Comparison with “traditional” simulation models
Some qualities of a traditional simulation model:
-
Built with predefined internal logic and rules that govern its behavior
-
May have some parameters (inputs) that can be used to setup different scenarios or starting conditions
-
Have experiments built as a layer on top of the simulation model, allowing it to be used for different types of analysis
These experiments work by first setting some parameters (if any exist), then executing the model, waiting until it signals its completion, then retrieves and handles relevant outputs. The experiments operate not knowing (and not needing to know) anything that happens during a simulation run, only outside of it. In this way, the model is independent from the experiment and treated as a “black box”.
In contrast, the RL-ready model is not useful by itself, as it delegates at least some of the decisions made within its logic to an external algorithm. In doing so, it loses its independence, as it periodically needs pause its execution to expose itself to the algorithm and then apply some decision made by it, before continuing with its execution. Its purpose has thus shifted to be a simulation environment for which an AI algorithm can learn within.
Similar to experiments with traditional simulation models - where many runs are often required to achieve optimal results - it is very unlikely that the RL algorithm can learn anything meaningful within one simulation run. A fruitful training usually involves hundreds, thousands, or even millions of simulation runs. In doing so, the RL algorithm can gain enough experience to optimally control the environment.
Flow of Communication
Where a simulation run with traditional models only require parameters to be assigned at the start, models intended for RL training also require interaction with the RL algorithms during a simulation run.
The flow of communication between simulation model and the platform works as the following image depicts.
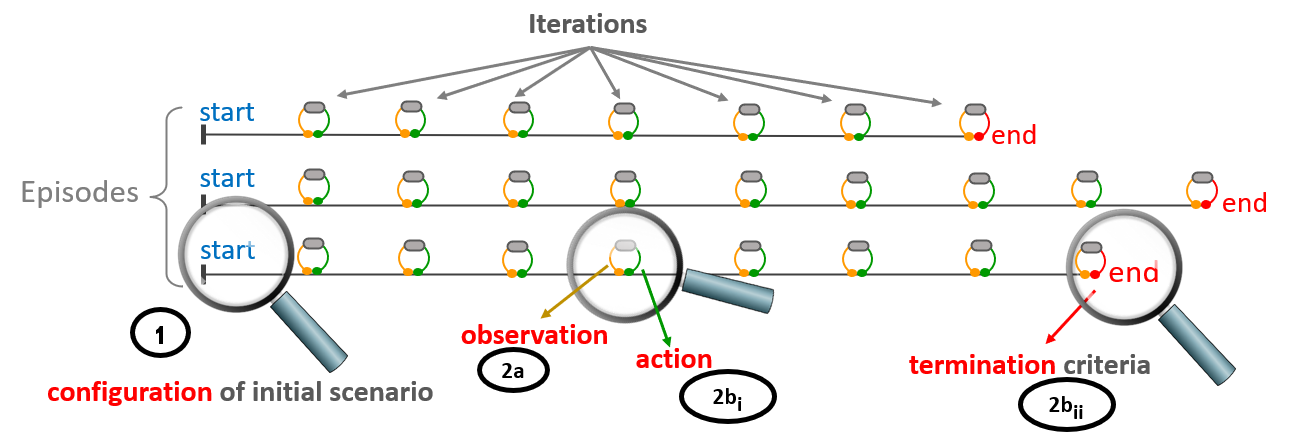
-
At the start of each episode, the model will be sent an optional, user-defined configuration. The user’s configuration code - if setup - will set parameter values and execute other startup operations (setting default values).
After the configuration is set, the model will begin executing under its own internal set of rules.
-
At certain user-defined decision points within the simulation’s run, an iteration will be triggered.
Note: The use of ‘iteration’ here is entirely distinct from AnyLogic’s usage of the word.In an iteration, the simulation run will be paused while the following happens:
a. An observation will be sent to the platform
The platform will then process the observation through the RL algorithms and the training regimen. During this time, the simulation model waits for a response.
b. The platform will then send one of two replies to the simulation model:
i. An action. After the model applies the described action, it will continue its run normally.
ii. A terminal message. This happens based on certain conditions as described in the user’s training regimen. The simulation run will then stop and a new one will begin.