How is MLOps different from DevOps?
Source: Azure CAF: Machine Learning DevOps Guide
Exploration precedes development and operations Data science projects are different from application development or data engineering projects. Data science projects might or might not make it to production. After an initial analysis, it might become clear that the business outcome can't be achieved with the available datasets. Because of this reason, an exploration phase is usually the first step in a data science project. The goal in this phase is to define and refine the problem and run exploratory data analysis, in which statistics and visualizations are used to confirm or falsify the problem hypotheses. There needs to be a common understanding that the project might not extend beyond this phase. It's important to make this phase as seamless as possible to have a quick turnaround. Unless there's an element of security, which enforces processes and procedures, they should be avoided and the Data Scientist should be allowed to work with the tool and data of their choice. Real data is needed for data exploration work.
The experimentation and development stage usually begins when there is enough confidence that the data science project is feasible and can provide real business value. This stage is when development practices become increasingly important. It's a good practice to capture metrics for all of the experiments that are done at this stage. It's also important to incorporate source control so that it's possible to compare models and toggle between different versions of the code if needed. Development activities include the refactoring, testing, and automation of exploration code into repeatable experimentation pipelines, and the creation of model serving applications and pipelines. Refactoring code into more modular components and libraries helps increase reusability and testability, and it allows for performance optimization. Finally, what is deployed into staging and production environments is the model serving application or batch inference pipelines. Next to monitoring of infrastructure reliability and performance, similar to what's done for a regular application with traditional DevOps, the quality of the data, the data profile, and the model must be continuously monitored at the risk of degradation or drift. Machine learning models require retraining over time to stay relevant in a changing environment.
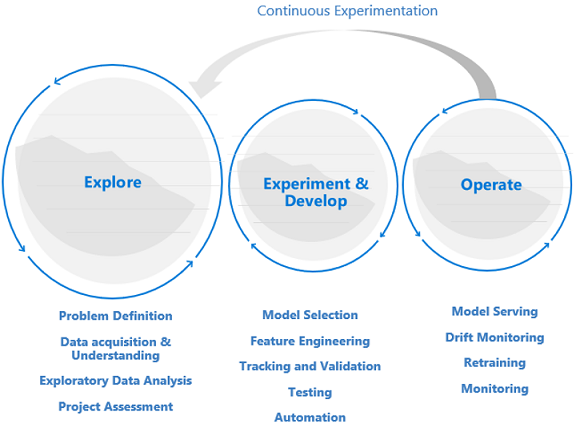
Data science lifecycle requires an adaptive way of working If you apply a typical DevOps way of working to a data science project, you might not find success because of the uncertain nature of data quality and its correlatively. Exploration and experimentation are recurring activities and needs throughout a machine learning project. The teams at Microsoft follow a project lifecycle and working process that was developed to reflect data science-specific activities. The Team Data Science Process and The Data Science Lifecycle Process are examples of reference implementations.
Data quality requirements and data availability constrain the work environment For a machine learning team to effectively develop machine learning-infused applications, production data access is desirable across work environments. If production data access isn't possible because of compliance requirements or technical constraints, consider implementing Azure role-based access control (RBAC) with Azure Machine Learning, Just-in-Time access, or data movement pipelines to create production data replicas and enable user productivity.
Machine learning requires a greater operational effort Unlike traditional software, a machine learning solution is constantly at risk of degradation because of its dependency on data quality. To maintain a qualitative solution once in production, continuous monitoring and re-evaluation of data and model quality is critical. It's expected that a production model requires timely retraining, redeployment, and tuning. These tasks come on top of day-to-day security, infrastructure monitoring, or compliance requirements and require special expertise.
Machine learning teams requires specialists and domain experts While data science projects share roles with regular IT projects, the success of a machine learning team highly depends on a group of machine learning technology specialists and domain subject matter experts. Where the technology specialist has the right background to do end-to-end machine learning experimentation, the domain expert can support the specialist to analyze and synthesize the data, or qualify the data for use.
Common technical roles that are unique to data science projects are Domain Expert, Data Engineer, Data Scientist, AI Engineer, Model Validator, and Machine Learning Engineer. To learn more about roles and tasks within a typical data science team, also refer to the Team Data Science Process.