Task: Text Generation#
In this Notebook we run Archai’s Text Generation task on Azure Machine Learning.
We’ll use the following components: 1. Search - Run Lightweight Transformer Search (LTS) to discover architectures that perform well with regards to non-embedding parameters, latency, and memory 2. Train - Train a chosen architecture 3. Generate text - Given a trained architecture and a prompt, outputs the generated text
The components are defined via Yaml (more info here) which will call the corresponding Python scripts.
Note: Our goal is to show how to create and run jobs without spending too much computing resources. Therefore, our goal is not to train a good model – for this purpose please refer to the original task.
Prerequisites#
Python 3.7 or later
An Azure subscription
An Azure Resource Group
An Azure Machine Learning Workspace
This notebook also assumes you have a python environment setup using pip install -e .[aml] in your Archai repository root
[1]:
import os
from pathlib import Path
from IPython.display import display, Image
from IPython.core.display import HTML
from azure.ai.ml import load_job
import archai.common.azureml_helper as aml_helper
import archai.common.notebook_helper as nb_helper
Get a handle to the workspace#
We load the workspace from a workspace configuration file.
[ ]:
ml_client = aml_helper.get_aml_client_from_file("../.azureml/config.json")
print(f'Using workspace: {ml_client.workspace_name} in resource group: {ml_client.resource_group_name}')
Create CPU and GPU compute clusters#
We provision a Linux compute cluster for the NAS job in this Notebook. See the full list on VM sizes and prices.
We also provision a GPU compute cluster, to train the architectures and generate text.
[5]:
cpu_compute_name = "nas-cpu-cluster-D14-v2"
cpu_compute_cluster = aml_helper.create_compute_cluster(ml_client, cpu_compute_name, size="Standard_D14_v2")
gpu_compute_name = "nas-gpu-cluster-NC6"
gpu_compute_cluster = aml_helper.create_compute_cluster(ml_client, gpu_compute_name, size="Standard_NC6")
You already have a cluster named nas-cpu-cluster-D14-v2, we'll reuse it as is.
You already have a cluster named nas-gpu-cluster-NC6, we'll reuse it as is.
Create an environment based on a YAML file#
Azure Machine Learning maintains a set of CPU and GPU Ubuntu Linux-based base images with common system dependencies. For the set of base images and their corresponding Dockerfiles, see the AzureML Containers repo.
[6]:
archai_job_env = aml_helper.create_environment_from_file(ml_client,
image="mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:latest",
conda_file="conda.yaml",
version="0.0.1")
Environment with name aml-archai is registered to workspace, the environment version is 0.0.1
Job 1: NAS (Searching for Pareto-optimal Architectures)#
Load the search job from a YAML file and run it.
[7]:
search_job = load_job(source=os.path.join("src", "search.yaml"))
s_job = ml_client.create_or_update(search_job)
Uploading src (0.01 MBs): 100%|##########| 10177/10177 [00:00<00:00, 10489.91it/s]
Open the job overview on Azure ML Studio in your web browser (this works when you are running this notebook in VS code).
[8]:
import webbrowser
webbrowser.open(s_job.services["Studio"].endpoint)
job_name = s_job.name
print(f'Started job: {job_name}')
Started job: salmon_plum_t9hynvf120
Download the job’s output.
[ ]:
output_name = "output_dir"
download_path = "output"
aml_helper.download_job_output(ml_client, job_name=s_job.name, output_name=output_name, download_path=download_path)
downloaded_folder = Path(download_path) / "named-outputs" / output_name
Show the Pareto Frontiers.
