Getting Started
Clone it & Create Connection to AML
-
Clone the repo on your local machine
-
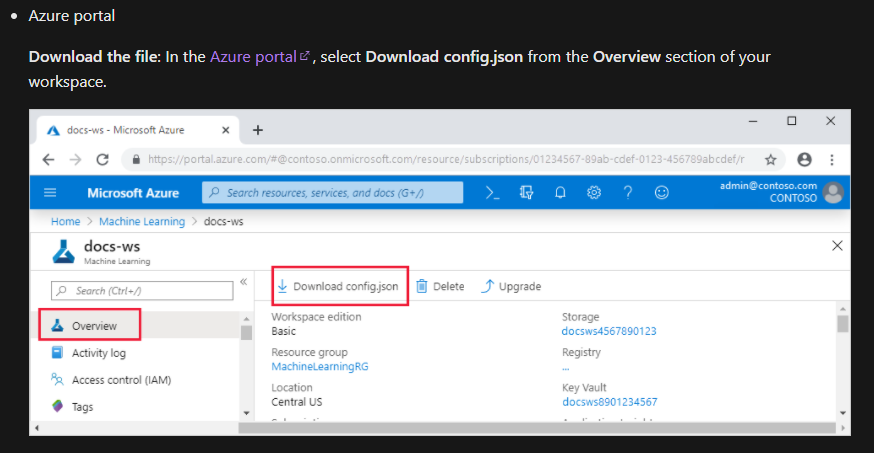
To be able to use the scripts on your local machine, add the azure ml workspace credentials in a config.json file in the root directory and, if it is not present already, very important (!) add it to the gitignore file.
Setup The Infrastructure
-
Navigate to Azure DevOps and create a new organization and project. You can also re-use an existing organization and/or project.
-
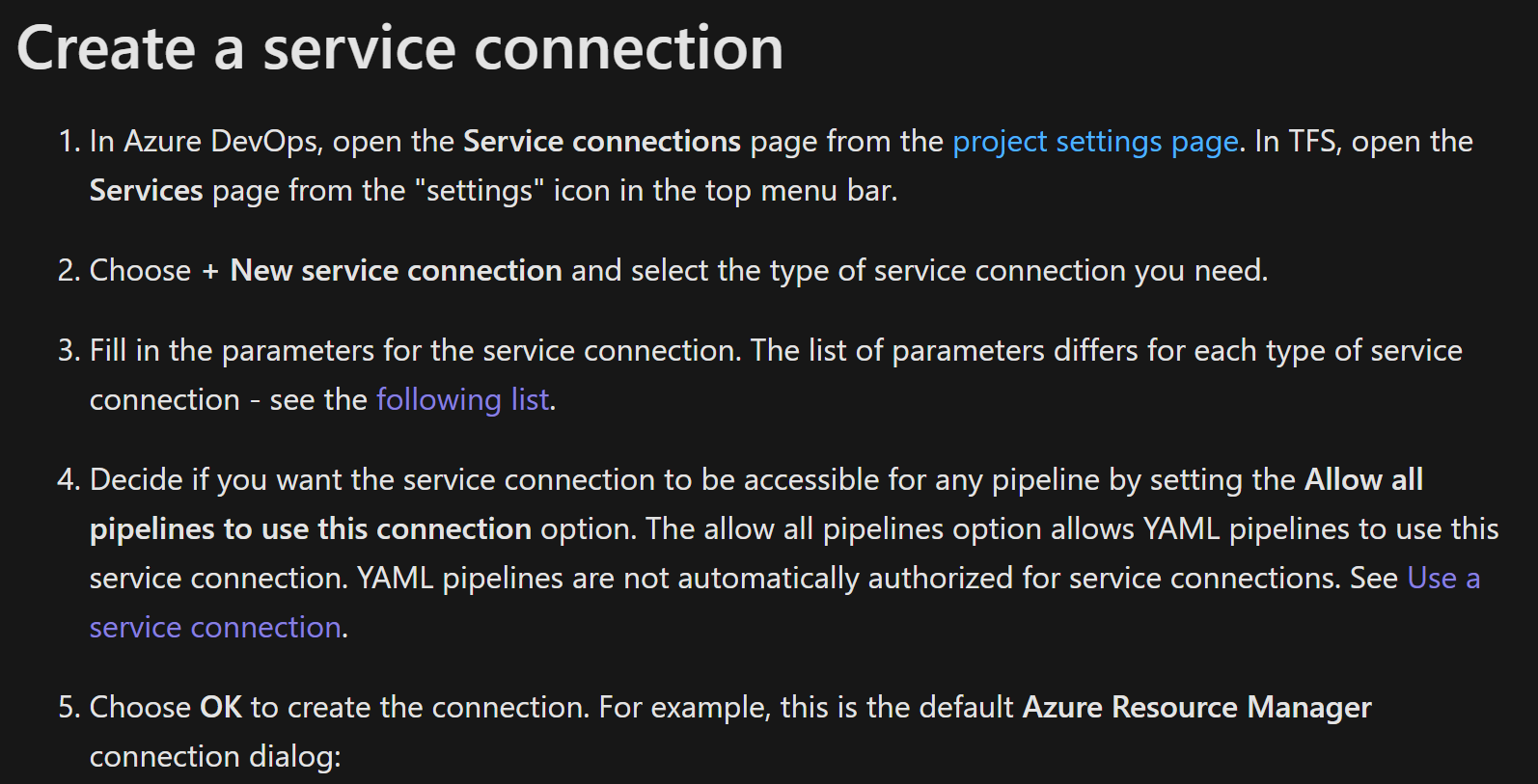
Create a new service connection in Azure DevOps using Azure Resource Manager. To avoid errors due to different namings, we recommend you to have a look at the variable the configuration file:
