Anonymize PII entities in datasets using Azure Data Factory template and Presidio on Databricks
This sample uses the built in data anonymization template of Azure Data Factory (which is a part of the Template Gallery) to copy a csv dataset from one location to another, while anonymizing PII data from a text column in the dataset. It leverages the code for using Presidio on Azure Databricks to call Presidio as a Databricks notebook job in the Azure Data Factory (ADF) pipeline to transform the input dataset before merging the results to an Azure Blob Storage.
Note that this solution is capable of transforming large datasets. For smaller, text based input you may want to work with the Data Anonymization with Presidio as an HTTP service template which offers an easier deployment for Presidio.
The sample deploys the following Azure Services:
- Azure Storage - The target storage account where data will be persisted.
- Azure Databricks - Host presidio to anonymize the data.
Additionally you should already have an instance of Azure Data Factory which hosts and orchestrates the transformation pipeline and a storage account which holds the source files.
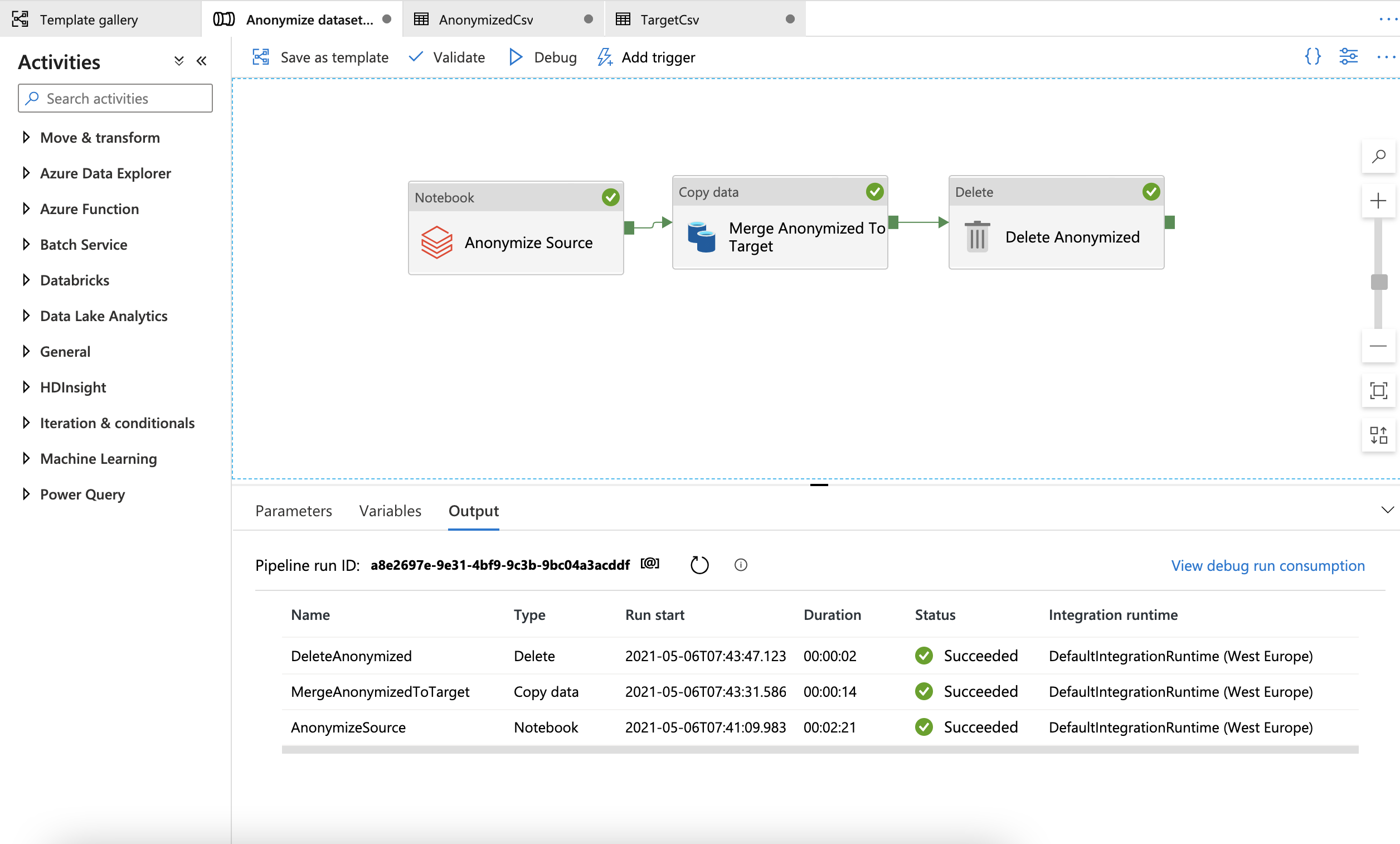
About this Solution Template
This template gets the files from your source file-based store. It then anonymizes the content and uploads each of them to the destination store.
