QuickStart#
In this Notebook we run Archai’s Quickstart example on Azure Machine Learning.
Prerequisites#
Python 3.7 or later
An Azure subscription
An Azure Resource Group
An Azure Machine Learning Workspace
This notebook also assumes you have a python environment setup using pip install -e .[aml] in your Archai repository root
[2]:
from pathlib import Path
from IPython.display import display, Image
from IPython.core.display import HTML
from azure.ai.ml import Output, command
import archai.common.azureml_helper as aml_helper
import archai.common.notebook_helper as nb_helper
Get a handle to the workspace#
We load the workspace from a workspace configuration file.
[ ]:
ml_client = aml_helper.get_aml_client_from_file("../.azureml/config.json")
print(f'Using workspace: {ml_client.workspace_name} in resource group: {ml_client.resource_group_name}')
Create a compute cluster#
We provision a Linux compute cluster for this Notebook. See the full list on VM sizes and prices.
[3]:
cpu_compute_name = "nas-cpu-cluster-D14-v2"
compute_cluster = aml_helper.create_compute_cluster(ml_client, cpu_compute_name)
You already have a cluster named nas-cpu-cluster-D14-v2, we'll reuse it as is.
Create an environment based on a YAML file#
Azure Machine Learning maintains a set of CPU and GPU Ubuntu Linux-based base images with common system dependencies. For the set of base images and their corresponding Dockerfiles, see the AzureML Containers repo.
[4]:
archai_job_env = aml_helper.create_environment_from_file(ml_client,
image="mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:latest",
conda_file="conda.yaml",
version="0.0.1")
Environment with name aml-archai is registered to workspace, the environment version is 0.0.1
Create job#
[5]:
job = command(experiment_name="archai_quickstart",
display_name="Archai's QuickStart",
compute=cpu_compute_name,
environment=f"{archai_job_env.name}:{archai_job_env.version}",
code="main.py",
outputs=dict(
output_path=Output(type="uri_folder", mode="rw_mount")
