Enhance the Teams Experience
You can enrich the agent output into a more Teams-native experience — adding structure, interactivity, and metadata on top of the generated text. This guide builds on the agent from Build an agent in Teams.
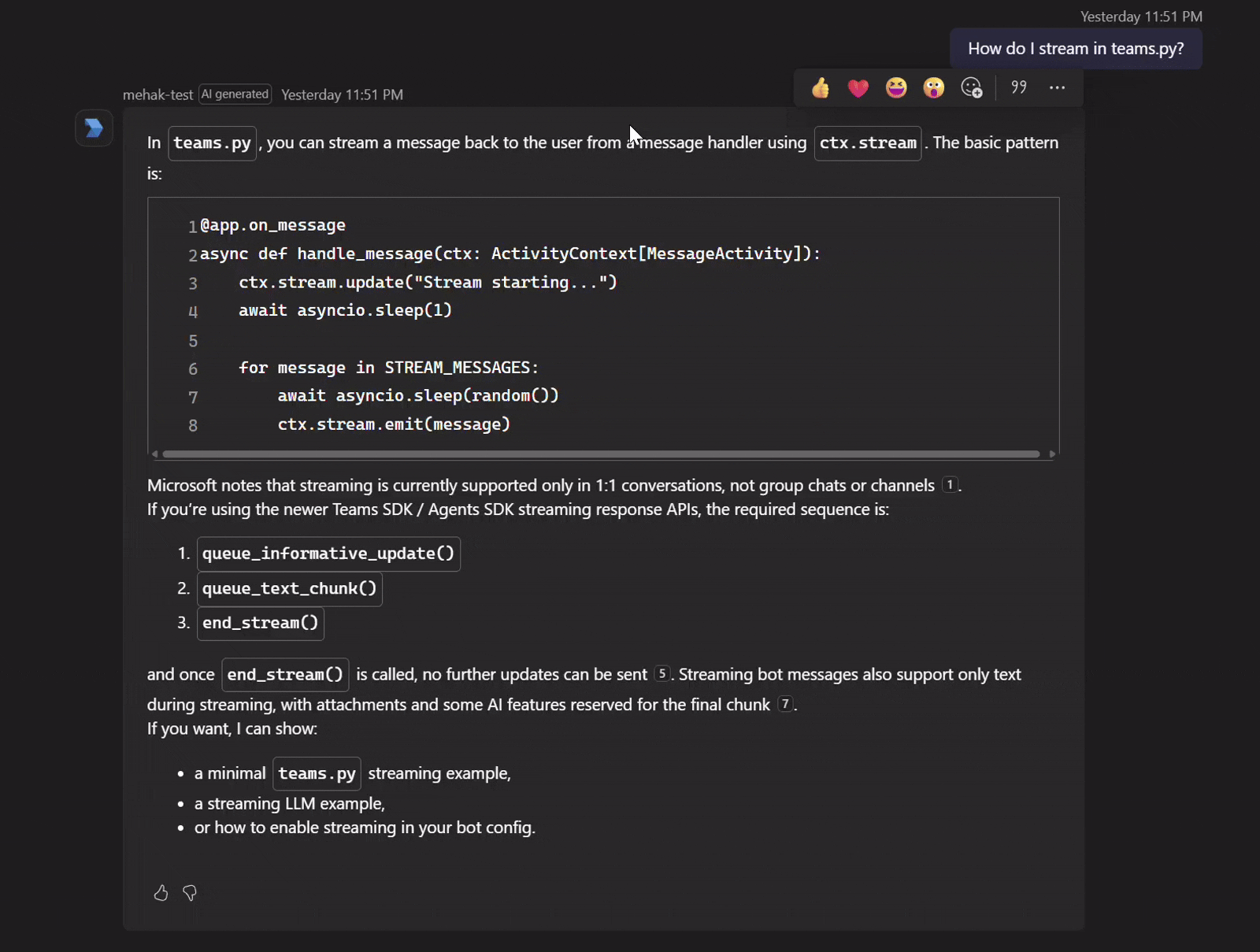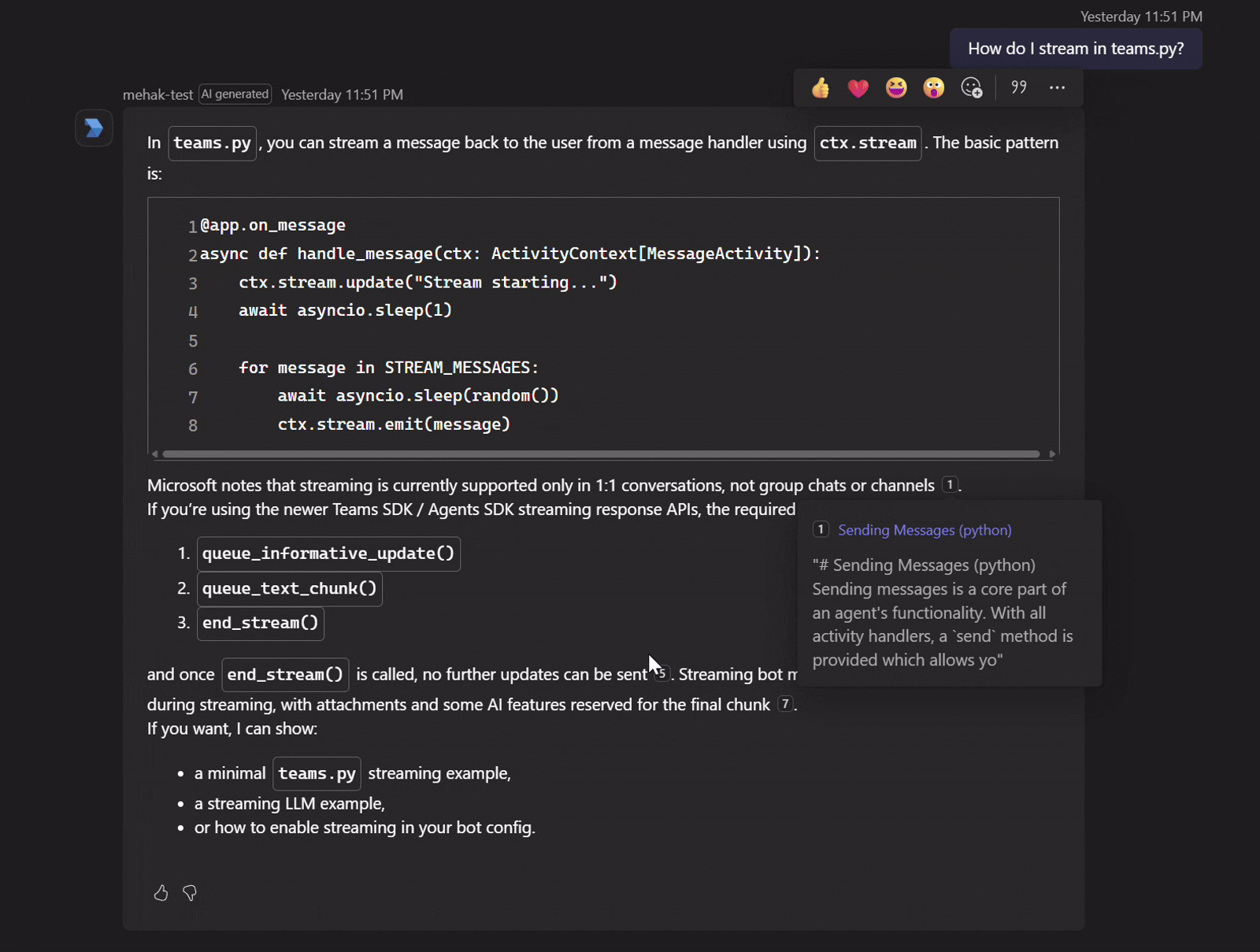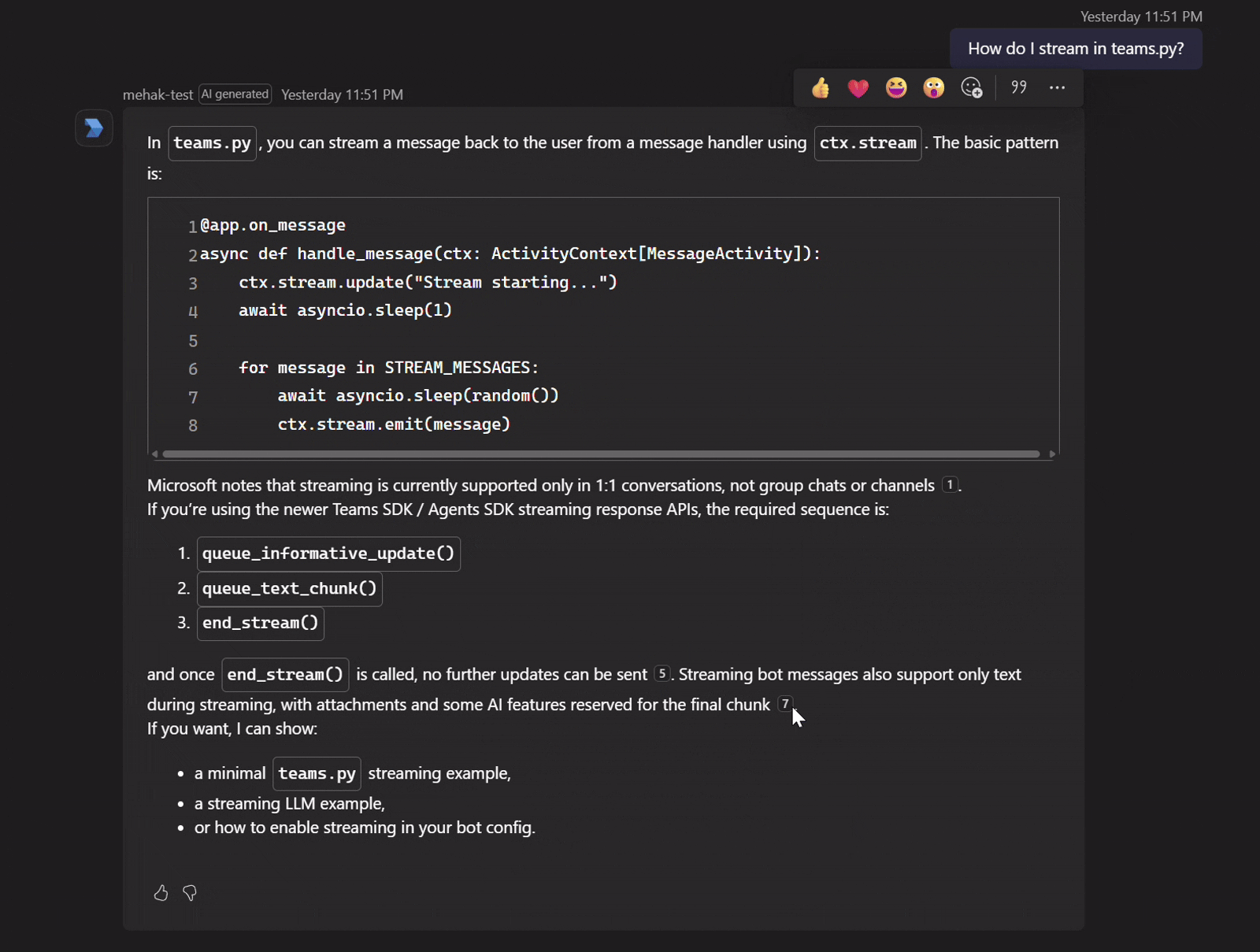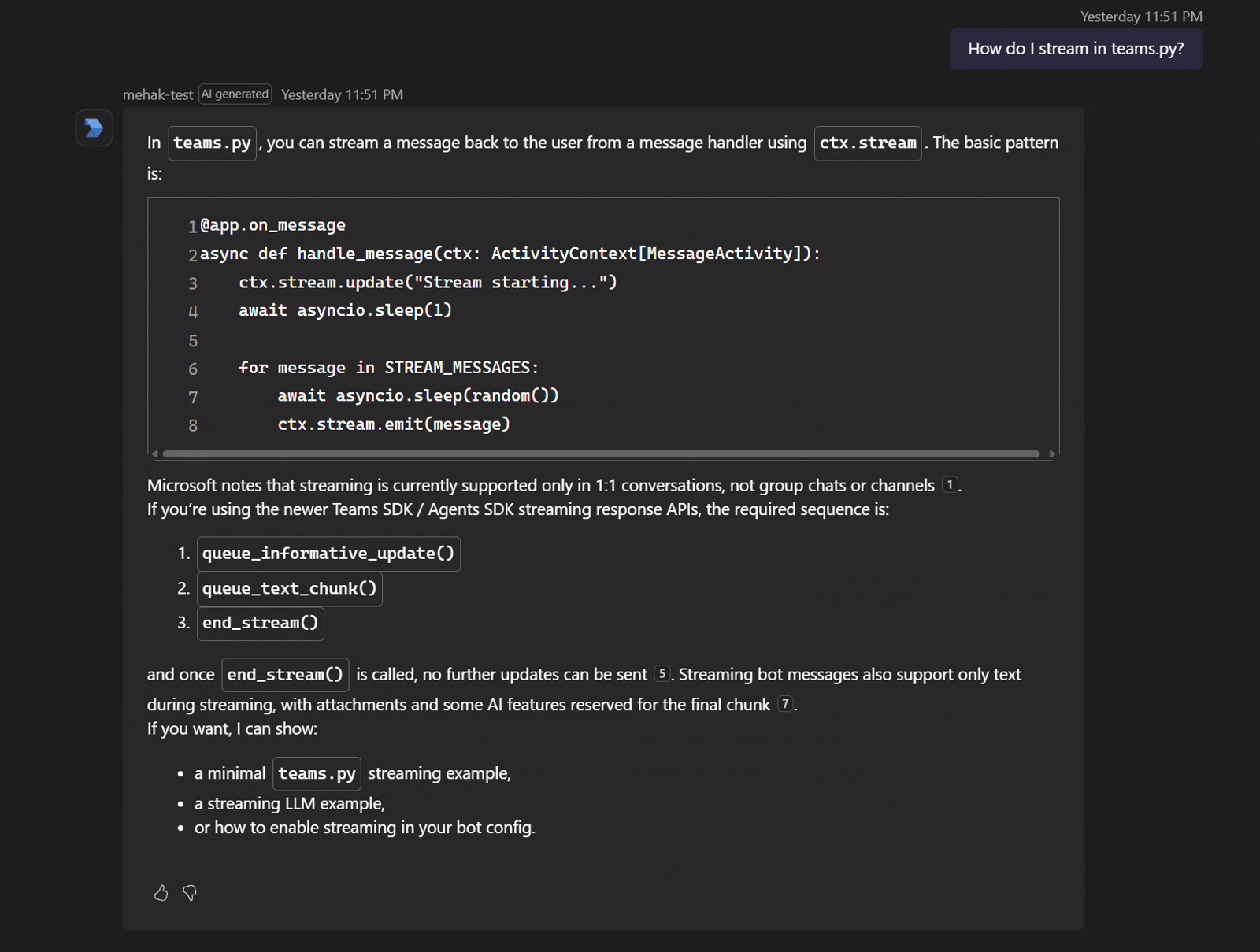