The template contains three activities:
- AnonymizeSource runs the presidio notebook on the input file to create an output folder with csv parts.
- MergeAnonymizedToTarget merges the csv parts from databricks output folder to a single csv on the target storage container.
- DeleteAnonymized deletes the temporary output folder.
The template defines four parameters:
- SourceStore_Location is the container name of your source store where you want to move files from (STORAGE_CONTAINER_NAME).
- DestinationStore_Name is the container name in the target storage account which is provisioned by the ARM template.
- SourceFile_Name is the name of the input file.
- TextColumn_Name is the name of the column to be anonymized.
How to use this Solution Template
To use this template you should first setup the required infrastructure for the sample to run, then setup the template in Azure Data Factory.
Setup Presidio
Provision and setup the databricks cluster by following the Deploy and Setup steps in presidio-spark sample. Take a note of the authentication token and do not follow the "Running the sample" steps.
Setup Azure Data Factory
-
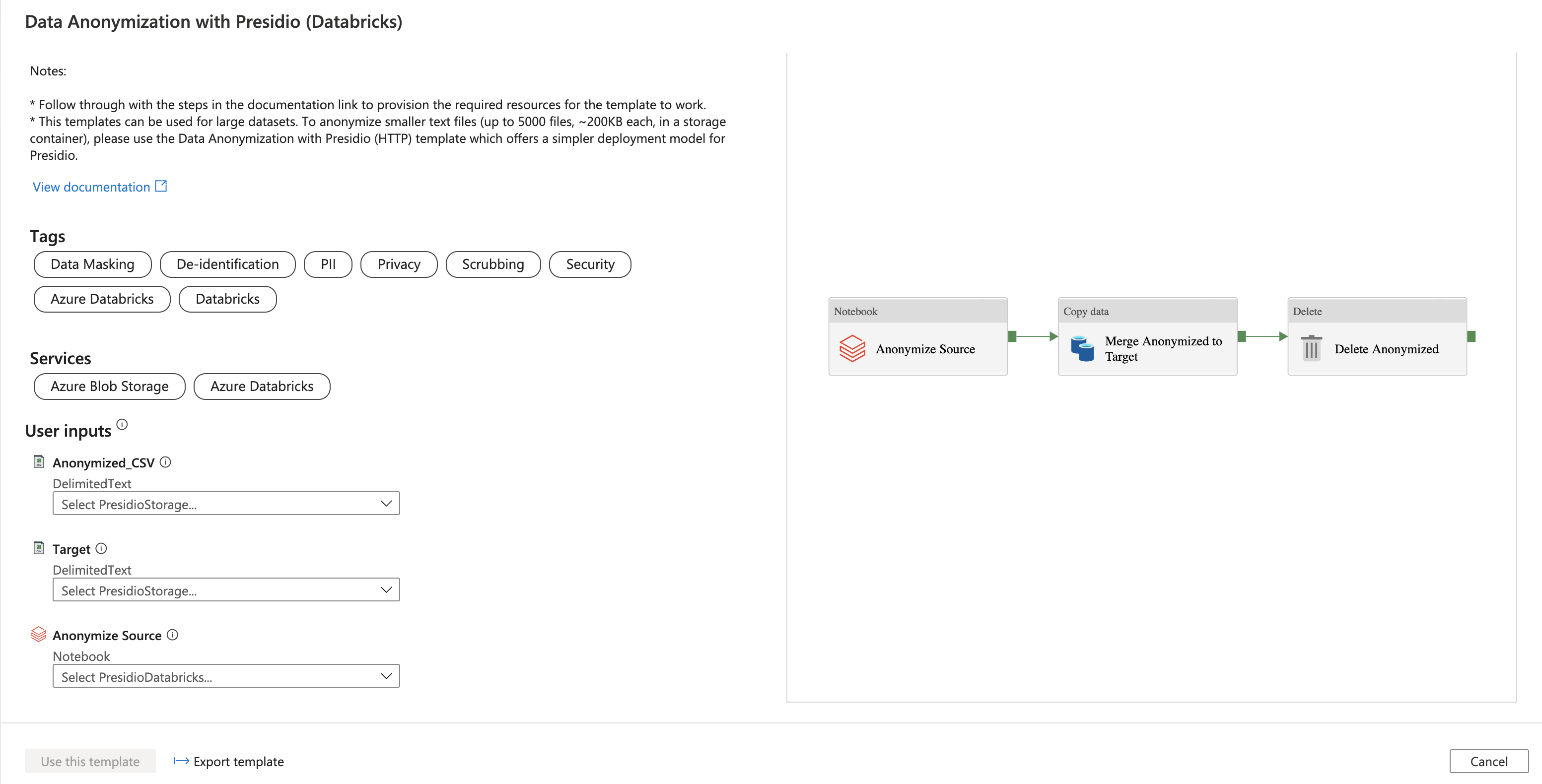
Go to the Data anonymization with Presidio on Databricks template. Select the AnonymizedCSV connection (Azure Storage) and select "New" from the drop down menu.
-
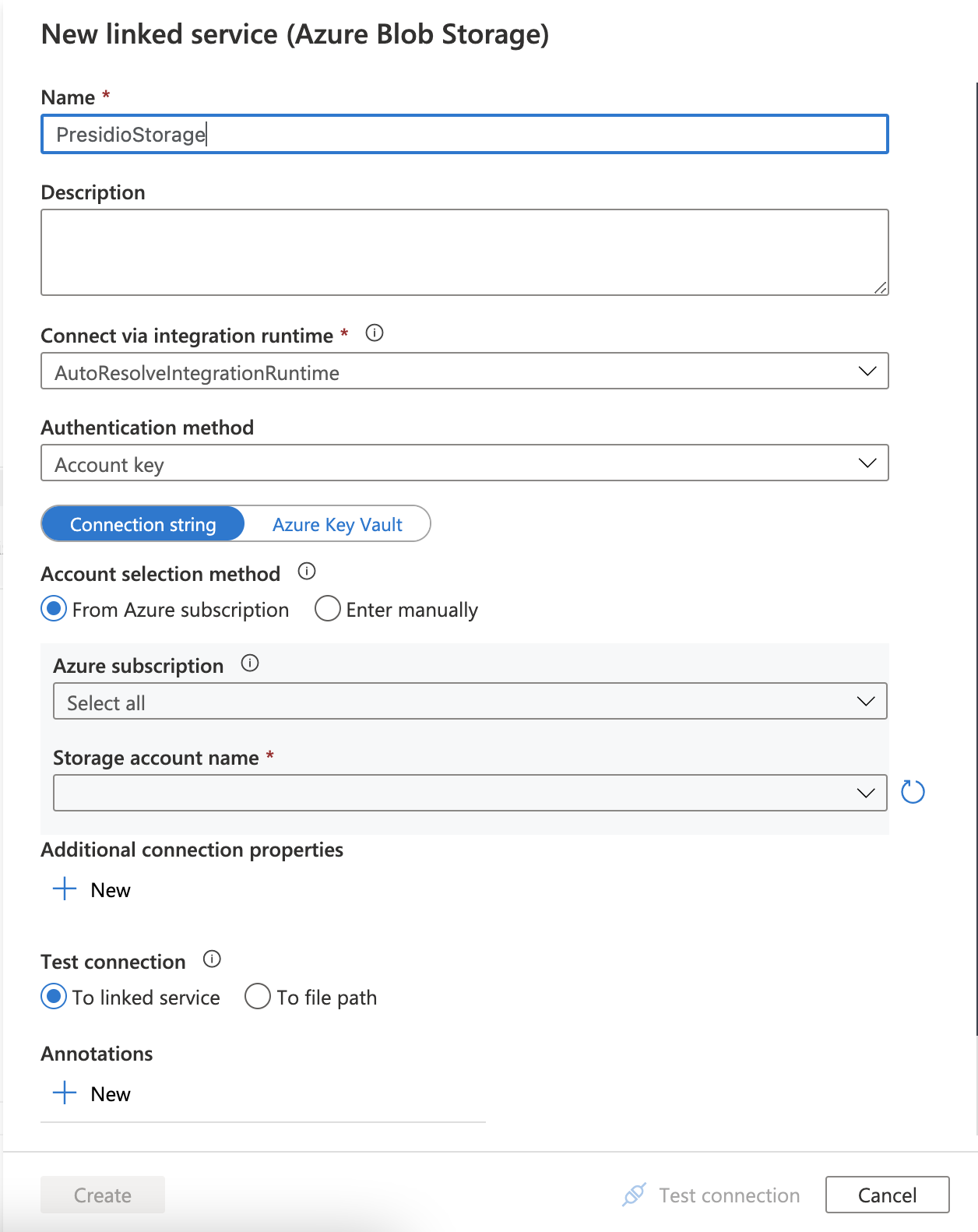
Name the service "PresidioStorage" and select the storage account that was created in the previous steps from your subscription. Note that Target source was also selected as the sample uses the same storage account for both source and target.
