Task 02: Implement the Semantic Kernel
Introduction
CWBC’s Intelligent Assistant must provide quick, intelligent responses for users asking about bike models, maintenance, and route tips. By integrating Semantic Kernel, you’ll orchestrate calls to Azure OpenAI, turning the placeholders into real completions—key to meeting CWBC’s advanced customer-service goals.
Description
In this task, you’ll implement the Semantic Kernel Service to generate real responses from Azure OpenAI.
Semantic Kernel is an open-source SDK for LLM orchestration created by Microsoft Research. It lets you easily build agents that can call your existing code. As a highly extensible SDK, you can use Semantic Kernel with models from OpenAI, Azure OpenAI, Hugging Face, and more! You can also connect it to various vector databases using built-in connectors, including Azure Cosmos DB.
By combining your existing code with these models, you can build agents that answer questions and automate processes.
Success criteria
- You successfully replaced placeholder responses with real outputs generated by GPT from Azure OpenAI.
- You ensured that the application compiles and runs smoothly, confirming that your integration of the Semantic Kernel is correct.
Learning resources
Key tasks
01: Add the OpenAI Chat Completion extension
Expand this section to view the solution
To start, CWBC wants the Intelligent Assistant to handle user questions like “Which bikes are best for commuting?” You’ll enable Azure OpenAI’s Chat Completion to generate answers, the basis for advanced capabilities like context awareness. In this task, you’ll use two Semantic Kernel OpenAI Service Extensions and the Semantic Kernel Azure Cosmos DB NoSQL Vector Store connector. You’ll start by adding the OpenAI Chat Completion extension to generate responses from the LLM.
-
Within the project folder in Visual Studio Code, find and open the file:
src/cosmos-copilot.WebApp/Services/`SemanticKernelService.cs:
-
Select Ctrl+F to find the public SemanticKernelService constructor with the following signature:
public SemanticKernelService(OpenAIClient openAiClient, CosmosClient cosmosClient, IOptions<OpenAi> openAIOptions, IOptions<CosmosDb> cosmosOptions)
-
Select Ctrl+F to find the line containing var builder = Kernel.CreateBuilder(); within that constructor.
-
Below this line, add the extension for OpenAI chat completions:
// Add Azure OpenAI chat completion service builder.AddOpenAIChatCompletion(modelId: completionDeploymentName, openAIClient: openAiClient);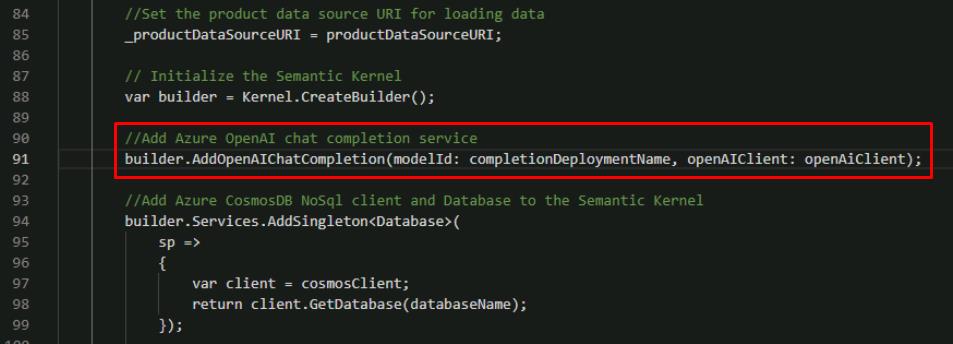
The builder with this new line will initialize and inject a built-in service from OpenAI. Chat Completion refers to response generation from a GPT model.
This task requires copying code from the instructions into Visual Studio Code. For proper formatting while copying code blocks longer than one line, you’ll need to manually indent the subsequent lines of code. Multiple lines can be selected and indented at once.
02: Generate chat completion
Expand this section to view the solution
After wiring up chat completion, you can finally replace placeholder text with actual GPT outputs. This is the first time your Intelligent Assistant answers real questions, showcasing the AI-driven heart of CWBC’s new approach to bike support.
-
In the same file, find line containing the GetChatCompletionAsync`() method.
