Task 02: Use AI-driven features in Postgres
Introduction
The city has already transitioned to their database system to improve administrative efficiency. Now, they aim to further enhance their data insights and streamline services by incorporating Azure AI functionalities. By integrating AI capabilities directly into PostgreSQL, Metropolis can leverage advanced text processing, semantic search, and other intelligent features. This integration will reduce manual overhead and enable city employees to respond more quickly to citizen needs, ultimately improving the overall efficiency and effectiveness of municipal services.
Description
In this task, you’ll leverage AI-driven capabilities within PostgreSQL to enhance data analysis and searching. From simple pattern matching to advanced semantic searches, these features can significantly reduce manual efforts — that could be vital for municipalities managing large volumes of complex data.
Success criteria
- You used the
ILIKEclause for case-insensitive searches. - You located specific complaints or requests without exact phrasing.
- You generated and stored embedding vectors with
azure_ai. - You performed similarity searches and advanced analytics.
- You implemented and utilized the DiskANN index.
Learning resources
- Pattern matching concepts
- Semantic index for Copilot
- DiskANN: Vector Search for Web Scale Search and Recommendation
Key tasks
01: Use pattern matching for queries
Expand this section to view the solution
Use pattern matching for queries
You’ll explore how to use the ILIKE clause in SQL to perform case-insensitive searches within text fields. This approach can help Metropolis officials locate specific complaints or requests in large datasets without having to rely on exact phrasing.
-
Search for cases mentioning Water leaking into the apartment from the floor above by entering the following query in pgAdmin, then select Execute script.
SELECT id, name, opinion FROM cases WHERE opinion ILIKE '%Water leaking into the apartment from the floor above';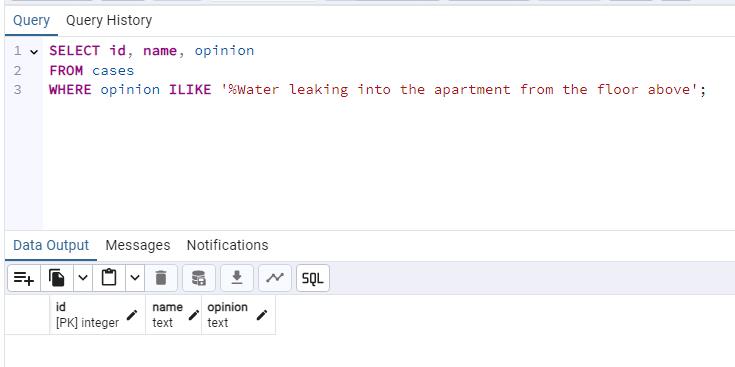
There are no results as the exact words are not mentioned in the opinion. We’ll need to try another approach.
02: Use Semantic Search and DiskANN Index
Expand this section to view the solution
Use Semantic Search and DiskANN Index
In this section, you’ll focus on generating and storing embedding vectors, which are crucial for performing semantic searches in the dataset. Embedding vectors represent data points in a high-dimensional space, allowing for efficient similarity searches and advanced analytics.
Create, store and index embedding vectors
Now that you have some sample data, it’s time to generate and store the embedding vectors. The azure_ai extension makes calling the Azure OpenAI embedding API easy. This lays the groundwork for advanced analytics on city records or citizen feedback.
-
Install the vector extension using the CREATE EXTENSION command by executing the following:
CREATE EXTENSION IF NOT EXISTS vector; -
Add the embedding vector column by executing the following. The text-embedding-3-small model is configured to return 1,536 dimensions, so you’ll use that for the vector column size.
ALTER TABLE cases ADD COLUMN opinions_vector vector(1536); -
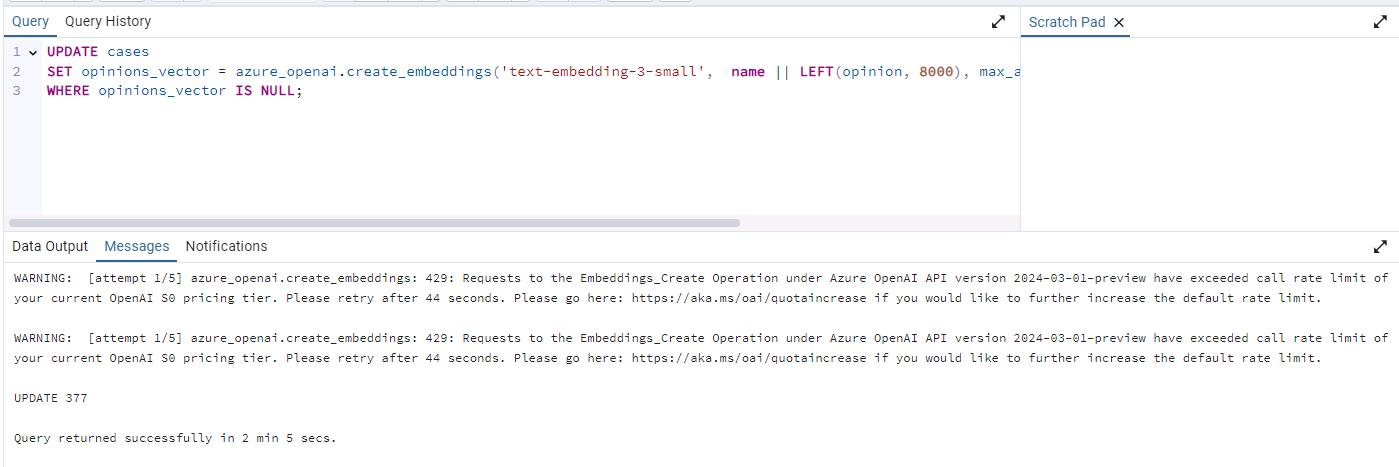
Generate an embedding vector for the opinion of each case by calling Azure OpenAI through the create_embeddings user-defined function, which is implemented by the azure_ai extension:
UPDATE cases SET opinions_vector = azure_openai.create_embeddings('text-embedding-3-small', name || LEFT(opinion, 8000), max_attempts => 5, retry_delay_ms => 500)::vector WHERE opinions_vector IS NULL;This may take several minutes, depending on the available quota. You may receive several 429 rate limit warnings that can be ignored as it retries automatically.
