Application Workflows
Two workflows explain most of the system behavior: how user prompts are screened, and how uploaded files become searchable context for grounded chat.
These flows are the fastest way to understand where Simple Chat applies safety checks, where Azure services participate, and where document-grounded answers actually come from.
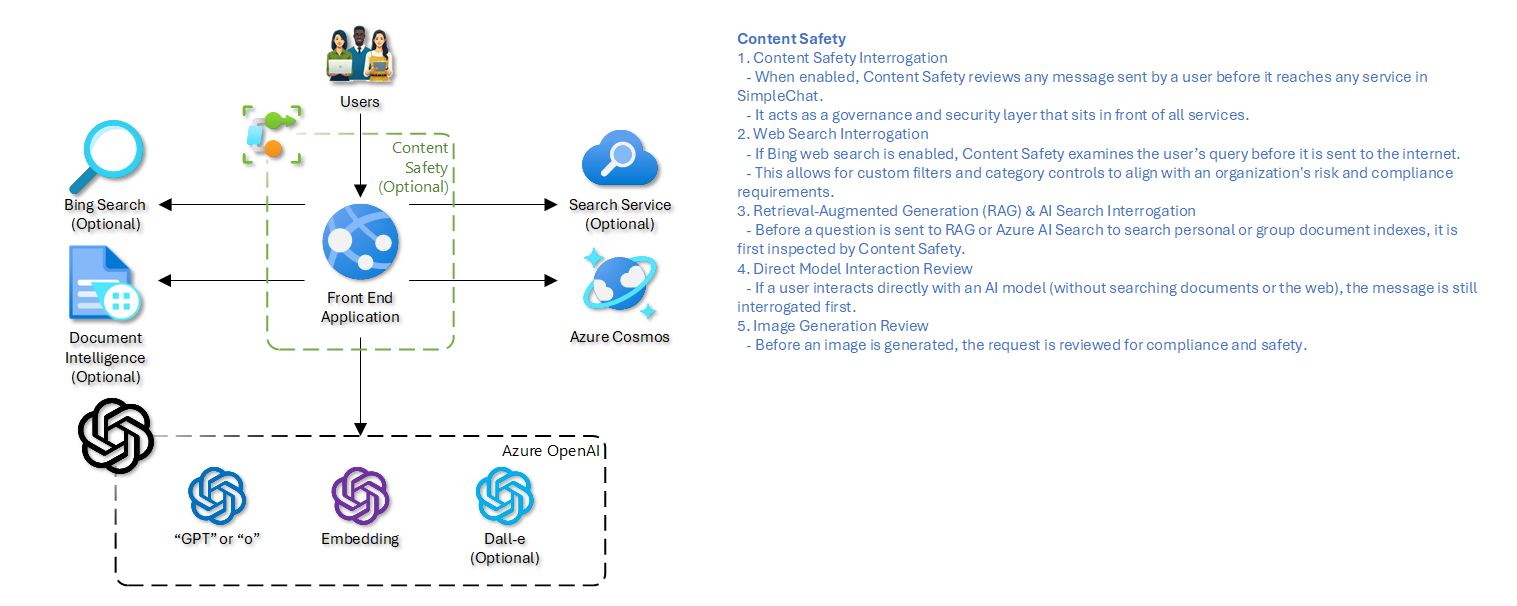
Content Safety
User prompts can be screened before the system touches retrieval, direct model calls, or image generation. Unsafe prompts are blocked before they propagate.
