Presidio Image Redactor
Please notice, this package is still in beta and not production ready.
Description
The Presidio Image Redactor is a Python based module for detecting and redacting PII
text entities in images.
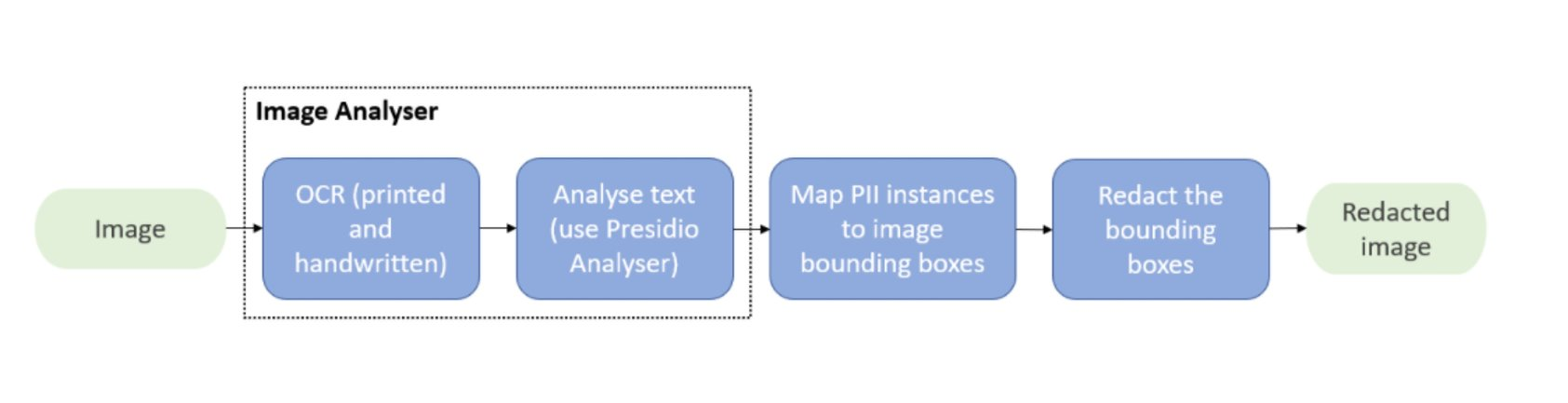
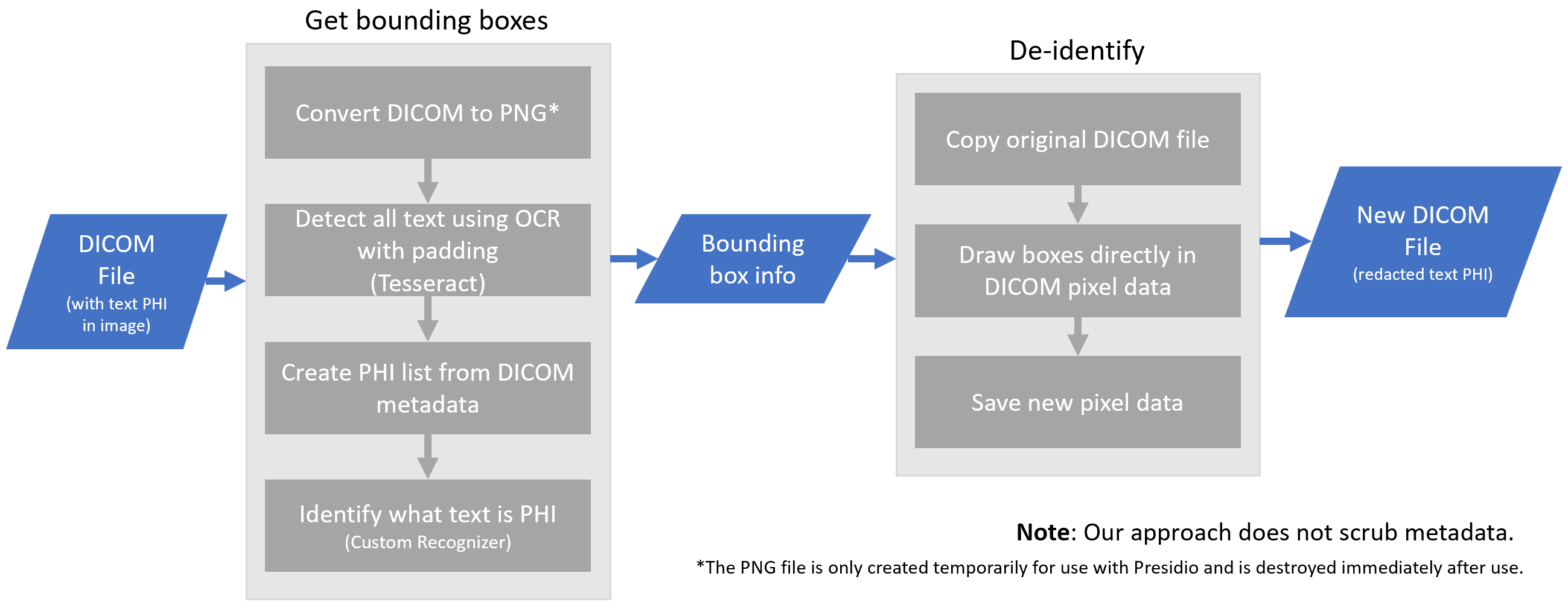
This module may also be used on medical DICOM images. The DicomImageRedactorEngine class may be used to redact text PII present as pixels in DICOM images.
Note
This class only redacts pixel data and does not scrub text PII which may exist in the DICOM metadata. We highly recommend using the DICOM image redactor engine to redact text from images BEFORE scrubbing metadata PII.*
Installation
Pre-requisites:
- Install Tesseract OCR by following the instructions on how to install it for your operating system.
Attention
For best performance, please use the most up-to-date version of Tesseract OCR. Presidio was tested with v5.2.0.
Note
Consider installing the Presidio python packages on a virtual environment like venv or conda.
To get started with Presidio-image-redactor,
download the package and the en_core_web_lg spaCy model:
pip install presidio-image-redactor
python -m spacy download en_core_web_lg
Note
This requires Docker to be installed. Download Docker.
# Download image from Dockerhub
docker pull mcr.microsoft.com/presidio-image-redactor
# Run the container with the default port
docker run -d -p 5003:3000 mcr.microsoft.com/presidio-image-redactor:latest
First, clone the Presidio repo. See here for instructions.
Then, build the presidio-image-redactor container:
cd presidio-image-redactor
docker build . -t presidio/presidio-image-redactor
Getting started (standard image types)
Once the Presidio-image-redactor package is installed, run this simple script:
from PIL import Image
from presidio_image_redactor import ImageRedactorEngine
# Get the image to redact using PIL lib (pillow)
image = Image.open("./docs/image-redactor/ocr_text.png")
# Initialize the engine
engine = ImageRedactorEngine()
# Redact the image with pink color
redacted_image = engine.redact(image, (255, 192, 203))
# Optional: Redact the image and return redacted regions
redacted_image, bboxes = engine.redact_and_return_bbox(image, (255, 192, 203))
# save the redacted image
redacted_image.save("new_image.png")
# uncomment to open the image for viewing
# redacted_image.show()
You can run presidio image redactor as an http server using either python runtime or using a docker container.
Using docker container
cd presidio-image-redactor
docker run -p 5003:3000 presidio-image-redactor
Using python runtime
Note
This requires the Presidio Github repository to be cloned.