-
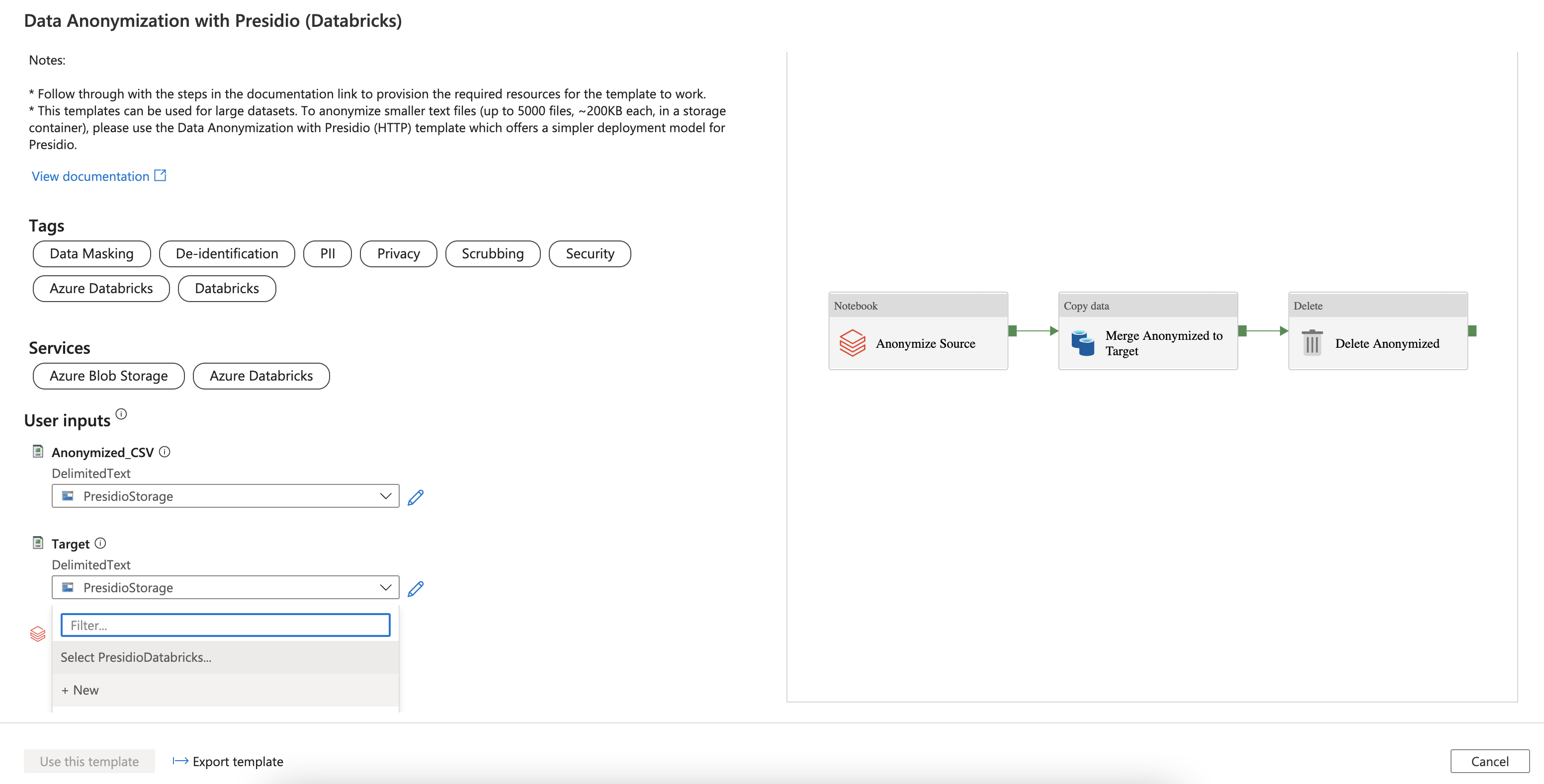
Select the Anonymize Source connection (Databricks) and select "New" from the drop down menu.