- For "Service connection" use the variable SERVICECONNECTION_RG
- For the "Subscription", select the one where you want to deploy your infrastructure
- Resource Group leave empty.
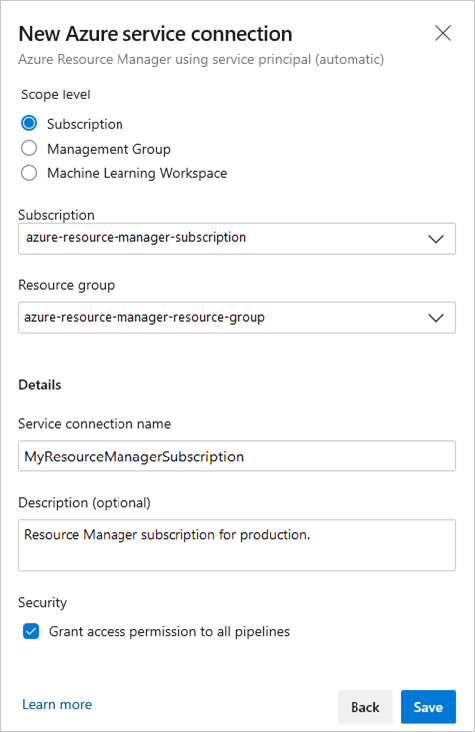 . Azure DevOps will authenticate using this connection to make deployments to your Azure Subscription. For more information about security and parameters, click on the prior link.
. Azure DevOps will authenticate using this connection to make deployments to your Azure Subscription. For more information about security and parameters, click on the prior link.
