Skills, Roles & Responsibilities
Creating successful data science teams can often be a challenge. As it is a new field, many companies struggle to find and retain the right people. Building an open and strong community will help encourage people to consider using data science to solve business challenges or potentially as a new skill for a future career.
Building a strong center of Excellence for AI has proven as a excellent way to share knowledge and build consensus. Key to this effort is to identify strong leaders who can develop and communicate best practices. The adoption of common AI standards will provide the solid foundation to the organization's Data Science processes.
Good community leaders should have energy and experience to build a community that can span across the business and encourage the widespread and responsible use of AI.
Typical activities of a center of excellence would include:
- Encouraging the adoption of AI standards
- Collating training material
- Publishing example templates
- Publishing a regular newsletter, blogs
- Community calls, technology briefings
A strong and vibrant AI community can greatly accelerate the adoption of Enterprise AI practices within an organisation.
ML Platform team roles:
Within a large enterprise it is common to see many distinct roles and teams that will need to work closely together to develop, implement and manage AI use cases.
Core to this success will be how well the trinity of data science roles can work together. the Data Engineer, the Data Scientist and the ML Engineer.
Data engineer
Core responsibilities of the Data Engineer:
- Similar to the ML engineer except that he/she focuses on data development. A data engineer is mainly involved in data pipelines moving data between environments and tracking their lineage.
- Needs to have machine learning knowledge but is not an expert on the topic.
- The role requires strong coding skills, background in software development.
- Works often with Python, SQL, Hadoop & Spark.
- Has strong knowledge on data integration, data governance and data protection.
- This is the only role that is allowed to work in the bronze layer, also known as the raw layer of ingested data which needs to function as the single source of truth.
Required Skills - The data engineer is acquainted with object-oriented program languages such as Python, Java, C++. Work with software development tooling such as Azure DevOps, Git, CLI, Visual Studio Code and builds ETL/ELT code using tools like Azure Data Factory, Azure Synapse & Azure Databricks.
Data scientist
Microsoft classifies several distinct categories of data scientist roles: which range from code-first data scientist to more business orientated data scientist/domain expert.
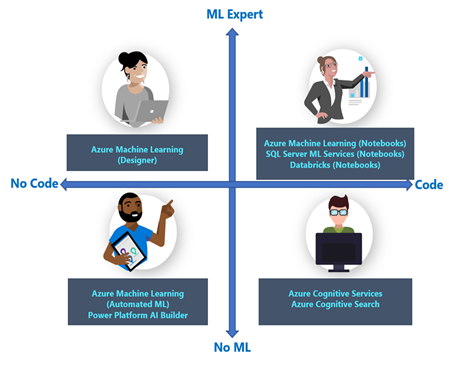
- Professional data scientist
- Focuses on three areas of the AI lifecycle: data engineering in the curated and cleaned data layer, modelling & business analysis.
- Acts as supporting role for the professionals in charge of model and infrastructure deployments.
- Is responsible to translate questions from the business into viable AI/ML solutions
- Works with different tool sets most of them requiring a code-first approach.
- Breaks the question into a process flow that always includes an understanding of the business problem, an understanding of the data required, and the types of AI/ML techniques that can solve the problem
Required Skills - Sound foundations in mathematics, data science, machine learning and they often have business acumen. They are pretty proficient at coding in Python and sometimes R.
- Citizen data scientist
- Focuses mainly on the light data engineering with curated data, modelling, and business analysis.
- Often prefers low to no-code options such as automated machine learning, GUI-based AI designers or pre-trained models available in APIs like Microsoft cognitive services.
- Solid on analytics but does not normally have deep algorithmic coding skills.
- Works heavily with data visualization tools like PowerBI, for instance.
- Often works in the business teams and normally is the point of contact for data science projects.
Required Skills - Solid business domain expertise, strong in analytics, good statistical knowledge and acquainted with hypothesis testing and validation.
ML engineer
Core responsibilities of the ML Engineer:
- Involved in three stages of the lifecycle: data development (pre-processing), model development and production.
- Mainly responsible for productionizing a model, with a strong focus on software development practices such as DevOps, CI/CD, monitoring and the right AI infrastructure for scaling the solution
- This role requires strong coding skills, background in software development, has to be able to communicate on multiple different levels in order for the right implementation in the three different environments (dev/test/prod) of pipeline execution.
- Focuses more on pipelines focused on ML, together with the data engineer who is responsible for the data pipelines.
Required Skills - Strong in mathematics, software engineering & machine learning. The ML engineer is very strong in coding specifically focused on object-oriented programs such as Python, Java, C++. Work with regular software development tooling such as Azure DevOps, Git, CLI, Visual Studio Code.