The output will be similar to the following:
Adding a DiskANN Vector Index to improve vector search speed.
Using DiskANN Vector Index in Azure Database for PostgreSQL - DiskANN is a scalable approximate nearest neighbor search algorithm for efficient vector search at any scale. It offers high recall, high queries per second (QPS), and low query latency, even for billion-point datasets. This makes it a powerful tool for handling large volumes of data. Learn more about DiskANN from Microsoft.
-
Install the pg_diskann extension using the CREATE EXTENSION command by executing the following:
CREATE EXTENSION IF NOT EXISTS pg_diskann; -
Create the diskann index on a table column that contains vector data.
CREATE INDEX cases_cosine_diskann ON cases USING diskann(opinions_vector vector_cosine_ops);As you scale your data to millions of rows, DiskANN makes vector search more efficient.
-
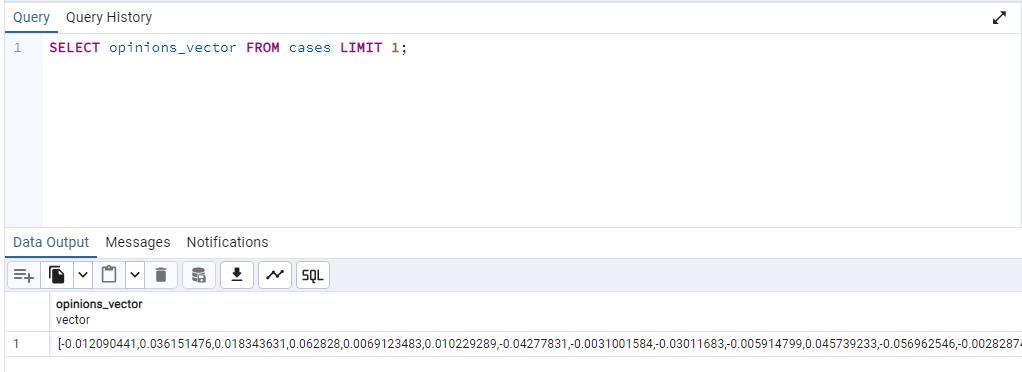
See an example vector by executing the following, which is limited to one result:
SELECT opinions_vector FROM cases LIMIT 1;The output will be similar to the following:
Perform a semantic search query
Now that you have listing data augmented with embedding vectors, it’s time to run a semantic search query. To do so, get the query string embedding vector, then perform a cosine search to find the cases whose opinions are most semantically similar to the query.
-
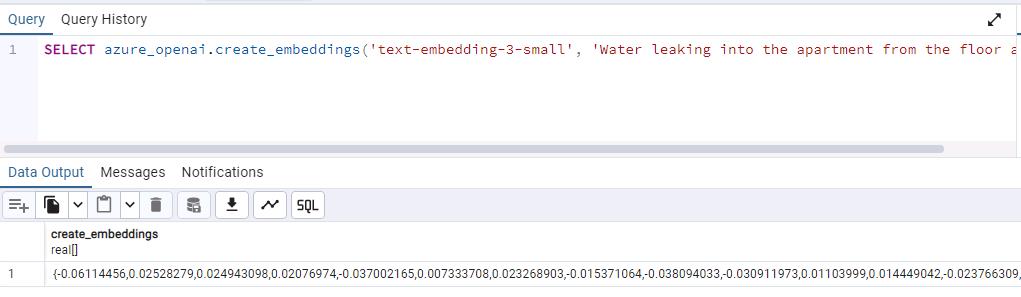
Generate the embedding for the query string.
SELECT azure_openai.create_embeddings('text-embedding-3-small', 'Water leaking into the apartment from the floor above.');The output will be similar to the following:
-
Use the embedding in a cosine search (<=> represents cosine distance operation), fetching the top 10 most similar cases to the query.
SELECT id, name FROM cases ORDER BY opinions_vector <=> azure_openai.create_embeddings('text-embedding-3-small', 'Water leaking into the apartment from the floor above.')::vector LIMIT 10;The output will be similar to the following. Results will vary:
-
You may also project the opinion column to be able to read the text of the matching rows whose opinions were semantically similar. For example, this query returns the best match:
SELECT id, opinion FROM cases ORDER BY opinions_vector <=> azure_openai.create_embeddings('text-embedding-3-small', 'Water leaking into the apartment from the floor above.')::vector LIMIT 1;The output will be similar to the following:

To intuitively understand semantic search, observe that the opinion mentioned doesn’t actually contain the terms “Water leaking into the apartment from the floor above.”
However, it does highlight a document with a section that says “nonsuit and dismissal, in an action brought by a tenant to recover damages for injuries to her goods, caused by leakage of water from an upper story,” which is similar.
Congratulations! You’ve successfully completed this task.