Streaming
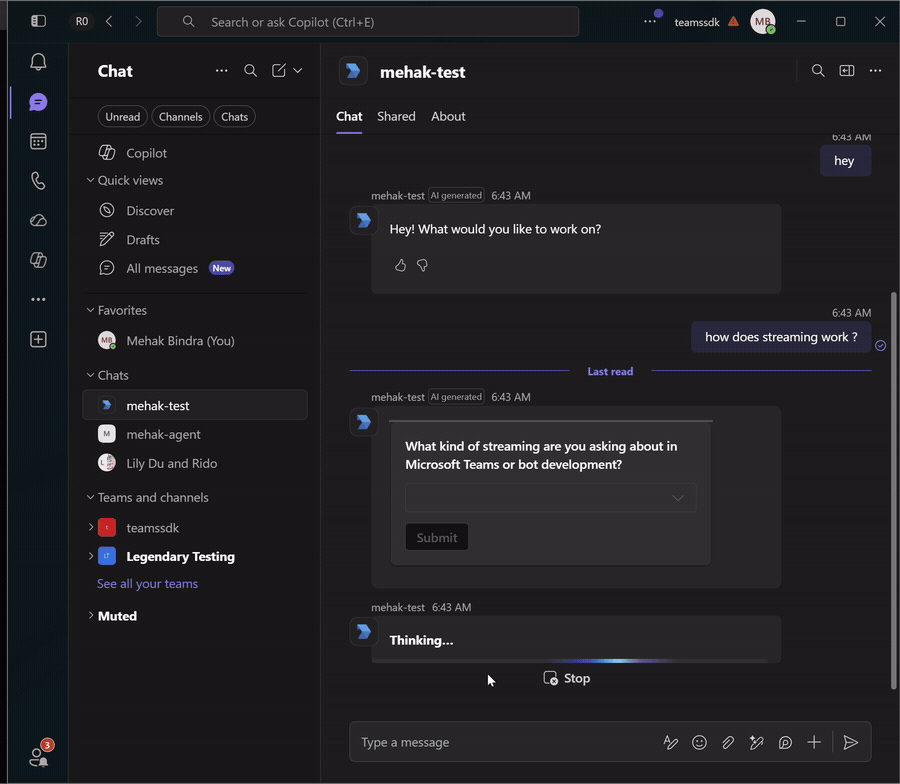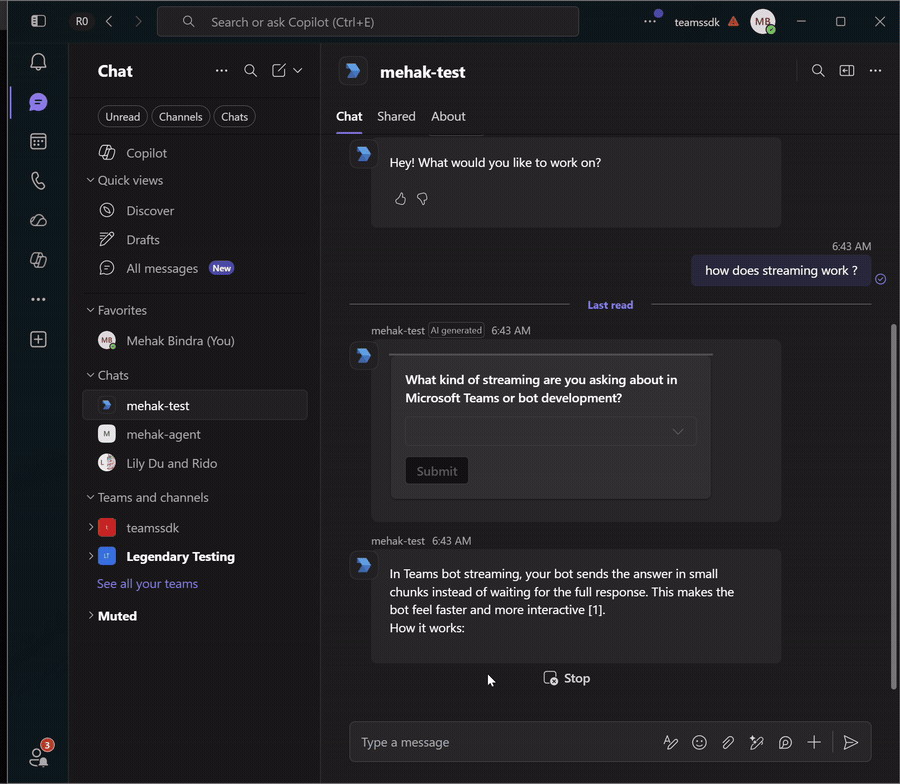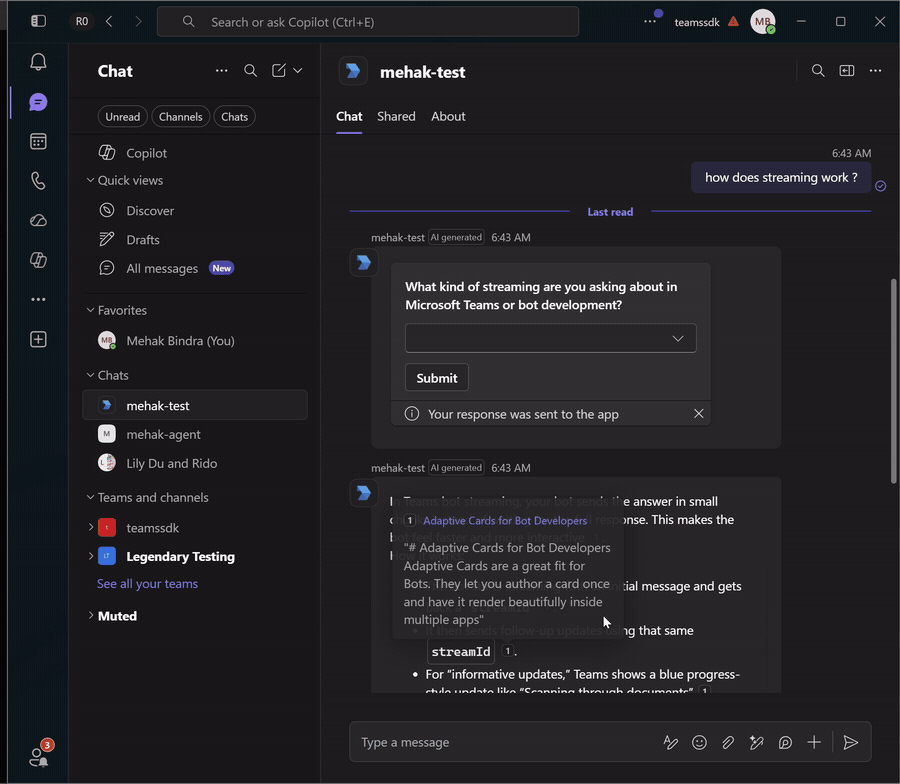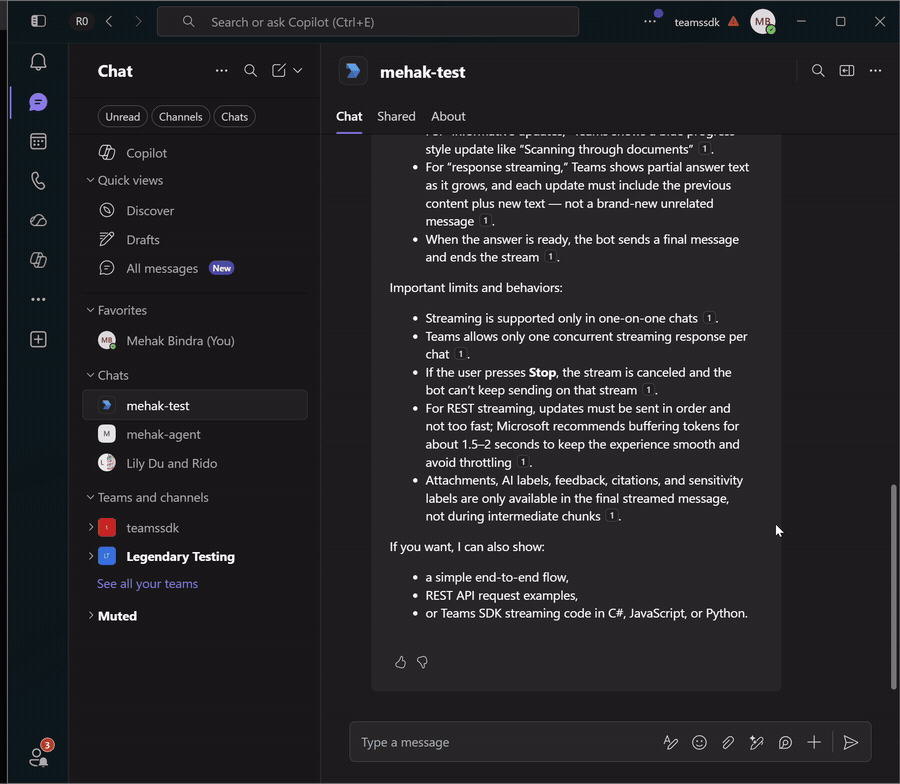
Streaming delivers responses to Teams incrementally as they're generated, rather than waiting for the full reply to complete. Each chunk of text is appended to the stream as it arrives.
