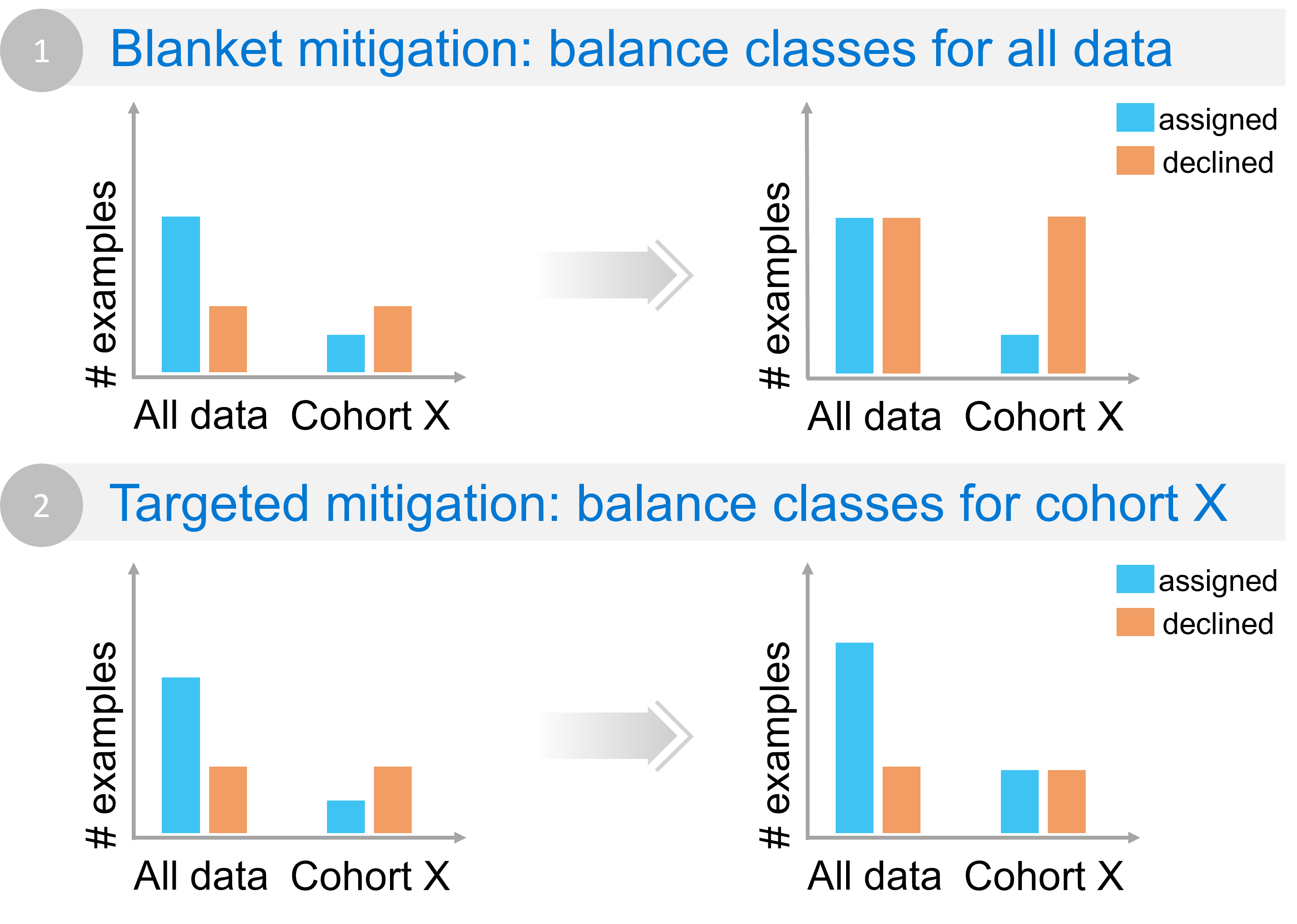
Figure 2 - Example of how blanket approaches may not help in mitigating the underlying issue for a given cohort (in this case flipped class imbalance).
