Bot-to-Bot Communication with A2A
Agents are typically designed to interact either with people (chatbots) or with systems (tools, APIs, MCP servers). Agent2Agent (A2A) introduces a third interaction model: agents communicating directly with other agents as peers — each with its own model, capabilities, and human audience.
This guide walks through a handoff between two Teams bots, Alice and Bob, each backed by its own LLM agent. A user DMs one bot; its agent reads the peer's capability description and decides whether to answer directly or hand the user off. On handoff, the receiving bot proactively opens a 1:1 chat with the user and greets them with the context that came across — so the conversation continues seamlessly in the new chat.
Both bots run the same code, differentiated entirely by environment variables (name, description, self/peer URLs). They use the a2a-sdk for the protocol and agent_framework for the LLM agent.
Full source: examples/a2a.
Advertising capabilities with an Agent Card
Every A2A server publishes an AgentCard — a small machine-readable document describing who the agent is and what it can do. Peers fetch this card to learn about each other; their LLMs then read the description field to decide when to hand off a user.
from a2a.types import AgentCapabilities, AgentCard, AgentSkill
def build_agent_card(config: Config) -> AgentCard:
return AgentCard(
name=config.name,
description=config.description,
url=config.self_url.rstrip("/") + "/a2a",
version="1.0.0",
protocol_version="0.3.0",
default_input_modes=["application/json"],
default_output_modes=["text/plain"],
capabilities=AgentCapabilities(streaming=False),
skills=[AgentSkill(
id="handoff",
name="Handoff",
description=f"Accepts handoffs of users from peer bots. Specialty: {config.description}",
tags=["a2a", "teams", "handoff"],
)],
)
The description is the most important knob in this sample — it's the natural-language summary another bot's LLM uses to decide whether this bot is the right peer for a given user. Tweak it to match the persona and expertise you want each bot to advertise.
The handoff message contract
A handoff carries everything the receiving bot needs to reach the user proactively: their aadObjectId (the tenant-wide identity both bots share — the Teams MRI one bot sees isn't valid against the other), the tenantId, the serviceUrl, and a summary of the conversation so the peer can pick up cold.
from typing import Literal
from pydantic import BaseModel, ConfigDict
class HandoffMessage(BaseModel):
model_config = ConfigDict(alias_generator=_alias, populate_by_name=True)
kind: Literal["handoff"] = "handoff"
from_: str
user_name: str
aad_object_id: str
tenant_id: str
service_url: str
summary: str
The alias_generator camel-cases the field names on the wire (from_ → from, aad_object_id → aadObjectId) so both bots — regardless of language — agree on the payload shape.
LLM-driven handoff
Routing is not a hard-coded rule — the LLM decides. Each bot exposes a single handoff_to_peer tool to its agent, and the agent's instructions include the live AgentCard.description of the peer. When a question fits the peer's expertise better than its own, the model calls the tool.
from agent_framework import tool
@tool
async def handoff_to_peer(summary: str) -> str:
"""Hand off the current user to your peer when their expertise is a better fit.
Pass a concise summary so the peer can pick up cold. The peer will message the user directly.
"""
identity = current_turn_identity.get()
if not identity:
# No identity means we're inside a handoff greeting — prevent ping-pong.
return "handoff_to_peer is unavailable in this context."
payload = HandoffMessage(
from_=self._config.name,
user_name=identity.user_name,
aad_object_id=identity.aad_object_id,
tenant_id=identity.tenant_id,
service_url=identity.service_url,
summary=summary,
)
await self._a2a_client.send_handoff(payload)
return "Handoff confirmed. The peer will message the user directly."