@app.on_message
async def handle_message(ctx: ActivityContext[MessageActivity]):
async for chunk in agent.run(ctx.activity.text or "", stream=True):
if chunk.text:
ctx.stream.emit(chunk.text)
See Streaming for the full story on how Teams renders chunks and the constraints on stream lifecycle.
AI-generated label
Mark the message as system-generated so Teams clearly labels it as AI output.
add_ai_generated() marks the message as system-generated.
reply = MessageActivityInput().add_ai_generated()
ctx.stream.emit(reply)
Feedback
Enable built-in thumbs up/down controls on the reply and surface a custom feedback form when users respond.
add_feedback(mode="custom") enables the thumbs up/down controls and lets you surface a custom feedback form when users respond.
reply = MessageActivityInput().add_ai_generated().add_feedback(mode="custom")
ctx.stream.emit(reply)
See Feedback for the full form-handling story — capturing the submission, persisting it, and following up with the user.
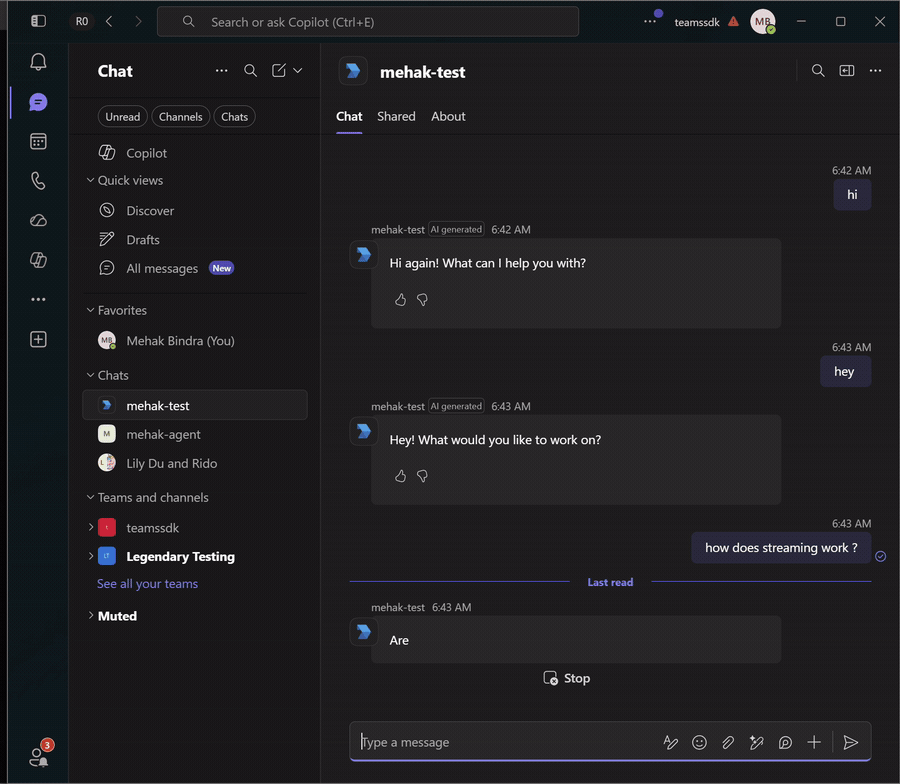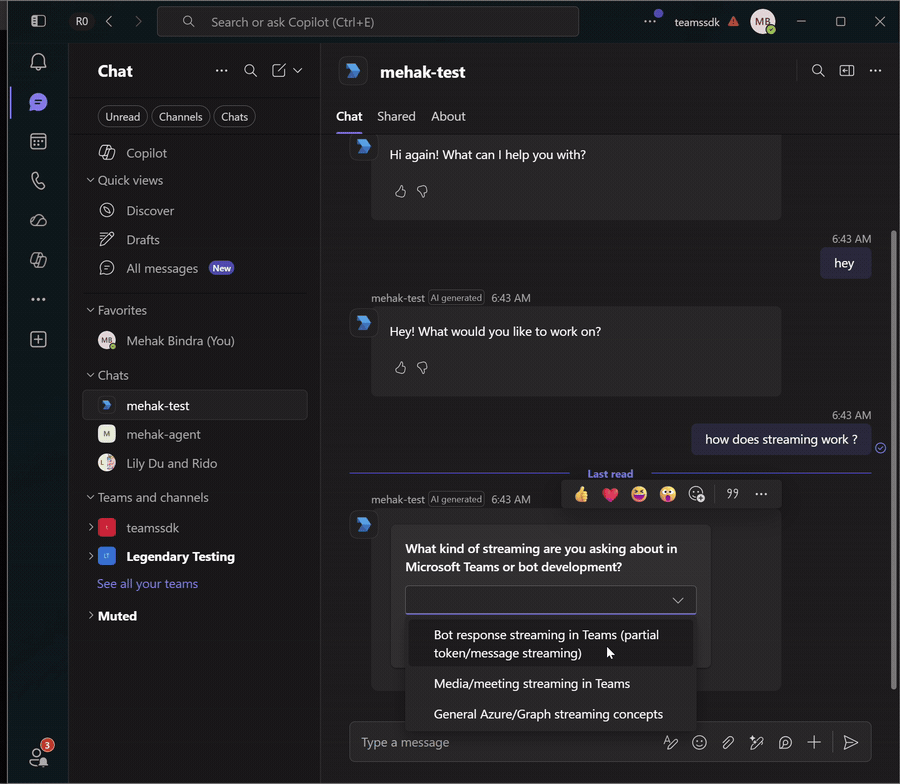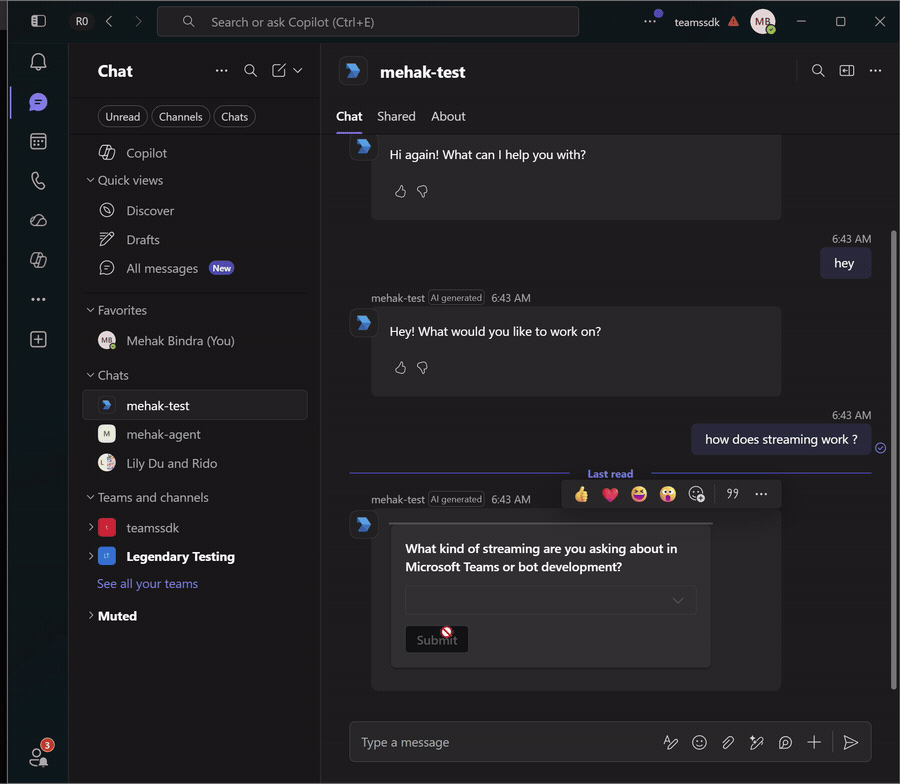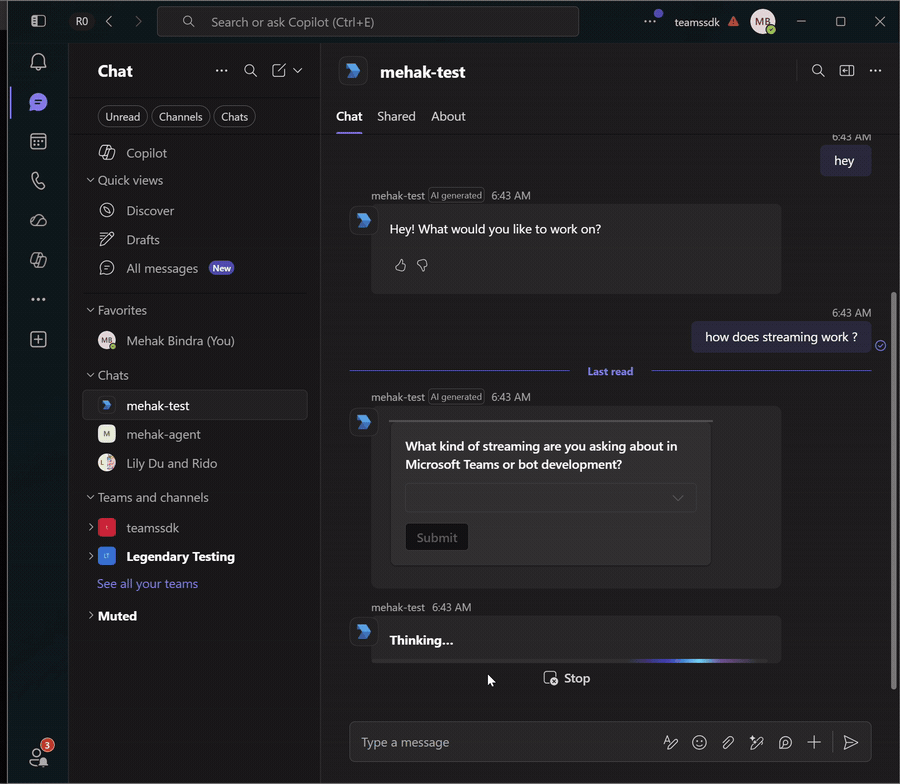
Clarification cards
When the agent calls the request_clarification tool (from Build an agent), the reply is a card, not text. The model still produces a short wrap-up after the tool returns, so discard the streamed text and send only the card. Clearing the stream's accumulated text before emitting the card-only activity keeps the turn to a single clean reply.