Imagine the following example. A model that predicts customer credit reliability is underperforming for a given cohort X. When analyzing class balance for the data, it becomes clear that overall there are more examples in the data for which a loan has been assigned. However, for the cohort of interest X, this distribution looks very different with more examples of loans being declined. The discrepancy also leads to a higher error for this cohort as the model learns to over-decline. Merely adding more data to adjust overall class imbalance (Scenario 1 in the figure) will not address class imbalance for cohort X. In fact, it might make it worse by accentuating class imbalance for this cohort and declining more loans. A more targeted approach (Scenario 2 in the figure) would focus the class balance mitigation only on cohort X by sampling or synthesizing more data within that cohort where loans have been assigned. The Responsible AI Mitigations library can implement the second scenario using two approaches:
Use the dataprocessing.Rebalance together with the cohort.CohortManager in order to apply a over-sampling over only a set of cohorts (check the
CohortManager’s Examples section to see how this can be achieved).Synthesizing data only for a given cohort (see the dataprocessing.Synthesizer class for more information);
This way, the Responsible AI Mitigations Library offers a targeted approach that lets you save time and resources by:
Improving your understanding of model failures by zeroing in on:
A set of features in the dataset, allowing changing format or encoding only the features that are problematic.
A sub-cohort only, not touching any other data.
Simplifying the implementation and customization of mitigations for specific data problems by providing mitigations that are compatible with each other and can be combined into a single pipeline. Most functionalities to this end can be found in the cohort.CohortManager class.
Enabling custom training of cohort-specific models and post-training classifier mitigations that search and optimize different definitions of group fairness. Most functionalities to this end can be found in the cohort.CohortManager and cohort.DecoupledClass class.
There are multiple ways of using the cohort.CohortManager class when building a pipeline, and these different scenarios are summarized in following figure.
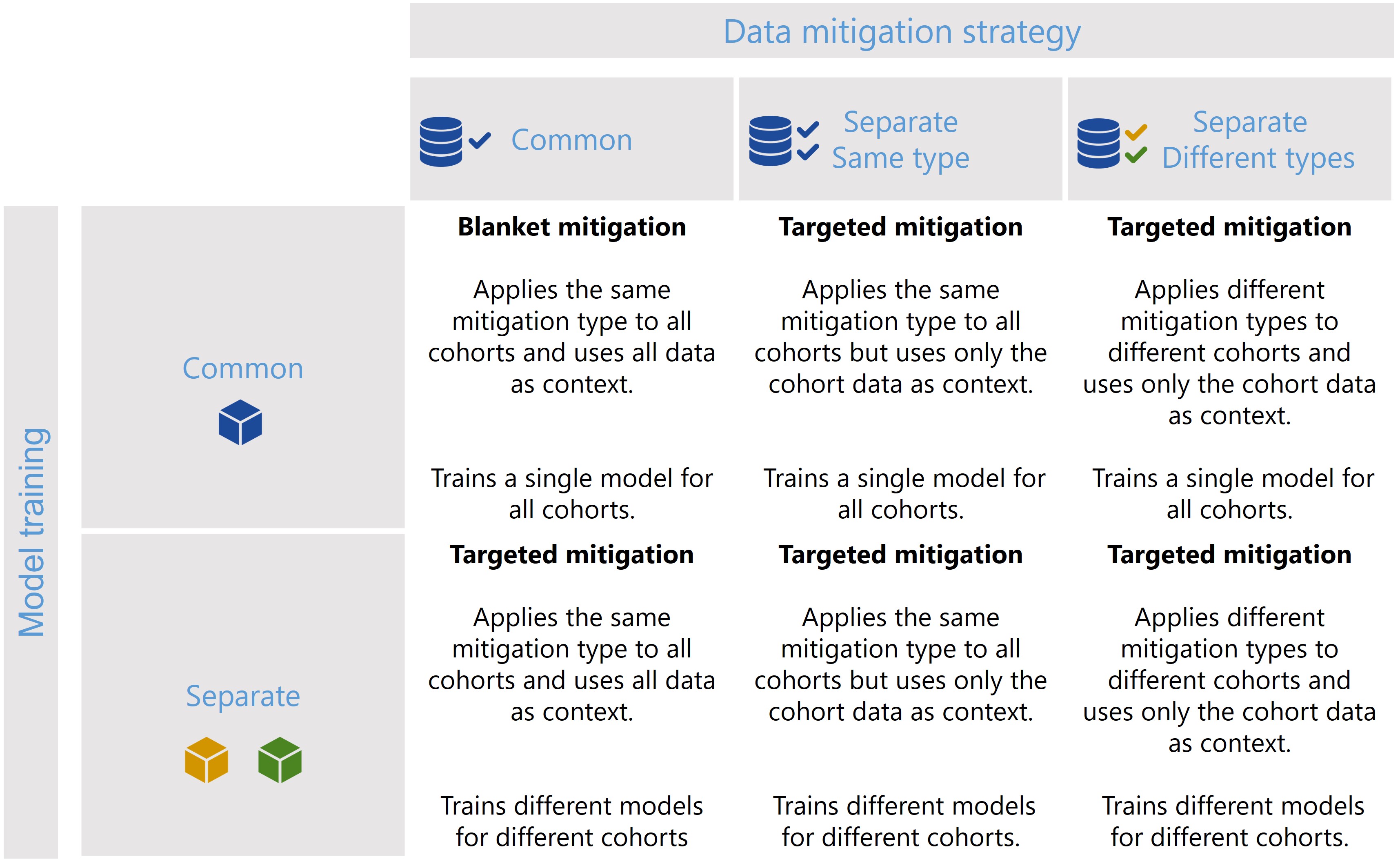
Figure 3 - The CohortManager class can be used in different ways to target mitigations to different cohorts. The main differences between these scenarios consist on whether the same or different type of data mitigation is applied to the cohort data, and whether a single or separate models will be trained for different cohorts. Depending on these choices, CohortManager will take care of slicing the data accordingly, applying the specified data mitigation strategy, merging the data back, and retraining the model(s).