-
Name the service "PresidioDatabricks" and select the Azure Databricks workspace that was created in the previous steps from your subscription. Follow through the steps to input the authentication token which was generated in the previous step, or create a new one by following this guide. Select presidio_cluster to run the job.
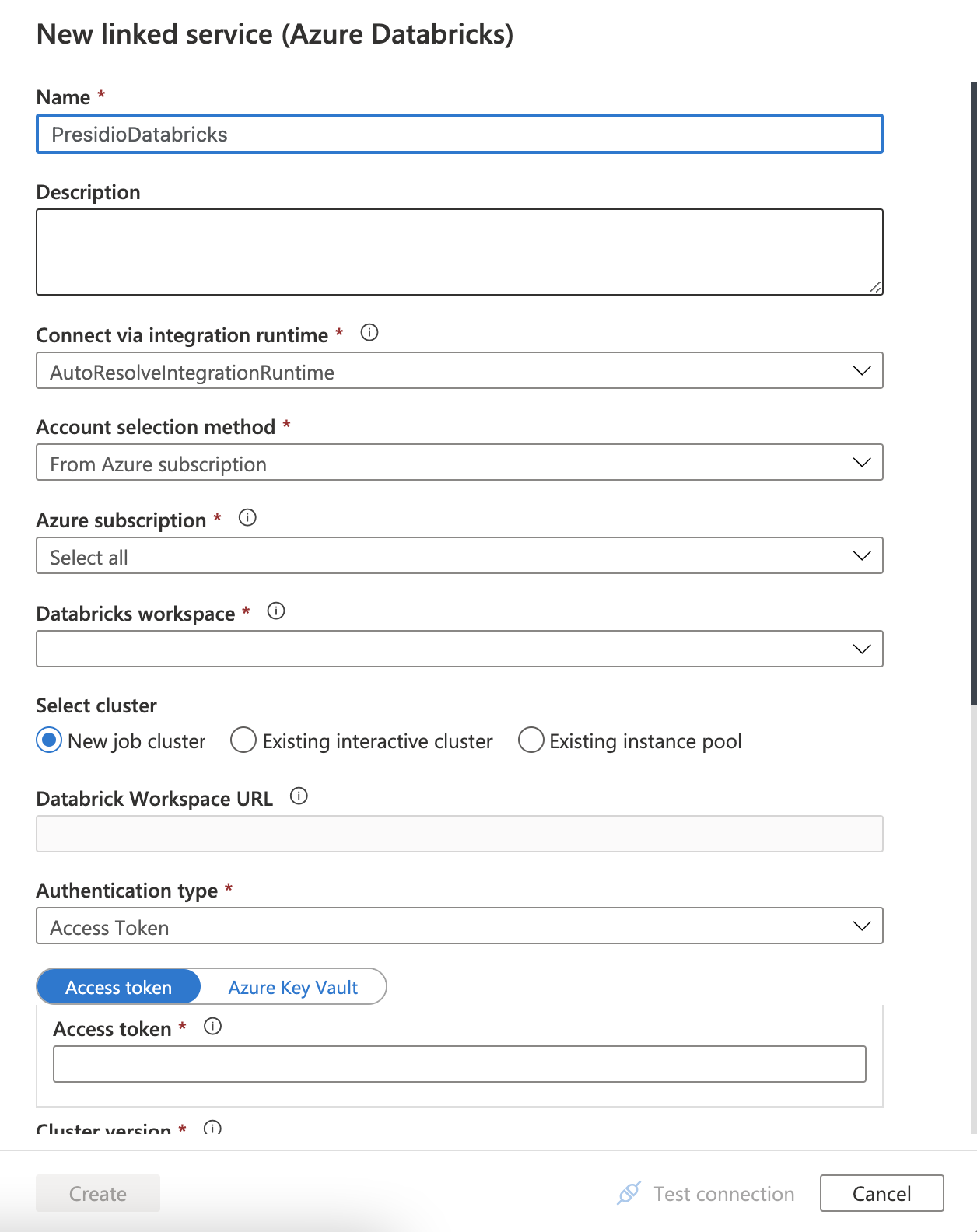
-
Select Use this template tab
-
