Transformer++ Search Space#
This is an experimental feature and could change at any time
This notebook shows how to use Archai’s Tranformer++ search space for Language Modelling.
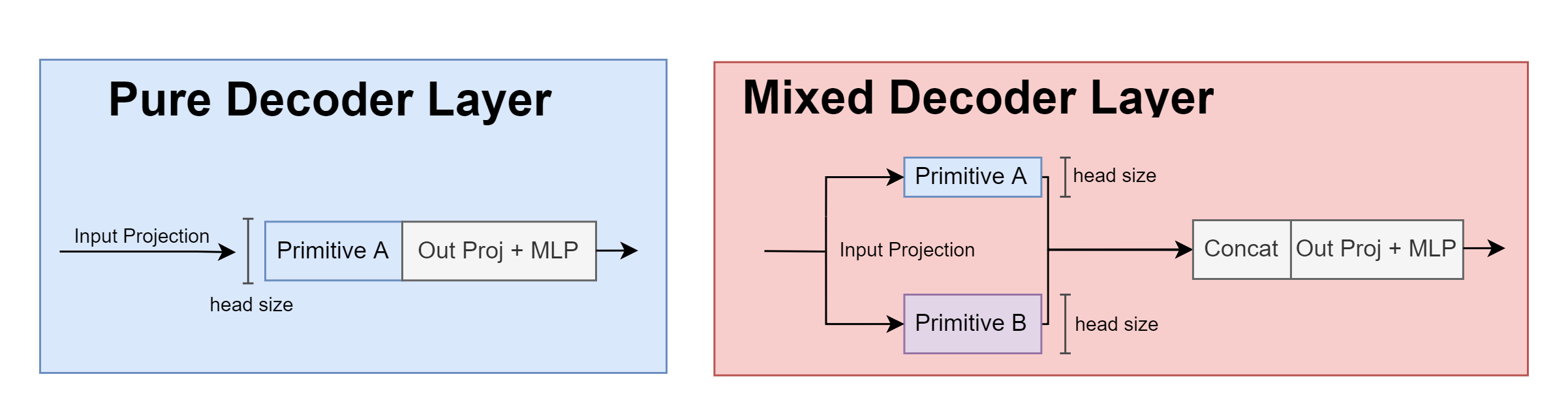
This search space consists in 8 different token-mixing primitives that can be used to create a wide variety of architectures. The Transformer++ model functions like a regular decoder-only Transformer architecture, comprising of an embedding layer, followed by a sequence \(L\) decoder layers and a final language model head.
The Transformer++ search space supports using one or more primitives on decoder layers by sharding the embedding dimension across multiple primitives:
List of Available Primitives#
Primitive |
Extra params |
Custom CUDA Kernel |
Reference |
|---|---|---|---|
Multihead Self-Attention |
🗸 |
||
SGConv |
|
🗸 |
|
SGConv3 |
|
🗸 |
|
Local Attention |
|
||
LSH Attention |
|
||
Separable Conv1D |
|
Examples#
[8]:
from archai.discrete_search.search_spaces.nlp import TfppSearchSpace
[9]:
from transformers import GPT2Tokenizer
[10]:
ss = TfppSearchSpace(
backbone='codegen', embed_dims=[768, 768*2], inner_dims=[768*4, 1024*4], total_heads=[12],
total_layers=range(6), op_subset=['mha', 'sgconv', 'local_attn'],
local_attn_window_sizes=[256, 512], sgconv_kernel_sizes=[128, 256],
mixed_ops=False, # Only one primitive per layer
homogeneous=False,
seed=42,
# Huggingface kwargs
n_positions=8192, # Maximum Seq len
vocab_size=50257
)
[11]:
m = ss.random_sample()
m.arch
[11]:
LanguageModel(
(model): CodeGenForCausalLM(
(transformer): CodeGenModel(
(wte): Embedding(50257, 1536)
(embed_dropout): Dropout(p=0.0, inplace=False)
(h): ModuleList()
(ln_f): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=1536, out_features=50257, bias=True)
)
)
Model forward pass
[12]:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('gpt2')
tokenizer.add_special_tokens({'pad_token': '<|endoftext|>'})
x = tokenizer(['Just testing', 'something'], return_tensors='pt', padding=True, truncation=True)
m.arch(**x)
[12]:
0
Some primitives have custom CUDA kernels that can be used depending on the hardware available. For more information on installation instructions, see flash_attention and H3 repos by HazyResearch.
To install archai with flash-attention kernel dependencies, use
python3 -m pip install archai[flash-attn]
Available CUDA Kernels
FusedDense (for linear projections)
FusedMLP
FlashAttention (used in MHA)
FlashRotaryEmb (used in MHA)
FastFFTConv (used in SGconv and SGconv3)
[32]:
ss = TfppSearchSpace(
backbone='codegen', embed_dims=[768, 768*2], inner_dims=[768*4, 1024*4], total_heads=[12],
total_layers=range(1, 6), op_subset=['mha', 'sgconv', 'local_attn'],
local_attn_window_sizes=[256, 512], sgconv_kernel_sizes=[128, 256],
mixed_ops=False, # Only one primitive per layer
homogeneous=False,
seed=42,
# Extra kwargs
n_positions=8192, # Maximum Seq len
vocab_size=50257,
# CUDA kernel flags
fused_mlp=True,
fused_dense=True,
fast_fftconv=True,
flash_attn=True,
flash_rotary_emb=True
)
[ ]:
#NBVAL_SKIP
m = ss.random_sample()