),
command="python main.py --output_dir ${{outputs.output_path}}"
)
Run job#
[6]:
quickstart_job = ml_client.create_or_update(job)
Uploading main.py (< 1 MB): 100%|##########| 1.74k/1.74k [00:00<00:00, 6.91kB/s]
Open the job overview on Azure ML Studio in your web browser (this works when you are running this notebook in VS code).
[7]:
import webbrowser
webbrowser.open(quickstart_job.services["Studio"].endpoint)
job_name = quickstart_job.name
print(f'Started job: {job_name}')
Started job: busy_shampoo_cqjgwy28gc
Download job’s output#
[ ]:
output_name = "output_path"
download_path = "output"
aml_helper.download_job_output(ml_client, job_name=quickstart_job.name, output_name=output_name, download_path=download_path)
downloaded_folder = Path(download_path) / "named-outputs" / output_name
Show Pareto Frontiers#
[9]:
param_vs_latency_img = Image(filename=downloaded_folder / "pareto_non_embedding_params_vs_onnx_latency.png")
display(param_vs_latency_img)
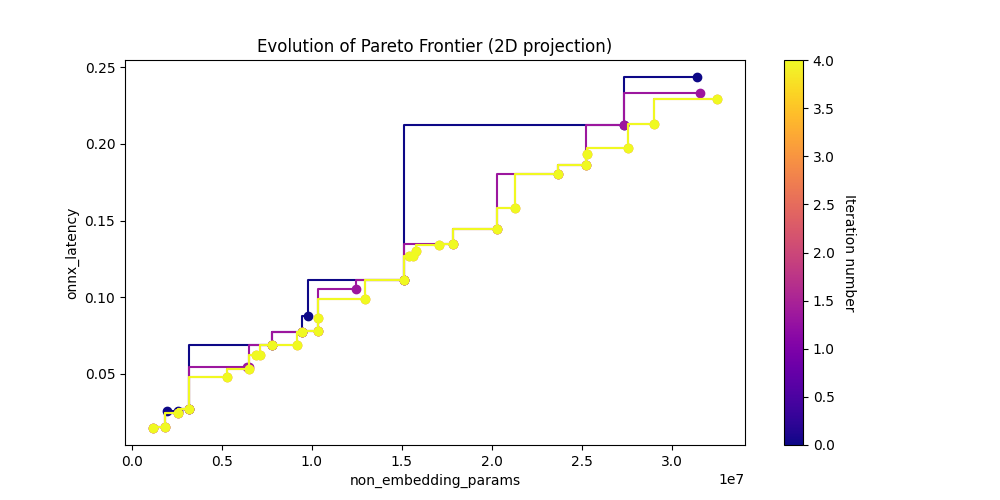
[10]:
param_vs_memory_img = Image(filename=downloaded_folder / "pareto_non_embedding_params_vs_onnx_memory.png")
display(param_vs_memory_img)
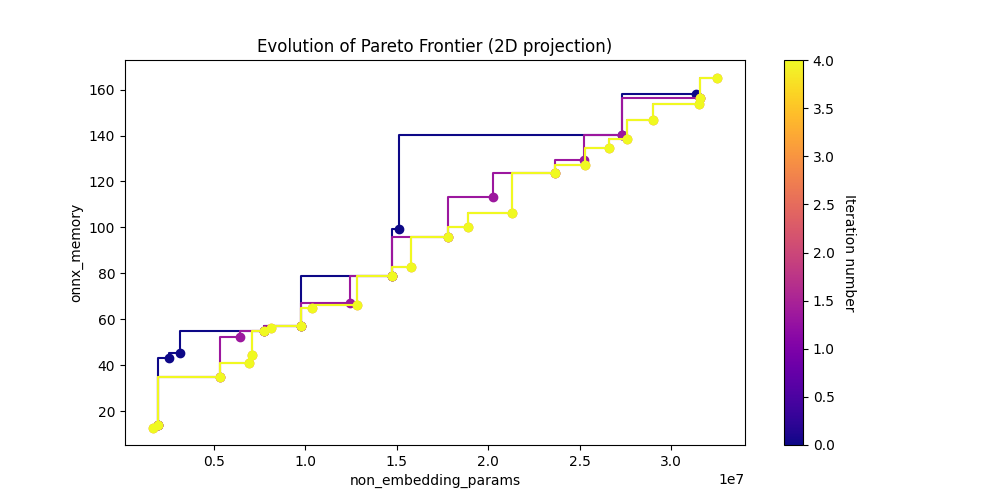
[11]:
latency_vs_memory_img = Image(filename=downloaded_folder / "pareto_onnx_latency_vs_onnx_memory.png")
display(latency_vs_memory_img)
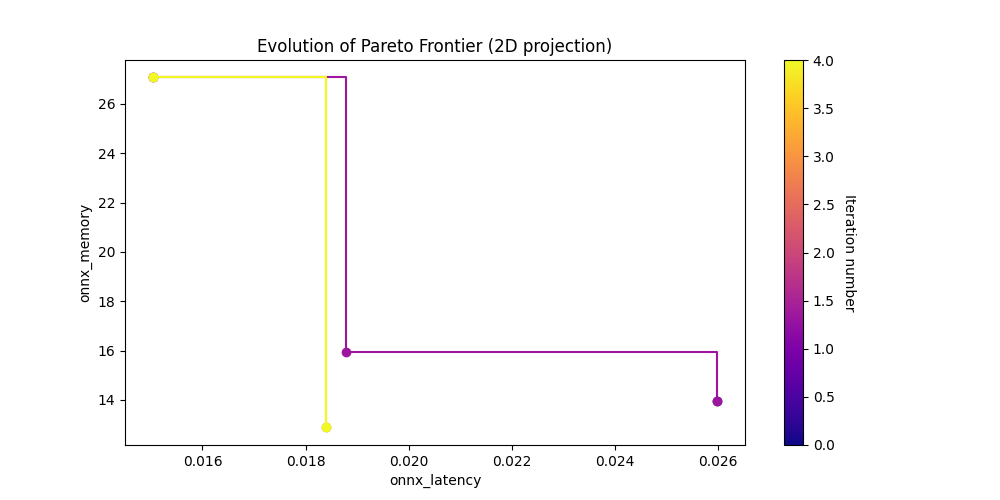
Show search state of the last iteration#
[11]:
df = nb_helper.get_search_csv(downloaded_folder)
df = df[['archid', 'non_embedding_params', 'onnx_latency', 'onnx_memory', 'is_pareto']]
df[(df['onnx_latency'] < 0.1) & (df['is_pareto'] == True)]
[11]:
| archid | non_embedding_params | onnx_latency | onnx_memory | is_pareto | |
|---|---|---|---|---|---|
| 1 | gpt2_2ce523ffef6587e0a9790c173a89d6fd25f1b9b6 | 7769472.0 | 0.068997 | 54.867023 | True |
| 5 | gpt2_e24cd64a53d6a9be4a5cf2116daee38e0763947c | 9791616.0 | 0.087752 | 57.236445 | True |
| 7 | gpt2_ad522de7b54d7ad73231ccab52e7f8b17c444dd8 | 3154688.0 | 0.027303 | 45.336156 | True |