Run the pipeline
If you want to run the pipeline from your ADO repository, follow the steps bellow. If you want to import them directly from the github repo, have a look at the contribution guide
- Add the pipeline in ADO and run it. For that go to pipelines and click on new pipeline at the top right. You should see the following screen
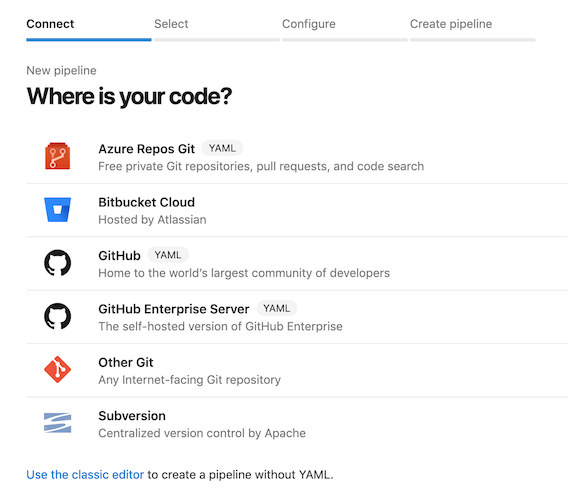
Select: Azure Repos Git, the name repo where you clone this repo, Existing Azure Pipelines YAML file option and set the path to /infrastructure/deploy-environment.template.yml and click on continue 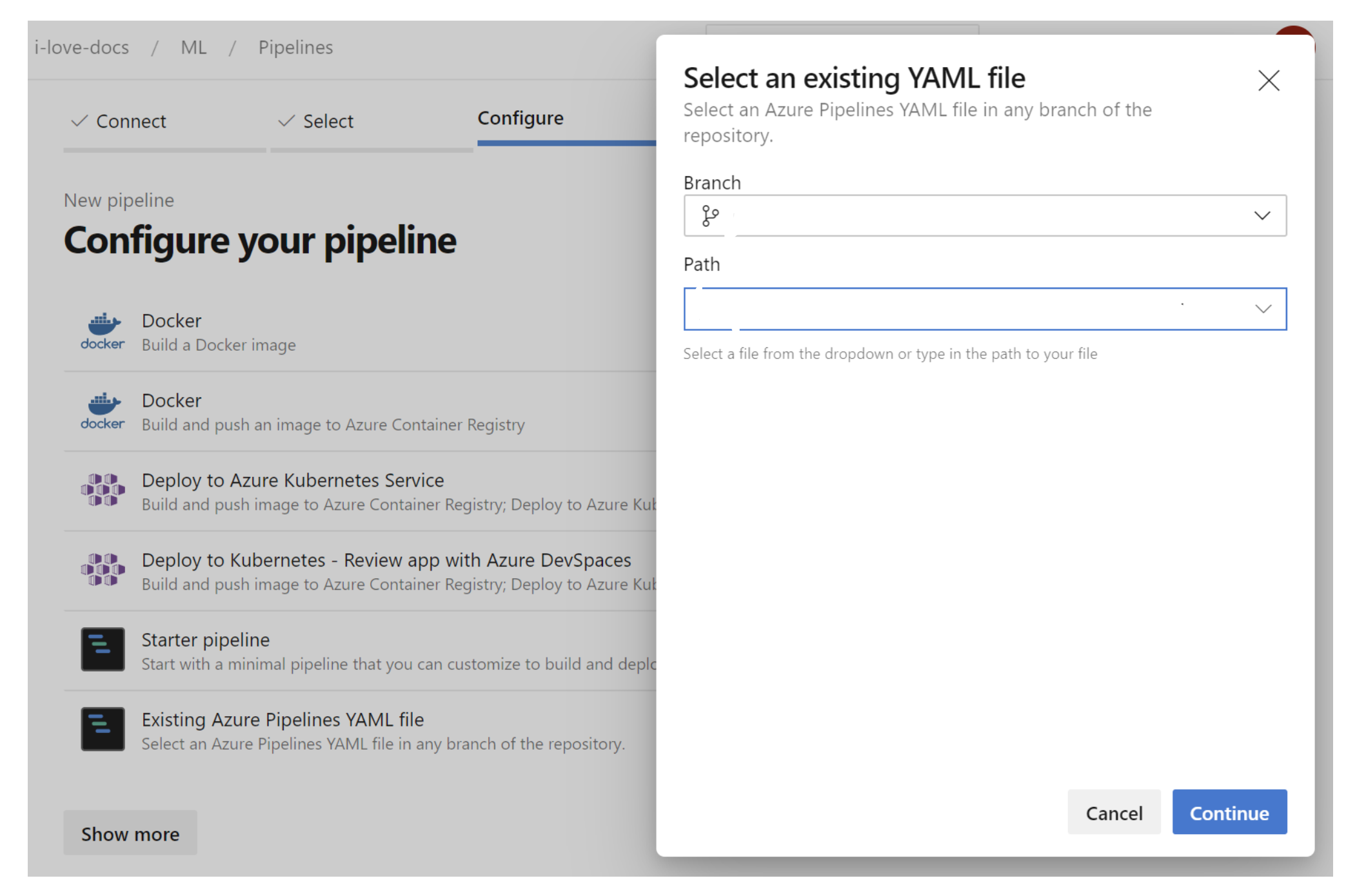 In the review section, click on run.
