Task 2.2: Create a Delta Live Table pipeline
In this task, you can create a Delta Live Table pipeline.
Delta Live Tables (DLT) allow you to build and manage reliable data pipelines that deliver high-quality data in Lakehouse. DLT helps data engineering teams simplify ETL development and management with declarative pipeline development, automatic data testing, and deep visibility for monitoring and recovery.
After mounting the OneLake location, it’s time to convert the raw bronze files into the open standard delta parquet format, supported by OneLake.
This can be done using any Spark compute either in Microsoft Fabric or Azure Databricks. In this lab you will use DLT pipelines to process the raw data from OneLake and store it back in Open Delta tables (Bronze>Silver>Gold Layer).
-
Select the Workflows icon in the left navigation pane.
-
Select the Delta Live Tables tab and select Create pipeline.
-
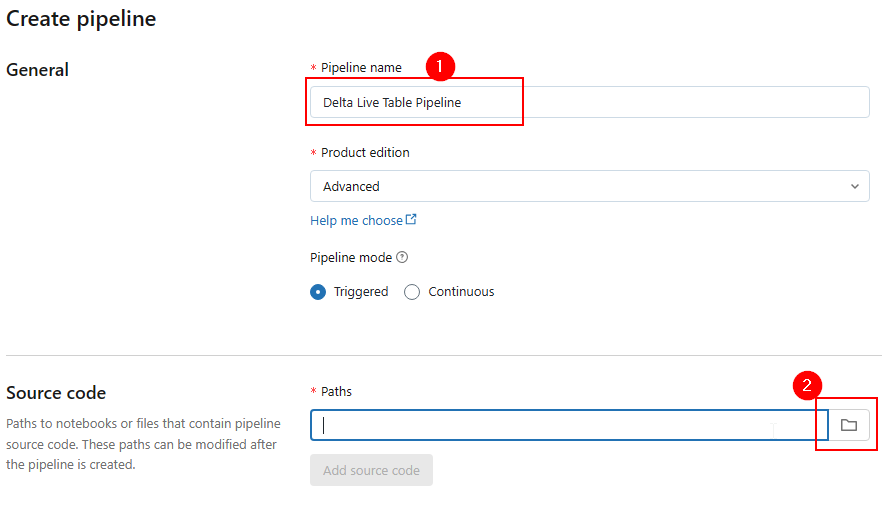
In the Create pipeline window, in the Pipeline name box, enter Delta Live Table Pipeline.
-
In the Source Code box, select the notebook icon.
-
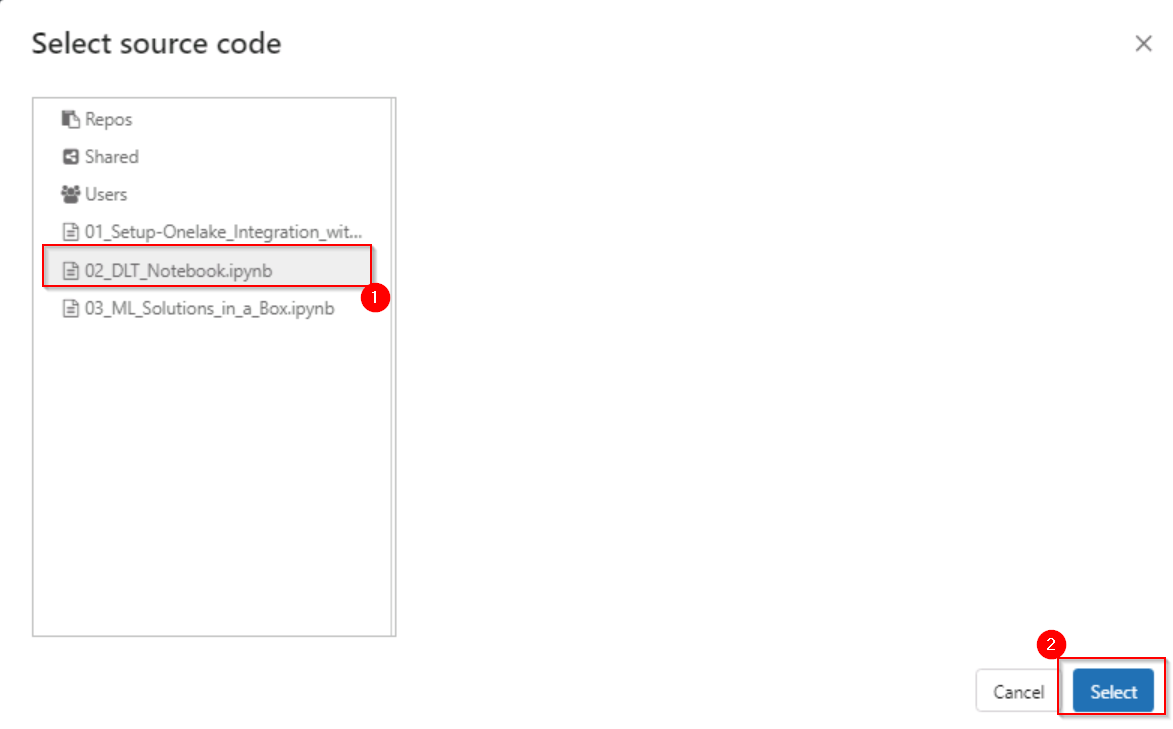
In the Select source code window, select the 02_DLT_Notebook.ipynb notebook and select Select.
-
Select Create.
After you select Create, the Delta Live Table pipeline with all the notebook libraries added to the pipeline will be created.
-
Select Start.
Databricks will start executing the pipeline which will take approximately 5 minutes.
-
Observe the data lineage of bronze, silver and gold tables.