-
Within the method, below the line for var skChatHistory, add a new line to add the _systemPrompt value as a system message.
skChatHistory.AddSystemMessage(_systemPrompt);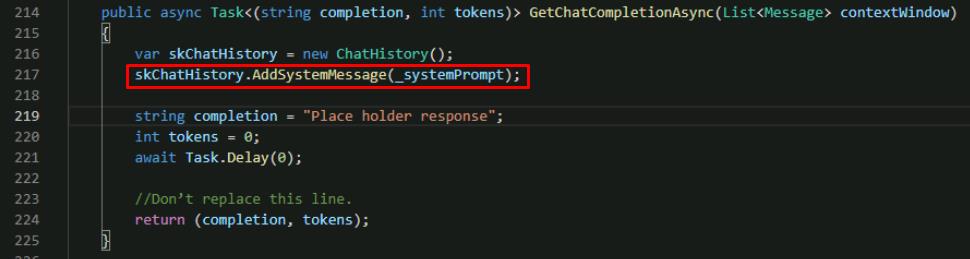
You can find the _systemPrompt definition at the top of the SemanticKernelService.cs file. The system prompt instructs the LLM how to respond and allows developers to guide the model depending on their use case.
-
Directly below the system message you added, add a foreach loop to prepare messages from the user to be sent to the LLM.
foreach (var message in contextWindow) { skChatHistory.AddUserMessage(message.Prompt); if (message.Completion != string.Empty) skChatHistory.AddAssistantMessage(message.Completion); }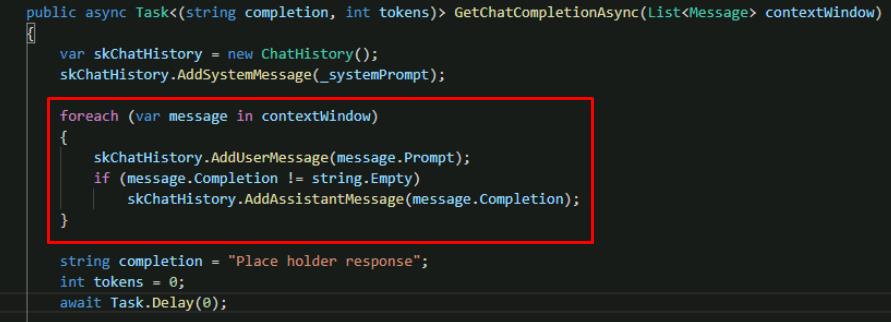
You’ll get to know why this is a List object in a future exercise. At this point, it only contains a single user prompt.
-
Comment out the next three lines of code (string, int, and await), below the foreach loop, with the following:
//string completion = "Place holder response"; //int tokens = 0; //await Task.Delay(0); PromptExecutionSettings settings = new() { ExtensionData = new Dictionary<string, object>() { { "temperature", 0.2 }, { "top_p", 0.7 }, { "max_tokens", 1000 } } }; var result = await kernel.GetRequiredService<IChatCompletionService>().GetChatMessageContentAsync(skChatHistory, settings); ChatTokenUsage completionUsage = (ChatTokenUsage)result.Metadata!["Usage"]!; string completion = result.Items[0].ToString()!; int tokens = completionUsage.OutputTokenCount;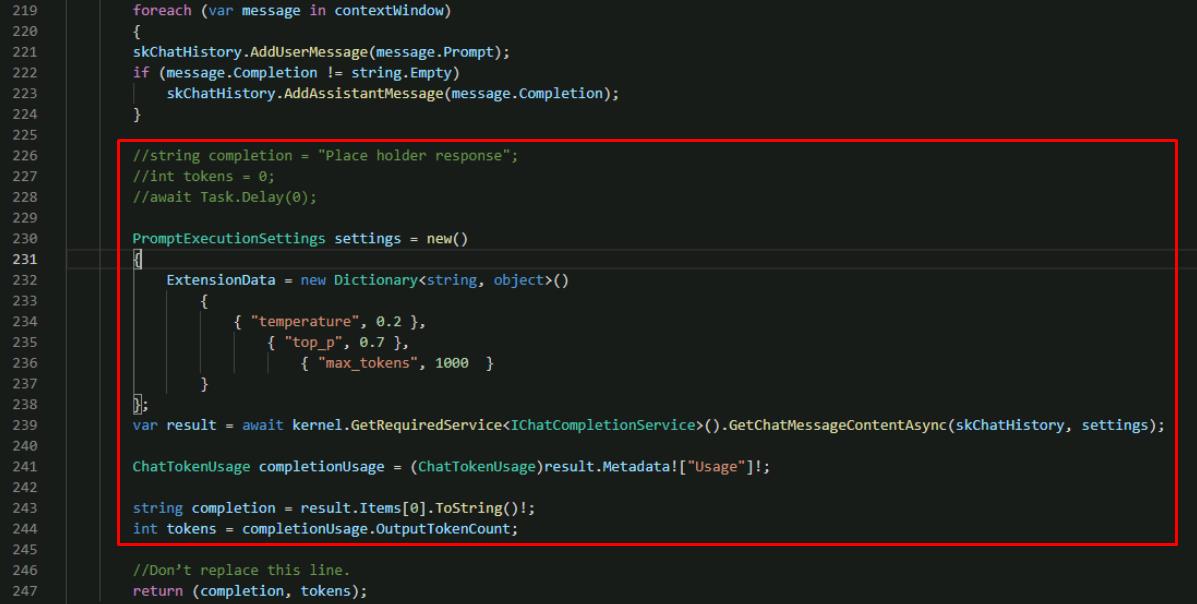