The Cohort Manager - Scenarios and Examples notebook, located in notebooks/cohort/cohort_manager_scenarios.ipynb, shows how each of these
scenarios can be implemented through simple code snippets.
Three modules for targeted error mitigation
The Responsible AI Mitigations Library consists of three modules that work in complement for targeting and mitigating data problems: DataProcessing and DataBalanceAnalysis.
DataProcessing
A set of data-oriented mitigation steps for data balancing, scaling, missing value imputation, sampling, and encoding, using proven machine learning mitigation techniques in a single interface and compatible environment. The goal of this module is to provide a unified interface for different mitigation methods scattered around multiple machine learning libraries, such as scikit-learn, mlxtend, sdv, and others.
Highlights include:
A simple interface for mitigation steps that follows the
.fit()and.transform()convention.transformer classes that can be combined together in end-to-end mitigation pipelines.
Function calls adapted for responsible AI by extending existing calls either with target features or cohorts.
Predetermined parameter values, eliminating the need to know or to configure all available parameters.
Unique solutions for tabular data.
Automation of various mitigation steps, with some transformer classes acting as a wrapper to others in the library.
Customization options, helpful for the more experienced AI practitioner.
DataBalanceAnalysis
A set of metrics for diagnosing and measuring data imbalance. This module is intended to be used as part of the error diagnosis process for failure modes that are due to class or feature imbalance. After measuring with DataBalanceAnalysis, AI practitioners can then work to mitigate the failure through techniques available in the library’s DataProcessing module.
Example
A model trained for house-price prediction is discovered to be underperforming for houses that do not have an attached garage. The AI practitioner determines that this failure is due to the underrepresentation of houses with no garage in the training data. The practitioner can use metrics in the DataBalanceAnalysis module to measure the feature imbalance (“garage” vs. “no garage”), then work to mitigate the issue by using one of the sampling techniques available in the library’s DataProcessing module for augmenting data.
Cohort
A sub-module that implements classes capable of handling and managing cohorts. This makes it easier for applying targeted mitigations over a specific cohort, or creating custom data processing pipelines for each cohort. The Cohort sub-module even allows creating different estimators for each cohort, without the user having to explicitly manage multiple models. All is done internally in the class, with a unified and simple interface.
Highlights include:
Interface for breaking a dataset into multiple cohorts.
Two approaches for defining cohorts: based on the different values of a column, or based on custom filters.
Creation of custom pipelines for each cohort, allowing the creation of different estimators for each cohort. Possibility to search and combine the custom estimators for each cohort such that jointly they optimize a group fairness definition of choice.
Mitigating cases with low representation data for minority cohorts through transfer learning.
Simple interface, which also implements the
.fit(),.transform(),.predict(),.predict_proba(), and.fit_resample()methods (some of these methods will only be available depending on the transformations/estimators in the custom pipelines defined for each cohort).
Example
Consider a dataset of a classification problem that has a sensitive feature (country for example), and that each country-based cohort behaves differently, in the sense
that the classification logic may be different between cohorts, or that some other feature values may be considerably different ranges and interpretations across cohorts.
Depending on the estimator being used, these behavioral differences might not be captured, and in the end, the estimator
will simply try to understand the majority cohort, achieving good results for that cohort at the cost of achieving inferior results for the remaining ones. One way
to approach this problem is to apply targeted mitigations over each cohort separately. Some examples include using dataprocessing.DataStandardScaler
over each cohort separately (e.g. for features like grades that have a different range in different countries), or even training a separate estimator for each cohort
(e.g. if some features are more or less relevant for some cohorts). This can all be achieved through the cohort.CohortManager class.
Check-out these examples for more details on how to use the cohort.CohortManager to create customized pipelines (including
an estimator for each cohort).
Overview