cd presidio-image-redactor
python app.py
# use ocr_test.png as the image to redact, and 255 as the color fill.
# out.png is the new redacted image received from the server.
curl -XPOST "http://localhost:3000/redact" -H "content-type: multipart/form-data" -F "image=@ocr_test.png" -F "data=\"{'color_fill':'255'}\"" > out.png
Python script example can be found under: /presidio/e2e-tests/tests/test_image_redactor.py
Getting started (DICOM images)
Once the Presidio-image-redactor package is installed, run this simple script:
import pydicom
from presidio_image_redactor import DicomImageRedactorEngine
# Set input and output paths
input_path = "path/to/your/dicom/file.dcm"
output_dir = "./output"
# Initialize the engine
engine = DicomImageRedactorEngine()
# Option 1: Redact from a loaded DICOM image
dicom_image = pydicom.dcmread(input_path)
redacted_dicom_image = engine.redact(dicom_image, fill="contrast")
# Option 2: Redact from a loaded DICOM image and return redacted regions
redacted_dicom_image, bboxes = engine.redact_and_return_bbox(dicom_image, fill="contrast")
# Option 3: Redact from DICOM file and save redacted regions as json file
engine.redact_from_file(input_path, output_dir, padding_width=25, fill="contrast", save_bboxes=True)
# Option 4: Redact from directory and save redacted regions as json files
ocr_kwargs = {"ocr_threshold": 50}
engine.redact_from_directory("path/to/your/dicom", output_dir, fill="background", save_bboxes=True, ocr_kwargs=ocr_kwargs)
Getting started using the document intelligence OCR engine
Presidio offers two engines for OCR based PII removal. The first is the default engine which uses Tesseract OCR. The second is the Document Intelligence OCR engine which uses Azure's Document Intelligence service, which requires an Azure subscription. The following sections describe how to setup and use the Document Intelligence OCR engine.
You will need to register with Azure to get an API key and endpoint. Perform the steps in the "Prerequisites" section of this page. Once your resource deploys, copy your endpoint and key values and save them for the next step.
The most basic usage of the engine can be setup like the following in python
diOCR = DocumentIntelligenceOCR(endpoint="<your_endpoint>", key="<your_key>")
The DocumentIntelligenceOCR can also attempt to pull your endpoint and key values from environment variables.
export DOCUMENT_INTELLIGENCE_ENDPOINT=<your_endpoint>
export DOCUMENT_INTELLIGENCE_KEY=<your_key>
Document Intelligence Model Support
There are numerous document processing models available, and currently we only support the most basic usage of the model. For an overview of the functionalities offered by Document Intelligence, see this page. Presidio offers only word-level processing on the result for PII redaction purposes, as all prebuilt document models support this interface. Different models support additional structured support for tables, paragraphs, key-value pairs, fields and other types of metadata in the response.
Additional metadata can be sent to the Document Intelligence API call, such as pages, locale, and features, which are documented here. You are encouraged to test each model to see which fits best to your use case.
Creating an image redactor engine in Python
diOCR = DocumentIntelligenceOCR()
ia_engine = ImageAnalyzerEngine(ocr=di_ocr)
my_engine = ImageRedactorEngine(image_analyzer_engine=ia_engine)
Testing Document Intelligence
Follow the steps of running the tests
The test suite has a series of tests which are only exercised when the appropriate environment variables are populated. To run the test suite, to test the DocumentIntelligenceOCR engine, call the tests like this:
export DOCUMENT_INTELLIGENCE_ENDPOINT=<your_endpoint>
export DOCUMENT_INTELLIGENCE_KEY=<your_key>
pytest
Evaluating de-identification performance
If you are interested in evaluating the performance of the DICOM de-identification against ground truth labels, please see the evaluating DICOM de-identification page.
Side note for Windows
If you are using a Windows machine, you may run into issues if file paths are too long. Unfortunately, this is not rare when working with DICOM images that are often nested in directories with descriptive names.
To avoid errors where the code may not recognize a path as existing due to the length of the characters in the file path, please enable long paths on your system.
DICOM Data Citation
The DICOM data used for unit and integration testing for DicomImageRedactorEngine are stored in this repository with permission from the original dataset owners. Please see the dataset information as follows:
Rutherford, M., Mun, S.K., Levine, B., Bennett, W.C., Smith, K., Farmer, P., Jarosz, J., Wagner, U., Farahani, K., Prior, F. (2021). A DICOM dataset for evaluation of medical image de-identification (Pseudo-PHI-DICOM-Data) [Data set]. The Cancer Imaging Archive. DOI: https://doi.org/10.7937/s17z-r072
API reference
the API Spec for the Image Redactor REST API reference details and Image Redactor Python API for Python API reference