async def _run_agent_and_reply(ctx, session, text: str) -> None:
cards: list[AdaptiveCard] = []
pending_cards.set(cards)
full_text = ""
async for chunk in agent.run(text, session=session, stream=True):
if chunk.text:
ctx.stream.emit(chunk.text)
full_text += chunk.text
if cards:
# Clarification card — discard any streamed text, then emit card-only.
ctx.stream.clear_text()
reply = MessageActivityInput().add_ai_generated()
for card in cards:
reply.add_card(card)
ctx.stream.emit(reply)
else:
# normal reply: attach follow-ups, citations, feedback (below).
...
The user's choice is captured by a card-action handler and fed straight back into the agent as the next turn:
@app.on_card_action_execute(CLARIFICATION_VERB)
async def handle_clarification(ctx: ActivityContext[AdaptiveCardInvokeActivity]) -> AdaptiveCardInvokeResponse:
choice = (ctx.activity.value.action.data or {}).get(CLARIFICATION_INPUT_ID, "")
if choice:
session = _sessions[ctx.activity.conversation.id]
await _run_agent_and_reply(ctx, session, choice)
return AdaptiveCardActionMessageResponse(
status_code=200, type="application/vnd.microsoft.activity.message", value="OK",
)
The user's selection arrives as a fresh turn through the card-action route — the same code path as a normal message — so the agent picks up with full context.