This executes the call to Azure OpenAI using the Semantic Kernel extension configured earlier. You’ll get the completion text and tokens consumed to return to the user.
-
You’ll also use the chat completion extension to generate a summary of the chat to display in the UI. In the same file, find the SummarizeConversationAsync`() method.
-
Comment out the placeholder code and add the following code above the existing return statement, by replacing with the following:
//await Task.Delay(0); //string completion = "Placeholder summary"; var skChatHistory = new ChatHistory(); skChatHistory.AddSystemMessage(_summarizePrompt); skChatHistory.AddUserMessage(conversation); PromptExecutionSettings settings = new() { ExtensionData = new Dictionary<string, object>() { { "temperature", 0.0 }, { "top_p", 1.0 }, { "max_tokens", 100 } } }; var result = await kernel.GetRequiredService<IChatCompletionService>().GetChatMessageContentAsync(skChatHistory, settings); string completion = result.Items[0].ToString()!;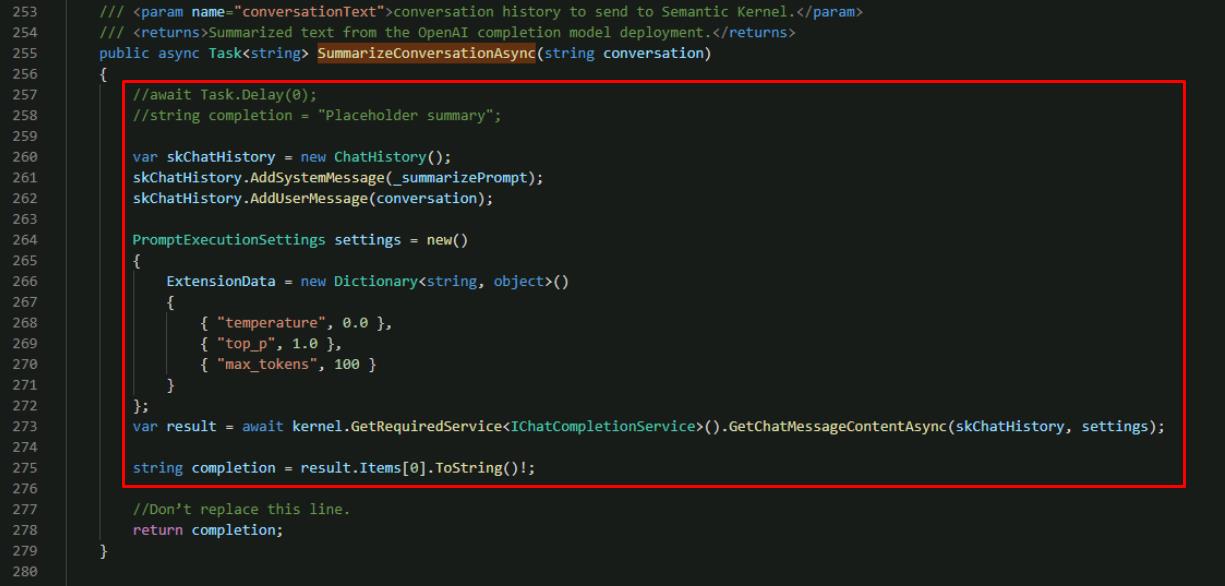
This code has a similar flow for generating a completion using the Semantic Kernel OpenAI chat completion extension, however, notice the system prompt you’re passing in is different. The _summarizePrompt instructs the model to provide a short summary that we’ll use to name the chat.