| 8 | gpt2_3b76e4046ead432cab16d17d0a3d500efc0249c5 | 1963840.0 | 0.025981 | 13.966668 | True |
| 9 | gpt2_56b3029ce65d7c75585e97c67a3162b6b34fd453 | 9462656.0 | 0.077058 | 61.318761 | True |
| 12 | gpt2_af14be0b4e8f8a29e744cd81c503419200e05c3a | 2564480.0 | 0.024791 | 43.084689 | True |
| 13 | gpt2_08a67612ee38cccd05c47a45e137a8e82921c3c0 | 5356160.0 | 0.055600 | 34.976172 | True |
| 15 | gpt2_1638d1cbba003004298c9f1fec1885e1c3e724ac | 1841408.0 | 0.015650 | 29.566623 | True |
| 17 | gpt2_a9736f6b29e56c1026b452ede20adc7b9f488ada | 10346304.0 | 0.077892 | 72.751252 | True |
| 19 | gpt2_35dc3c85cfeb893d23399a0d0c087ae53f718323 | 1782528.0 | 0.018778 | 15.950404 | True |
| 23 | gpt2_49d99f06ad70afece175610b82e4b9f69a367d07 | 1185408.0 | 0.015044 | 27.064179 | True |
| 29 | gpt2_6dcd8caf6477c3554cefa5a9629f2778e31582e8 | 6409472.0 | 0.054197 | 52.364760 | True |
| 31 | gpt2_adcecc4a73970b5ceaf61c5a20c6e2fc914bebbf | 1683328.0 | 0.018393 | 12.884486 | True |
| 33 | gpt2_ea6fcf50e01df27f5065286f64d3d4fd086ad1f6 | 6908352.0 | 0.062050 | 40.857306 | True |
| 34 | gpt2_3df377a7c2f287c0396798d69587be4ce80eb065 | 9476096.0 | 0.082323 | 58.701959 | True |
| 35 | gpt2_5825b8567da483715267609a45897741217c7358 | 9194496.0 | 0.069051 | 73.742070 | True |
| 38 | gpt2_1b55c333a06a31b8c3f5dee0be477bff60961b27 | 7109376.0 | 0.062521 | 44.316129 | True |
| 42 | gpt2_6f1494e13898235ea0abfee60f651e972ad7c15f | 8138432.0 | 0.071064 | 56.273517 | True |
| 44 | gpt2_05bb7d11f19a7864283f4a4c48d205a71bbc0cca | 5295232.0 | 0.048272 | 61.571509 | True |
| 45 | gpt2_88d96623f6fba1aef736f1eebfde662ebd2dc91c | 10352192.0 | 0.086744 | 64.712472 | True |
| 52 | gpt2_cc745fafec97887cfbd9583cd89c276805121d14 | 8575680.0 | 0.069086 | 65.999776 | True |
| 53 | gpt2_54a4da9b9011aa8b7cabd16c81d7ec60e1fa4bec | 6503936.0 | 0.052899 | 55.414674 | True |
| 62 | gpt2_1c4ef81c171f066ea6e51256051fb83af5ce9ee3 | 12931200.0 | 0.098794 | 90.671401 | True |