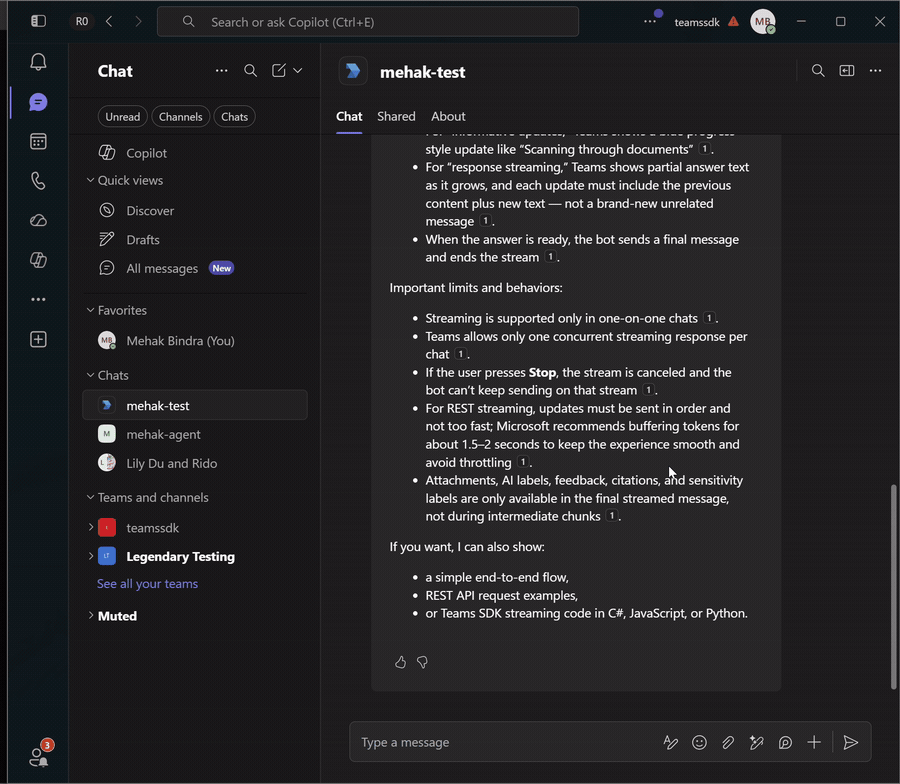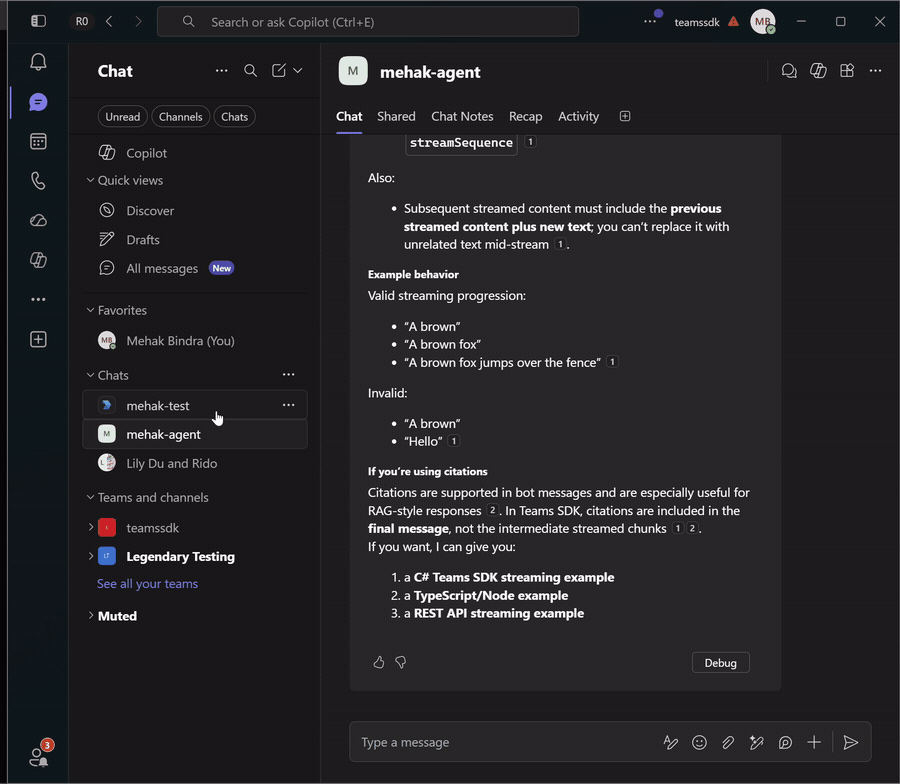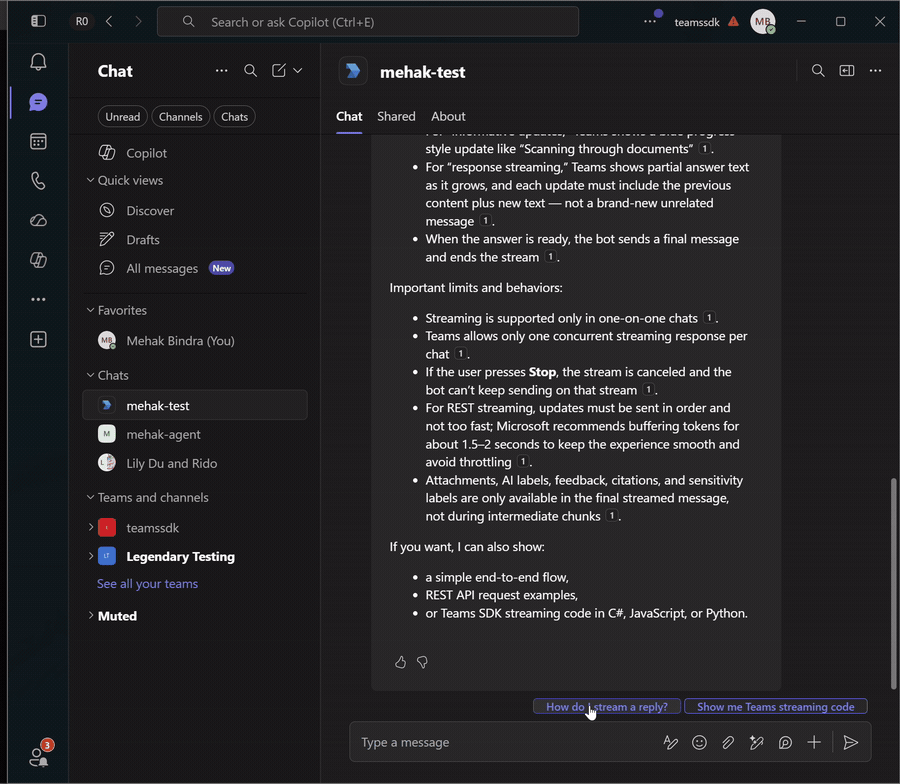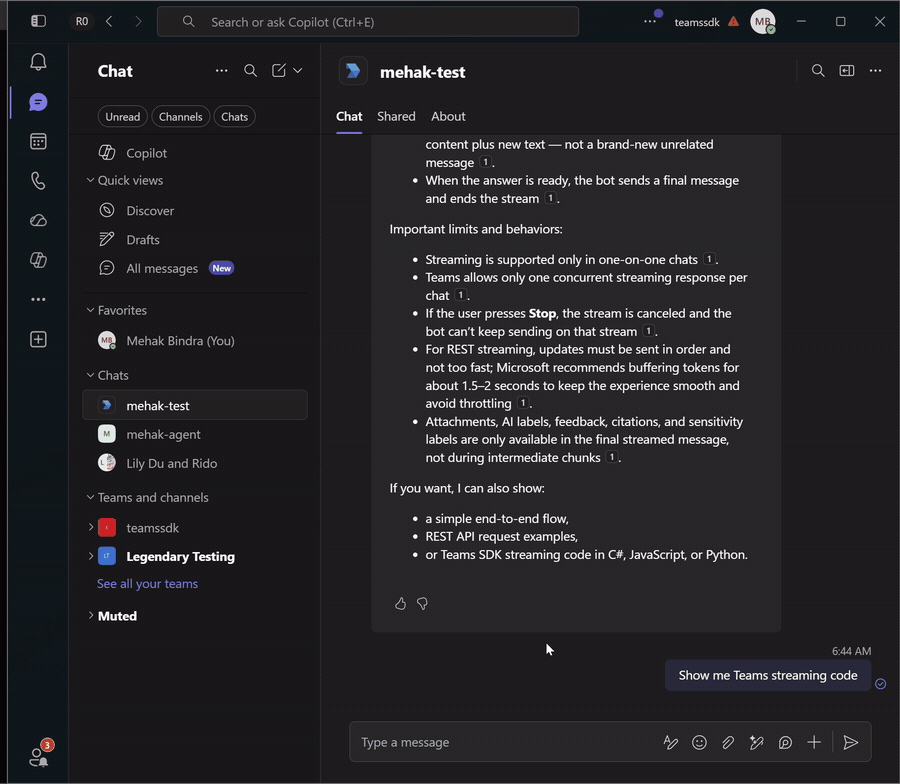
Suggested prompts
Suggested prompts give the user one-click follow-up questions after a reply. In Teams they render as chips under the message; tapping one sends the value back as a normal user message, so the same message handler picks it up — no extra routing required.
Rather than hard-coding them, generate two contextual follow-ups with a separate lightweight model call constrained to a strict JSON schema, then attach them as suggested actions.
import json
from microsoft_teams.api import CardAction, CardActionType, SuggestedActions
_FOLLOW_UPS_PROMPT = (
"Based on the conversation so far, suggest exactly 2 short follow-up questions the user might want to ask next. "
'Respond with JSON: {"followUps": ["question 1", "question 2"]}. Keep each question under 60 characters.'
)
async def _generate_follow_ups(last_user_text: str, last_ai_text: str) -> list[CardAction]:
completion = await openai_client.chat.completions.create(
model=getenv("AZURE_OPENAI_MODEL", ""),
messages=[
{"role": "user", "content": last_user_text},
{"role": "assistant", "content": last_ai_text},
{"role": "system", "content": _FOLLOW_UPS_PROMPT},
],
response_format=_FOLLOW_UPS_SCHEMA, # strict json_schema
)
data = json.loads(completion.choices[0].message.content or "{}")