[10]:
param_vs_latency_img = Image(filename=downloaded_folder / "pareto_non_embedding_params_vs_onnx_latency.png")
display(param_vs_latency_img)
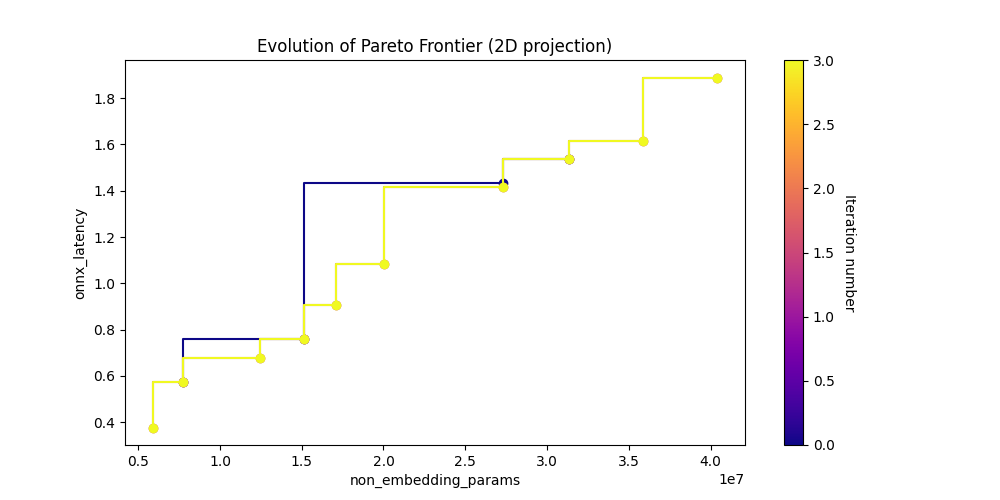
[11]:
param_vs_memory_img = Image(filename=downloaded_folder / "pareto_non_embedding_params_vs_onnx_memory.png")
display(param_vs_memory_img)
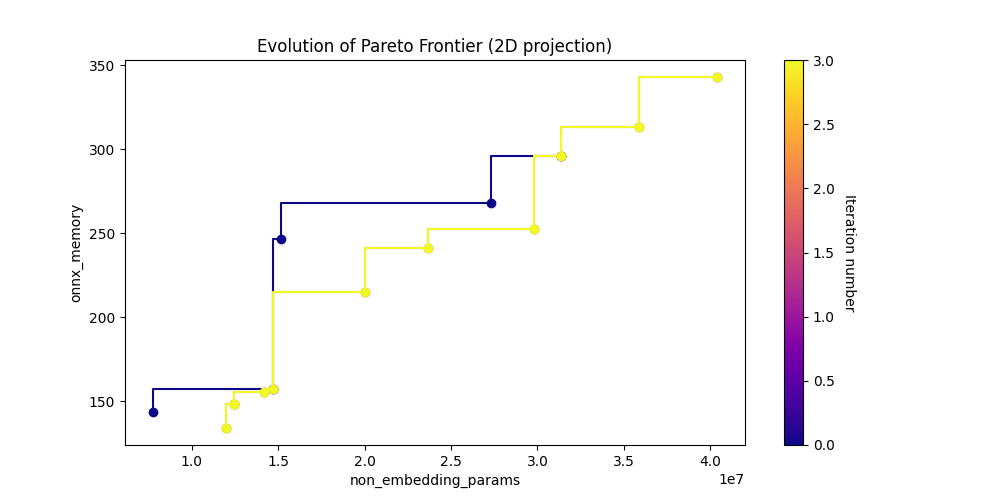
[12]:
latency_vs_memory_img = Image(filename=downloaded_folder / "pareto_onnx_latency_vs_onnx_memory.png")
display(latency_vs_memory_img)
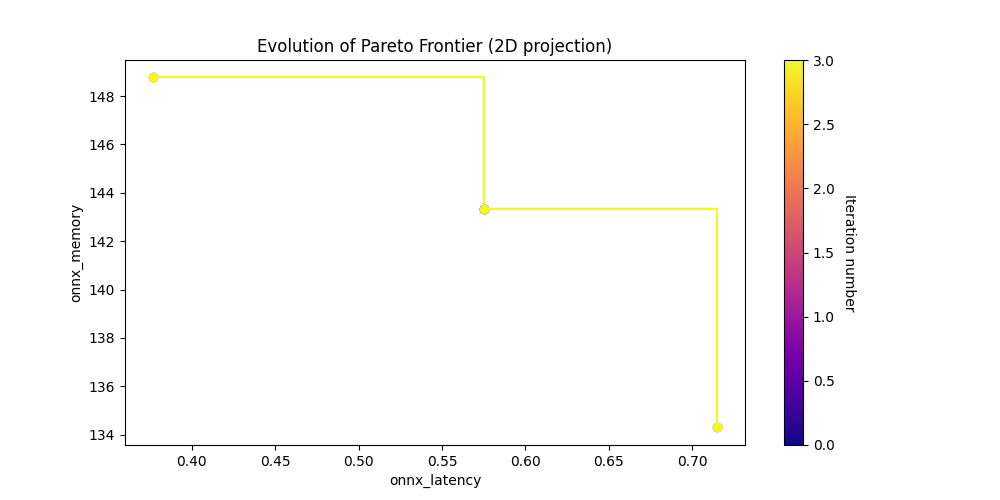
Show the search state of the last iteration.