You'll see the pipeline, as in the following example:
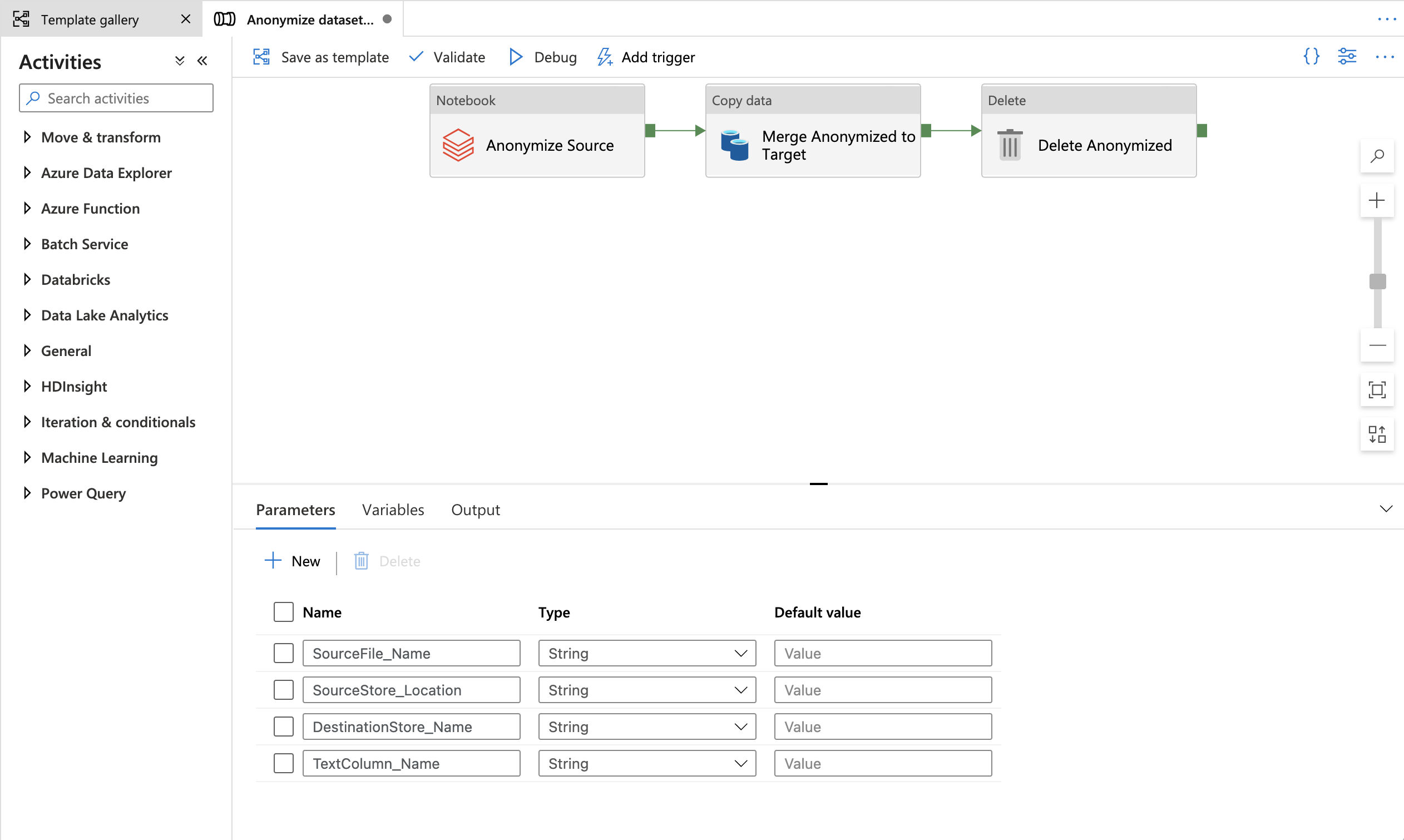
-
Upload a csv file to the storage container and select Debug, enter the Parameters, and then select Finish. The parameters are the container where you want to move files from, the container name where you want to move the anonymized files to, the csv file name and the name of a text column in the csv file.