return [CardAction(type=CardActionType.IM_BACK, title=q, value=q) for q in data.get("followUps", [])[:2]]
Attach the generated prompts to the reply with with_suggested_actions:
reply.with_suggested_actions(
SuggestedActions(to=[ctx.activity.from_.id], actions=follow_ups)
)
The follow-up call runs separately from the main agent, so any parse or network failure silently degrades to no chips while the main reply still ships.
Citations
Citations render as footnote-style references inline with the reply — [1], [2], etc. — surfacing the source title, abstract, and URL on hover. They originate from tool outputs, where the collector from Grounding responses with citations assigned each result a stable position.
When building the final reply, attach only the citations whose position actually appears in the streamed text.
import re
from microsoft_teams.api import CitationAppearance
def _attach_citations(reply: MessageActivityInput, full_text: str) -> None:
used_positions = {int(n) for n in re.findall(r"\[(\d+)\]", full_text)}
for annotation in tool_logger.citations.values():
pos = annotation["position"]
if pos in used_positions:
reply.add_citation(
position=pos,
appearance=CitationAppearance(
name=annotation.get("title") or f"Source {pos}",
abstract=annotation.get("snippet") or "No description available.",
url=annotation.get("url"),
),
)
tool_logger is the CitationMiddleware instance from Build an agent; its citations dict is reset at the start of each turn.