-
Save the file by selecting File in the upper left of the window, then select Save.
03: Implement the Semantic Kernel service
Expand this section to view the solution
To keep things organized, you’ll create a dedicated service that handles AI logic. CWBC aims for a maintainable system—when future updates roll in (like advanced route-finding), they can simply plug into this well-structured AI layer. You now need to take the completed Semantic Kernel service and use it in the ChatService.cs for the lab.
-
In the left EXPLORER pane of Visual Studio Code, select ChatService.cs under the same Services subfolder.
-
Select Ctrl+F to find the GetChatCompletionAsync`() function.
You need to modify this function to use the new Semantic Kernel implementation.
-
Comment out the two placeholder chatMessage lines, and add lines to create a list of messages from the user prompt and call the Semantic Kernel service, using the following:
//chatMessage.Completion = "Place holder response"; //chatMessage.CompletionTokens = 0; List<Message> messages = new List<Message>() { chatMessage }; (chatMessage.Completion, chatMessage.CompletionTokens) = await _semanticKernelService.GetChatCompletionAsync(messages);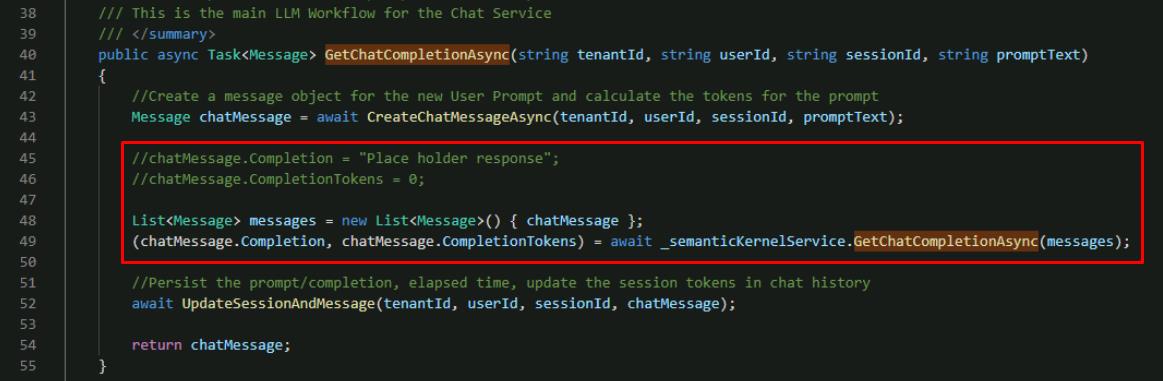
-
Save the ChatService.cs file.
04: Check your work
Expand this section to view the solution
Time for a quick spin around the block. Run the application, ask a simple question (like “**What are the most expensive bikes?** ”), and see if the assistant replies with more than a placeholder. A successful test ensures the AI engine is functioning correctly.
-
In the Visual Studio Code terminal, start the application again.
dotnet run -
Select Ctrl+click on the URL on the Login to the dashboard line again to open the .NET Aspire dashboard.

-
Select the http://localhost:8100 endpoint to launch the chat application.
-
Select Create New Chat on the left.
-
Enter What are the most expensive bikes?
You should see output similar to the following. Don’t worry if it’s not identical.