[5]:
df = nb_helper.get_search_csv(downloaded_folder)
df = df[['archid', 'non_embedding_params', 'onnx_latency', 'onnx_memory', 'is_pareto']]
df[(df['onnx_latency'] < 0.9) & (df['is_pareto'] == True)]
[5]:
| archid | non_embedding_params | onnx_latency | onnx_memory | is_pareto | |
|---|---|---|---|---|---|
| 0 | gpt2_cea35b3f3fd242d2af609b8d2a3936cc814a7f41 | 15144192.0 | 0.761083 | 246.531515 | True |
| 1 | gpt2_df106863e1a0c9c140036b05661aa88e92f07701 | 7769472.0 | 0.575391 | 143.315580 | True |
| 2 | gpt2_0f371e7b893319c0d20944d60143fad14e2695d0 | 14724096.0 | 0.850879 | 157.321033 | True |
| 9 | gpt2_85a39fce7fd60bf8df99d17bb91298a450e2b0b1 | 12424512.0 | 0.676473 | 148.552288 | True |
| 10 | gpt2_3748aa9c59880395ceabfba51d411bfa3ca198e8 | 5917568.0 | 0.376884 | 148.768559 | True |
| 15 | gpt2_c710d31b0c06ad032125e28d4303a05676902937 | 11966848.0 | 0.714716 | 134.300035 | True |
| 18 | gpt2_1d573928a72694068c1af9608548862d8519c533 | 14199296.0 | 0.851394 | 155.320788 | True |
Job 2: Train (Train a Pareto architecture from Transformer-Flex.)#
Pick an architecture id (archid) from the CSV file to perform full training.
[14]:
archid = "<arch-id>"
print(f"Selected architecture: {archid}")
arch_path = nb_helper.get_arch_abs_path(archid=archid, downloaded_folder=downloaded_folder)
Selected architecture: gpt2_df106863e1a0c9c140036b05661aa88e92f07701
Load the training job from a YAML file, set its input, and run it. With the GPU cluster we created it should take around 3 hours.
[15]:
train_job = load_job(source=os.path.join("src", "train.yaml"))
train_job.inputs.arch_config_path.path = arch_path
t_job = ml_client.create_or_update(train_job)
Open the job overview on Azure ML Studio in your web browser (this works when you are running this notebook in VS code).
[16]:
import webbrowser
webbrowser.open(t_job.services["Studio"].endpoint)
job_name = t_job.name
print(f'Started Job: {job_name}')
Started Job: willing_tree_3b22csbdtg
Job 3: Generating text via prompt#
Load the generate text job from a YAML file, set the inputs, and run it.
[17]:
train_job = ml_client.jobs.get(t_job.name)
path = f"azureml://subscriptions/{ml_client.subscription_id}/resourcegroups/{ml_client.resource_group_name}/" \
f"workspaces/{ml_client.workspace_name}/datastores/workspaceblobstore/paths/azureml/{train_job.name}/output_dir/"
if train_job and train_job.status == "Completed":
gen_job = load_job(source=os.path.join("src", "generate_text.yaml"))
gen_job.inputs.pre_trained_model_path.path = path
gen_job.inputs.prompt = "Machine Learning"
g_job = ml_client.create_or_update(gen_job)
else:
print(f"Job {train_job.name} is not completed yet")
Open the job overview on Azure ML Studio in your web browser (this works when you are running this notebook in VS code).
[18]:
import webbrowser
webbrowser.open(g_job.services["Studio"].endpoint)
job_name = g_job.name
print(f'Started Job: {job_name}')
Started Job: orange_bee_dk3c1xm55z
Download and show the generated text.
[ ]:
output_name = "output_path"
download_path = "generated_text"
aml_helper.download_job_output(ml_client, job_name=g_job.name, output_name=output_name, download_path=download_path)
[25]:
downloaded_file = Path(download_path) / "named-outputs" / output_name / output_name
with open(downloaded_file, "r") as f:
print(f.read())
Machine Learning to continue to attend the main park in the first series. The team was considered to be used to be shot in the future. The series's longest @-@ hour of the main characters and the highest @-@ time, a series, to be used in the final series. It has been played by the series of the American, which was given by the United States and was replaced by the United States during the North America.
= = Plot summary =
The episode received by many occasions. It was a three years, and the series of the rest of the United States for the family of the previous episode,