In the review section, click on run.
- If everything worked well, you should see your new resource groups in the Azure portal with the AML resources.
Set Service Connection for Azure ML Workspace
Now that you have your infrastructure, you only need to setup two extra service connections so that the devops pipeline can connect to AML DEV and AML PROD.
As for the infrastructure, create a new service connection with Azure Resource manager, but this time select "Machine Learning Workspace" as Scope level. 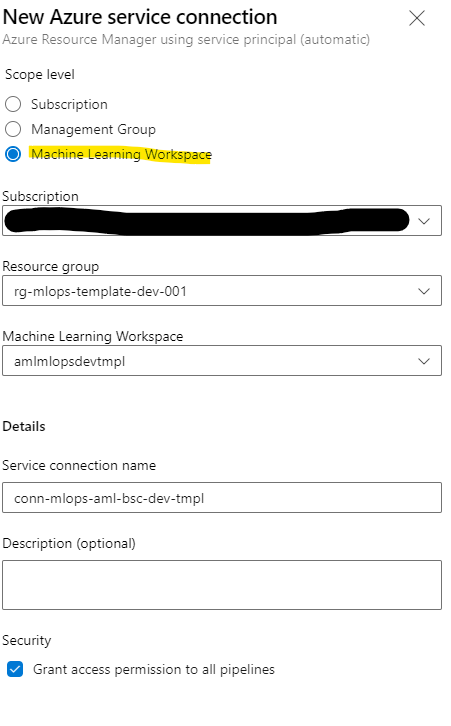
(Optional) Set your own variable names
You might want to use your own variables when setting up the infrastructure, service connection, and AML components (dataset name, model name, etc). In order to the pipeline to run with the correct variable name, you need to update the following configuration files:
- infra-related variables: contains the definition of infra-related variables in DEV. By default, the template provides 2 environments: DEV (configuration-infra-DEV.variables.yml) and PRD (configuration-infra-PRD.variables.yml)
ENVIRONMENT: Name of environment. We use uppercase DEV, TEST, PRD to refer to environments
RESOURCE_GROUP: Name of the resourceGroup to create in this environment
LOCATION: Location for the resourceGroup in this environment
NAMESPACE: Namespace in this environment (use to identify and refer to the name of resources used in this environment).
SERVICECONNECTION_RG: Name of the Service Connection in Azure DevOps in subscription scope level
SERVICECONNECTION_WS: Name of the Service Connection in Azure DevOps in machine learning workspace scope level for this environment
AMLWORKSPACE: Name of the azure machine learning workspace in this environment. Default name is aml$(NAMESPACE)
STORAGEACCOUNT: Name of the storage account. Default name is sa$(NAMESPACE)
KEYVAULT: Name of the key vault. Default name is kv$(NAMESPACE)
APPINSIGHTS: Name of the app insight. Default name is ai$(NAMESPACE)
CONTAINERREGISTRY: Name of the container registry. Default name is cr$(NAMESPACE)
- AML-related variables: contains the definition of AML-related environment variables
PYTHON_VERSION: the version of python. Default value is 3.8
SDK_VERSION: the version of Azure ML SDK. Default value is 1.35
AML_DATASET: training dataset name.
AML_MODEL_NAME: model name (use in model register)
# Training
TRAINING_EXPERIMENT: training experiment name
TRAINING_PIPELINE: training pipeline name
TRAINING_COMPUTE: training computes name
# Batch inference
BATCHINFERENCE_EXPERIMENT: batch inference experiment name
BATCHINFERENCE_PIPELINE: batch inference pipeline name
BATCHINFERENCE_COMPUTE: batch inference compute name. Default name is $(TRAINING_COMPUTE)
# Real-time inference
AKS_COMPUTE: inference target name
AML_WEBSERVICE: webservice name
Further Reading
If you want to have setup a branching strategy, you can read branchingstrat and if you want to investigate further the infrastructure have a look at infradesign