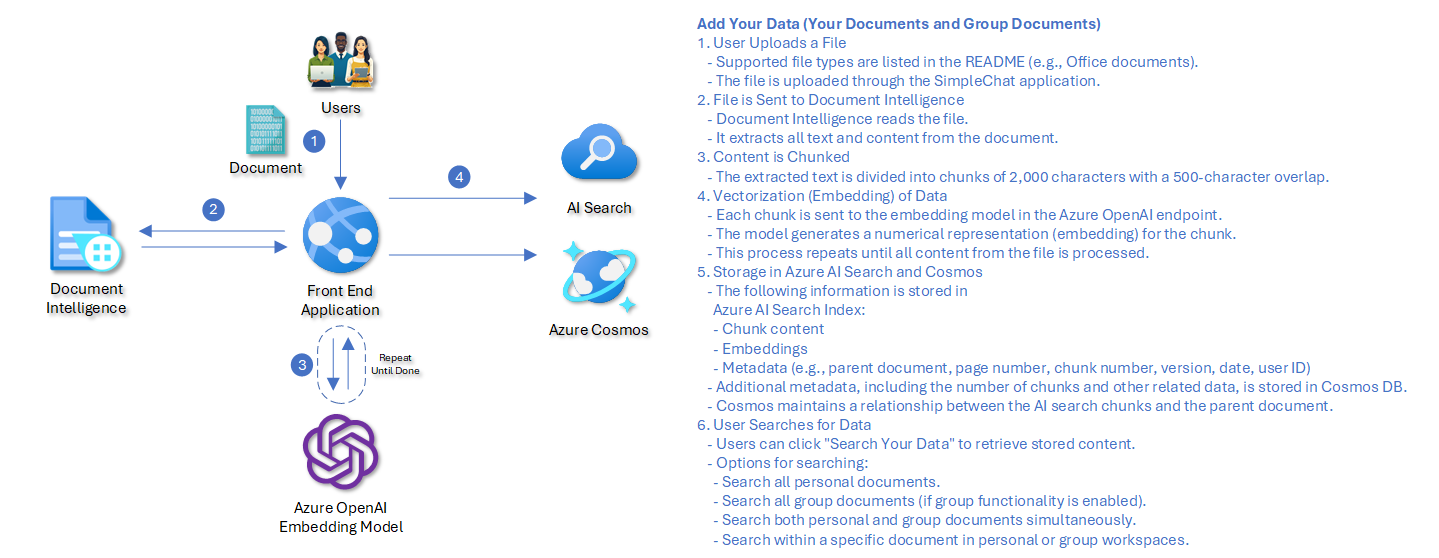
Add Your Data
Uploads are extracted, chunked, embedded, and indexed so chat can retrieve the right fragments later with citations and metadata.
Why these two flows matter
The first flow protects the front door. The second flow determines whether retrieval answers are useful, traceable, and fast. Most production issues map back to one of these two paths.
Content Safety Workflow
- A user sends a message from the chat interface.
- If Content Safety is enabled, the message is evaluated before it reaches the target backend service.
- Azure AI Content Safety evaluates configured categories such as hate, sexual content, violence, and self-harm, and can also apply custom blocklists.
- If the message passes, the system routes it to the intended destination.
- If the message fails, the request is blocked and the user receives a generic notification. Details can be logged for administrators when that feature is enabled.
When a prompt is considered safe, it can continue into one of several paths:
- Retrieval-backed chat that queries Azure AI Search.
- Direct GPT interaction against Azure OpenAI.
- Image generation against a configured DALL-E deployment.
The default flow protects the inbound user message. Downstream services may still apply their own filtering behavior after that point.
Add Your Data Workflow
This workflow covers what happens when users upload content into personal or group workspaces for Retrieval-Augmented Generation.
- Users upload one or more supported files through the application UI.
- The backend determines file type and chooses the correct extraction path.
- Text is extracted through Azure AI Document Intelligence, Azure Video Indexer, Azure Speech Service, or internal parsers depending on the content type.
- Extracted content is chunked into retrieval-friendly segments while preserving structural context such as pages, timestamps, tables, or sequence.
- Each chunk is embedded through the configured Azure OpenAI embedding model.
- The chunk text, embedding vector, and retrieval metadata are written to Azure AI Search.
- Parent document records and processing metadata are written to Cosmos DB so the system can relate the original file to its indexed chunks.
- Once indexing completes, the document becomes available to hybrid retrieval in chat and workspace search.
Typical chunk metadata includes document identity, filename, workspace scope, sequence numbers, page references, timestamps, and optional classification or extraction metadata.