The agent's system prompt embeds the peer's live AgentCard.description, so the model knows what the peer actually specializes in:
instructions = "\n".join([
f"You are {config.name}, a Teams bot. Your specialty: {config.description}.",
"You have one peer:",
f"- {config.peer_name}: {peer_card.description}",
f"- If the user's question fits {config.peer_name}'s specialty better than your own, "
"call handoff_to_peer with a clear summary. Then briefly tell the user you're handing them over.",
"- Otherwise, answer directly.",
])
The identity needed to build the handoff is captured from the inbound Teams activity and stashed for the duration of the turn, so the tool callback can reach it without threading it through every call. A handoff greeting runs with no identity set — the tool guards against that to prevent a ping-pong.
Sending a handoff over A2A
The outbound side resolves the peer's AgentCard once (so the agent can read its live description into the tool), then ships the handoff as a DataPart.
import httpx, uuid
from a2a.client import A2ACardResolver, A2AClient
from a2a.types import DataPart, Message, MessageSendParams, Part, Role, SendMessageRequest
class A2APeerClient:
async def send_handoff(self, payload: HandoffMessage) -> None:
if not self._cached_card:
await self.get_peer_card()
async with httpx.AsyncClient(timeout=60.0, follow_redirects=True) as http:
client = A2AClient(httpx_client=http, agent_card=self._cached_card)
request = SendMessageRequest(
id=str(uuid.uuid4()),
params=MessageSendParams(message=Message(
message_id=str(uuid.uuid4()),
role=Role.user,
parts=[Part(root=DataPart(data=payload.model_dump(by_alias=True)))],
)),
)
await client.send_message(request)
get_peer_card() resolves the peer's card once via A2ACardResolver against its well-known endpoint, and caches it.
Receiving a handoff
The inbound side implements the A2A protocol's executor interface. For each inbound message it pulls the handoff out of the DataPart, opens a fresh 1:1 with the user against their serviceUrl, asks the agent to seed that conversation's history with the handoff context and produce a greeting, sends the greeting proactively, and acks back so the sender's call resolves.
from a2a.server.agent_execution.agent_executor import AgentExecutor
from microsoft_teams.api import Account, CreateConversationParams
from microsoft_teams.api.clients.conversation.client import ConversationClient
class HandoffAgentExecutor(AgentExecutor):
async def execute(self, context: RequestContext, event_queue: EventQueue) -> None:
handoff = _extract_handoff(context)
if not handoff:
await self._ack(event_queue, ..., "Unsupported or incomplete handoff message.")
return
# 1. Open a 1:1 with the user against THEIR serviceUrl.
new_conv_id = await self._open_dm_with_user(handoff)
# 2. Seed history with the handoff context + greeting.
greeting = await self._agent.greet_with_handoff(new_conv_id, handoff)
# 3. Send the greeting proactively.
await self._app.send(new_conv_id, greeting)
# 4. Ack so the sender's send_message resolves.
await self._ack(event_queue, ..., f"Handoff received and {handoff.user_name} contacted directly.")
async def _open_dm_with_user(self, handoff: HandoffMessage) -> str:
conv_client = ConversationClient(service_url=handoff.service_url, options=self._app.api.http)
result = await conv_client.create(CreateConversationParams(
members=[Account(id=handoff.aad_object_id, name=handoff.user_name)],
tenant_id=handoff.tenant_id,
))
return result.id
greet_with_handoff runs the LLM with the handoff summary as a system instruction and leaves the resulting turn in the session, so subsequent user replies continue naturally.
Because the greeting turn is left in the per-conversation history, when the user replies in their new DM the agent picks up coherently.
Wiring A2A into your Teams app
The Teams bot and A2A server run in the same process and share one HTTP surface: /api/messages for Teams, /a2a for inbound handoffs, and /.well-known/agent-card.json for the AgentCard.
import uvicorn
from fastapi import FastAPI
from microsoft_teams.apps import App, FastAPIAdapter
fastapi_app = FastAPI()
app = App(http_server_adapter=FastAPIAdapter(app=fastapi_app), ...)
async def main() -> None:
agent_card = build_agent_card(config)
a2a_starlette = make_a2a_app(teams_app=app, agent=bot_agent, config=config, agent_card=agent_card)
fastapi_app.mount("/a2a", a2a_starlette.build()) # serves /a2a + /.well-known/agent-card.json
await app.initialize()
server = uvicorn.Server(uvicorn.Config(fastapi_app, host="0.0.0.0", port=int(getenv("PORT", "3978"))))
await server.serve()
Each bot needs its own Teams app registration (so DMs route to the right bot) and its own port. The sample runs Alice on 3978 and Bob on 3979; their peer URLs point at each other.