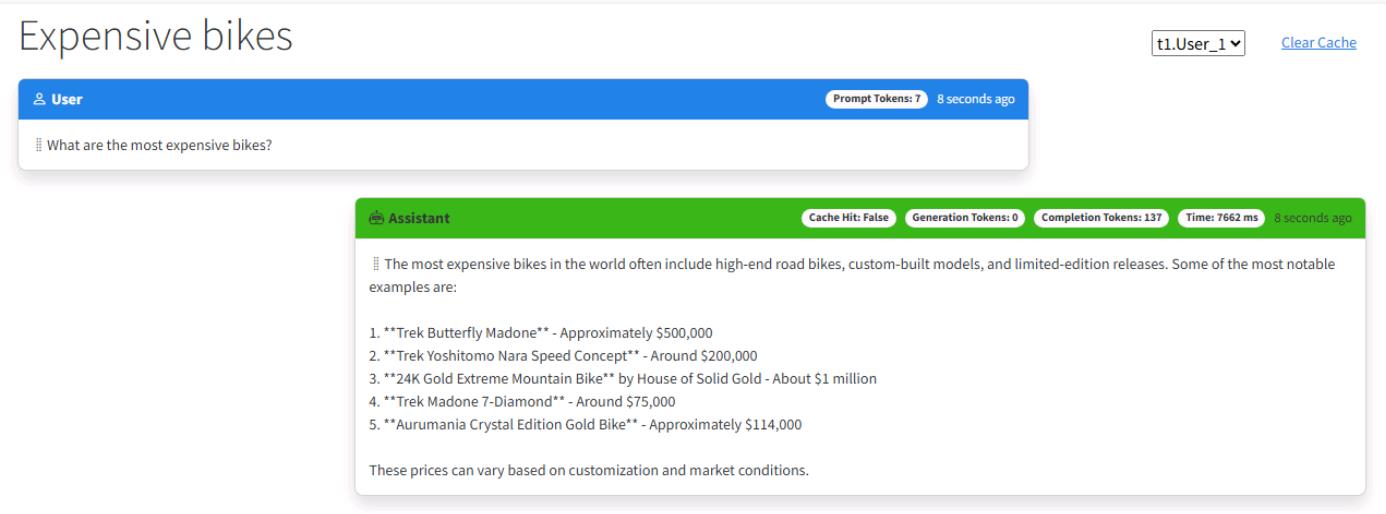
-
Keep the application running, as you’ll use this same session in the next exercise.
Is your application not working or throwing exceptions? Compare your code against this example.
-
Review the GetChatCompletionAsync() function in the SemanticKernelService.cs to make sure that your code matches this sample.
public async Task<(string completion, int tokens)> GetChatCompletionAsync(List<Message> contextWindow) { var skChatHistory = new ChatHistory(); skChatHistory.AddSystemMessage(_systemPrompt); foreach (var message in contextWindow) { skChatHistory.AddUserMessage(message.Prompt); if (message.Completion != string.Empty) skChatHistory.AddAssistantMessage(message.Completion); } PromptExecutionSettings settings = new() { ExtensionData = new Dictionary<string, object>() { { "temperature", 0.2 }, { "top_p", 0.7 }, { "max_tokens", 1000 } } }; var result = await kernel.GetRequiredService<IChatCompletionService>().GetChatMessageContentAsync(skChatHistory, settings); ChatTokenUsage completionUsage = (ChatTokenUsage)result.Metadata!["Usage"]!; string completion = result.Items[0].ToString()!; int tokens = completionUsage.OutputTokenCount; return (completion, tokens); } -
Review the SummarizeConversationAsync() function in the SemanticKernelService.cs to make sure that your code matches this sample.
public async Task<string> SummarizeConversationAsync(string conversation) { var skChatHistory = new ChatHistory(); skChatHistory.AddSystemMessage(_summarizePrompt); skChatHistory.AddUserMessage(conversation); PromptExecutionSettings settings = new() { ExtensionData = new Dictionary<string, object>() { { "temperature", 0.0 }, { "top_p", 1.0 }, { "max_tokens", 100 } } }; var result = await kernel.GetRequiredService<IChatCompletionService>().GetChatMessageContentAsync(skChatHistory, settings); string completion = result.Items[0].ToString()!; return completion; }
Congratulations! You’ve successfully completed this task.