Adopting a data science process framework
Data Science teams need to adopt some form of common process so that team members can collaborate and share code. When agreeing on a process the team should consider the following components.
- A data science lifecycle definition
- A standardized project structure - Having all projects share a directory structure and use templates for project documents will make it easier for the team members to find information about their projects.
- Infrastructure and resources for data science projects
- Tools and utilities for project execution
The process should be tailored to an organization and can be sophisticated or as light weight as possible. The key requirement is it should be adopted by all and manageable.
When agreeing a process, it helps to adopt an existing framework which can be then customised to meet the organisation's structure and culture. There are many open standard process frameworks that describes common approaches to Data Science. The CRoss Industry Standard Process for Data Mining (CRISP-DM) has been around since 1999 and has been widely adopted, with most organisations combing a loose implementation of CRISP-DM with agile project management.
Microsoft has developed two data science frameworks based on our own learnings gained on internal and customer projects, Team Data Science Process (TDSP) and Data Science Lifecycle Process (DSLP). They function as a good foundation and cover the overall topics to be successful in enterprise AI.
Team Data Science Process
Over the last couple of decades, Microsoft has developed its own Data Science Process to use internally which it is now share with the community. Microsoft has published the Team Data Science Process which customers and partners can adopt or leverage as needed. The Team Data Science Process (TDSP) provides a lifecycle to structure the development of your data science projects. This lifecycle has been designed for data science projects that ship as part of intelligent applications. These applications deploy machine learning or artificial intelligence models for predictive analytics. Exploratory data science projects or improvised analytics projects can also benefit from using this process. But in such cases, some of the steps described may not be needed.
The lifecycle outlines the major stages that projects typically execute, often iteratively:
- Business Understanding
- Data Acquisition and Understanding
- Modeling
- Deployment
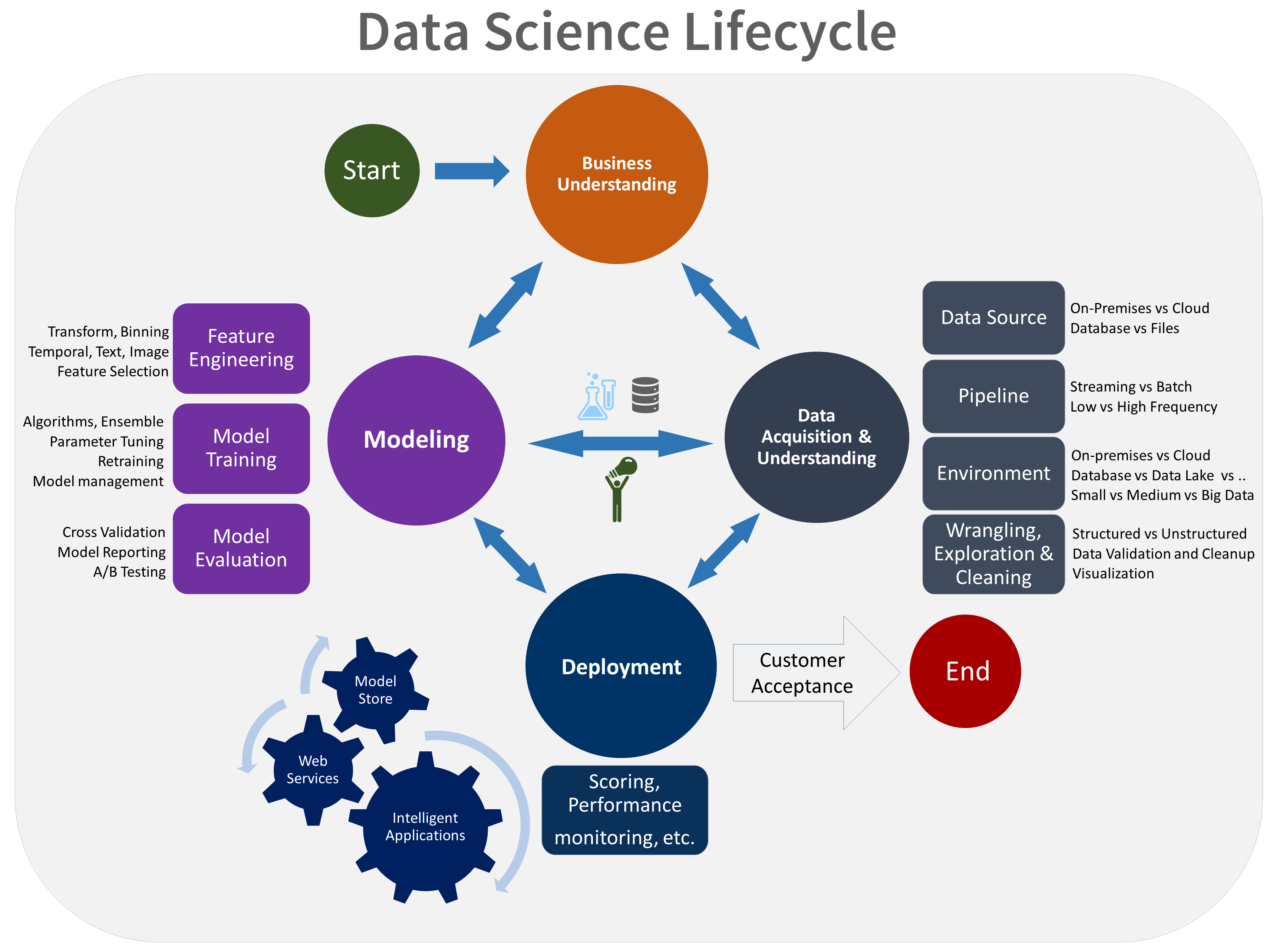
TDSP contains several guidelines and recommendations to assist the Data Science Process:
1. Standardized project structure
Having all projects share a directory structure and use templates for project documents makes it easy for the team members to find information about their projects. All code and documents are stored in a version control system (VCS) like Git, TFS, or Subversion to enable team collaboration. Tracking tasks and features in an agile project tracking system like Jira, Rally, and Azure DevOps allows closer tracking of the code for individual features. Such tracking also enables teams to obtain better cost estimates. TDSP recommends creating a separate repository for each project on the VCS for versioning, information security, and collaboration. The standardized structure for all projects helps build institutional knowledge across the organization.