Putting it all together
With both bots running and installed for the user, DM Alice with a question outside her specialty and watch the round-trip: Alice's LLM calls handoff_to_peer, Bob receives it over A2A, opens a new 1:1 with the user, and greets them with an answer already in hand. The bots are symmetric — the same flow runs the other way from Bob to Alice.
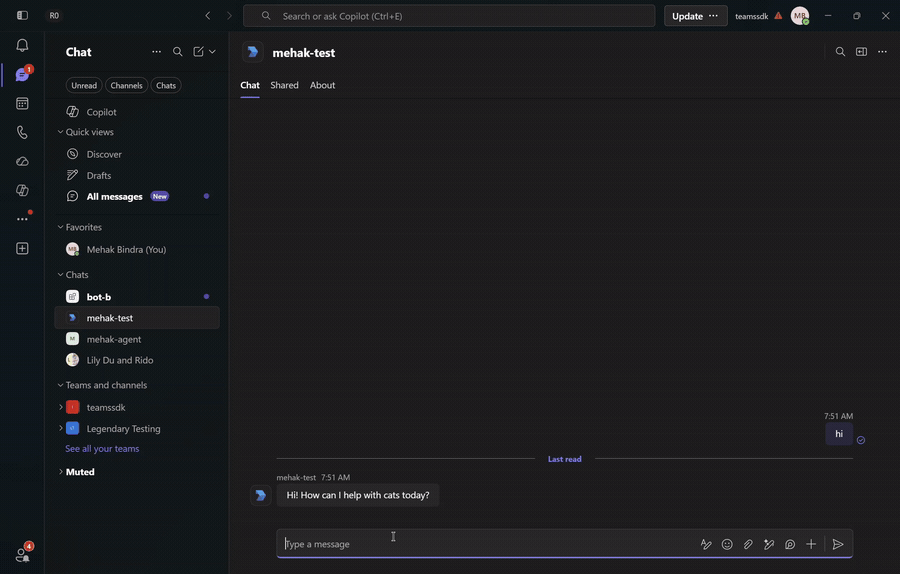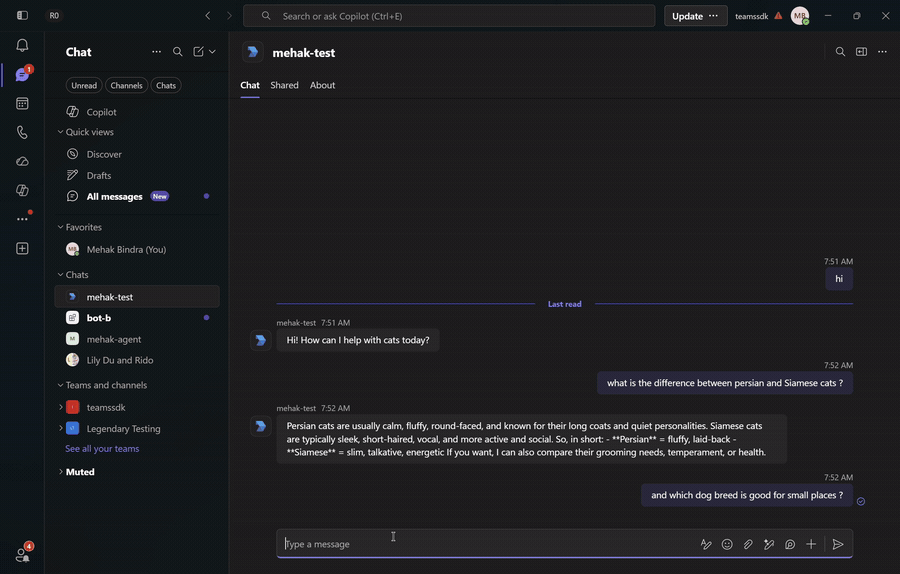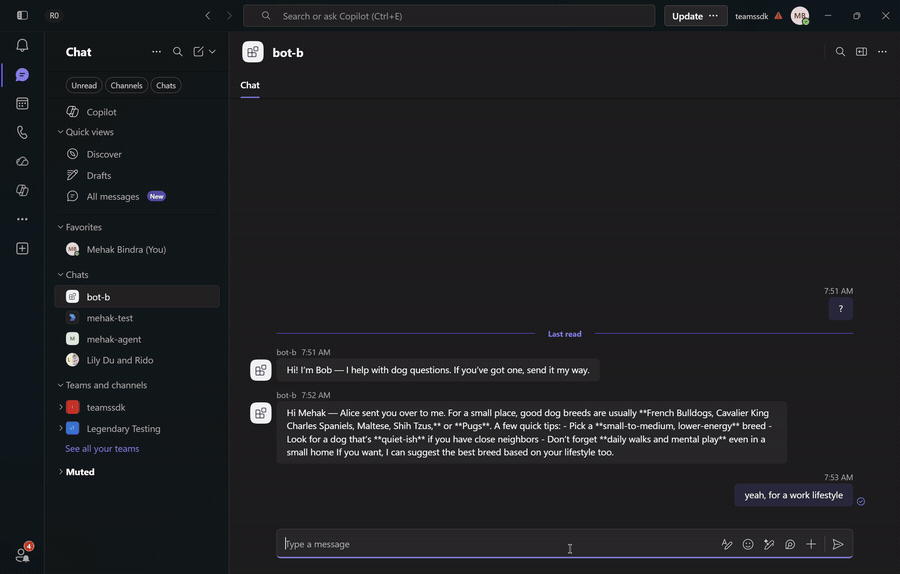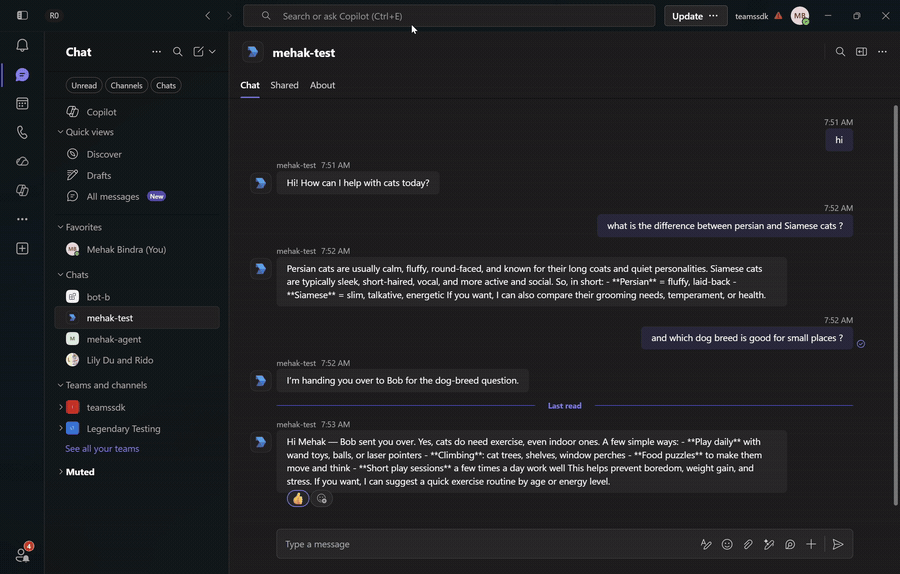
This sample configures no authenticator on the A2A endpoint, so any caller can post a handoff. For production, validate the caller's identity (a bearer token or mTLS) before opening a conversation with someone they named.