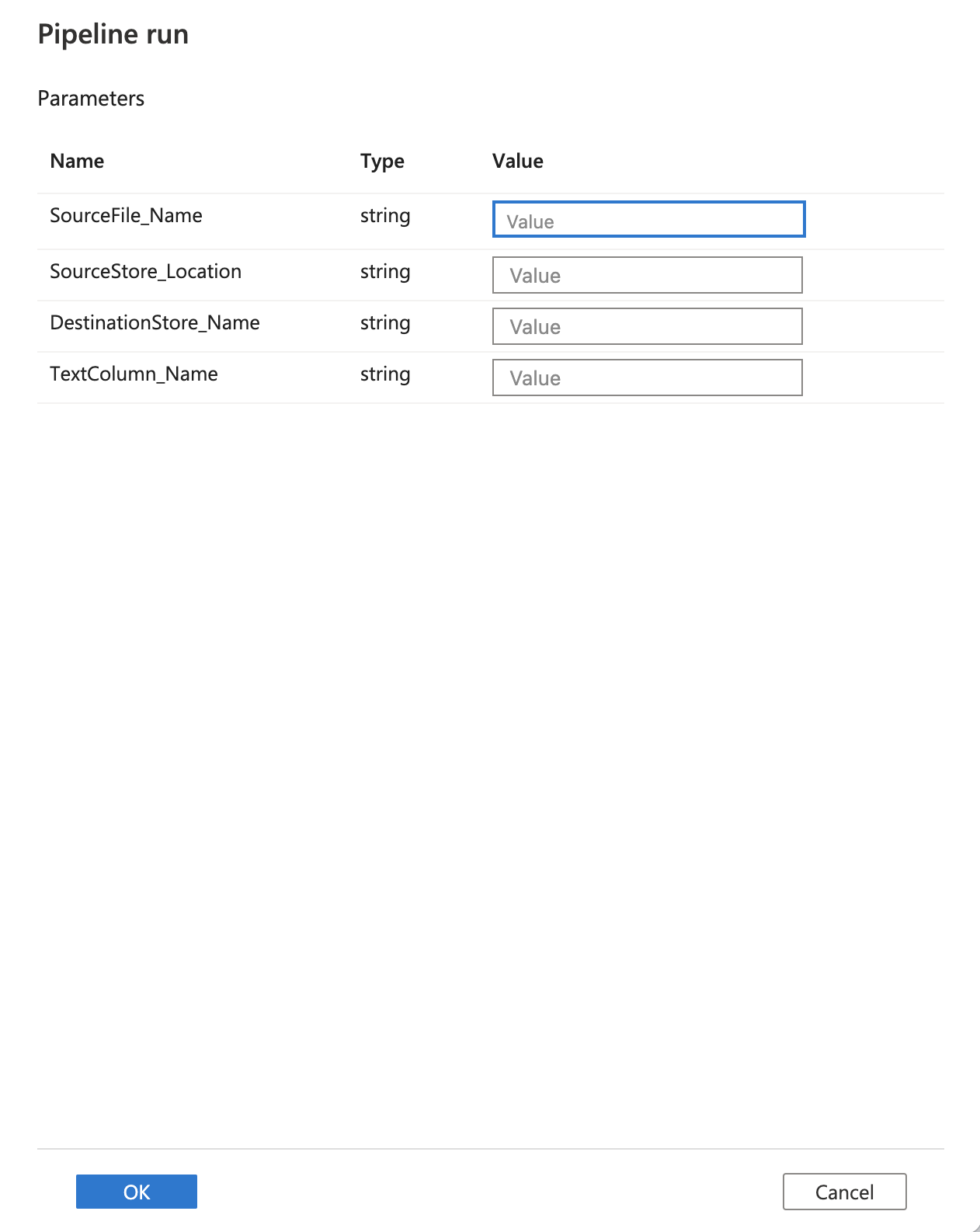
-
Review the result.