2. Infrastructure and resources for data science projects
TDSP provides recommendations for managing shared analytics and storage infrastructure such as:
- Cloud file systems for storing datasets
- Databases
- Big data (SQL or Spark) clusters
- Machine learning service
The analytics and storage infrastructure, where raw and processed datasets are stored, may be in the cloud or on-premises. This infrastructure enables reproducible analysis. It also avoids duplication, which may lead to inconsistencies and unnecessary infrastructure costs. Tools are provided to provision the shared resources, track them, and allow each team member to connect to those resources securely. It is also a good practice to have project members create a consistent compute environment. Different team members can then replicate and validate experiments.
3. Tools and utilities for project execution
Introducing processes in most organizations is challenging. Tools are provided to implement the data science process and lifecycle help lower the barriers to and increase the consistency of their adoption.
TDSP provides an initial set of tools and scripts to jump-start adoption of TDSP within a team. It also helps automate some of the common tasks in the data science lifecycle such as data exploration and baseline modeling. There is a well-defined structure provided for individuals to contribute shared tools and utilities into their team's shared code repository. These resources can then be leveraged by other projects within the team or the organization. TDSP also plans to enable the contributions of tools and utilities to the whole community. The TDSP utilities may be cloned from GitHub.
For more information on TDSP, please refer to this link.
Data Science Lifecycle Process
DSLP is a set of prescriptive steps and best practices to enable data science teams to consistently deliver value. It includes issue templates for common data science work types, a branching strategy that fits the data science development flow, and prescriptive guidance on how to piece together all the various tools and workflows required to make data science work.
The Data Science Lifecycle Process is designed to be simple, lightweight, and effective. It provides a code-first workflow, with a strong emphasis on Git, working with repositories and cross-team collaboration with other developer teams. Its makes as few as possible assumptions about team structure, technology or the problems being solved. The goal is that teams can start to adopt DSLP today without major disruption.
DSLP follows a structure of different artifacts:
- Cloud configuration
- Github
- Code
- Data
- Documentation
- Environments
- Notebooks
- Pipelines
- Set up
- Tests
Key Components of DSLP
To address this need, DSLP has published workflows and prescriptive guidance in several key areas:
1. Team Workflows and Orchestration: Providing guidance and best practices on how to coordinate your data science teams, development teams, DevOps teams, and stakeholders. We illustrate how to move between the various phases of the process and make sure everyone stays on the same page. DSLP wanted to enable data scientists to work in ways they are used to. On the other hand, it also wanted to give the data science process more rigor and make it easier to integrate with the rest of the organization so that it's easier to push solutions to production. The DSLP approach represents a bridge between the two.
2. Issue Templates: DSLP has created a set of Issue Templates to bring consistency to work and make sure there are clear steps at each step of the process. Read about Issue types here.
3. Branching Strategy: The typical GitHub Flow or Git Flow branching strategies are a great starting point, but they don't lend themselves to the experimental nature of data science. We created a branching strategy that works for data science workflows while still being familiar to your development teams. Read about the branch types here.
4. Artifact Management: DSLP provides guidance on how to track all of your various artifacts including exploratory analysis, experiment logging, serialized models and machine learning pipelines such as:
- Examples
- Model registry
- Experiment Logging
- Container Registry
- ML Pipelines
5. MLOps: There is a great body of work and set of tools for adopting MLOps. MLOps helps Data Scientists apply DevOps practices to our training, deployment, monitoring, and retraining processes. DSLP directly integrates the best MLOps practices into the Data Science Lifecycle Process , leveraging the best developments in this area. * Examples * Versioning models * Logging and monitoring * Continuous Deployment and rollback strategy * A/B Testing * Automated Retraining
For more information on DSLP please refer to this link.