Task 06: Explore the .NET Aspire dashboard
Introduction
Real-time insights matter to CWBC. Suppose a new e-bike line launches and queries spike; the .NET Aspire Dashboard helps you spot performance bottlenecks, see which calls consume the most tokens, and confirm whether your cache is kicking in. It’s the command center for everything your Intelligent Assistant does.
The .NET Aspire dashboard is a great resource for monitoring your application in development. It helps you understand the request flow in your application and provides a centralized place for viewing traces and logs in real-time.
So far, you’ve used the .NET Aspire dashboard to launch the web application. Let’s explore the other features exposed in the dashboard.
Description
In this task, you’ll investigate how the Intelligent Assistant performs under the hood by using the .NET Aspire dashboard. You’ll observe real-time traces, monitor how requests flow to Azure Cosmos DB and Azure OpenAI, and identify when cache hits or vector searches occur.
Success criteria
- You have real-time traces for each request (vector search, semantic cache, AI completion) in the dashboard.
- You identified where requests spend the most time, confirmed cache hits versus misses, and observed any slow spans.
- You know how to use the metrics and logs to troubleshoot or optimize the Intelligent Assistant’s performance over time.
Learning resources
Key tasks
01: Analyze real-time traces
Expand this section to view the solution
-
Select Create New Chat on the left, then select the New Chat that was created.
-
Enter What bike accessories do you have?
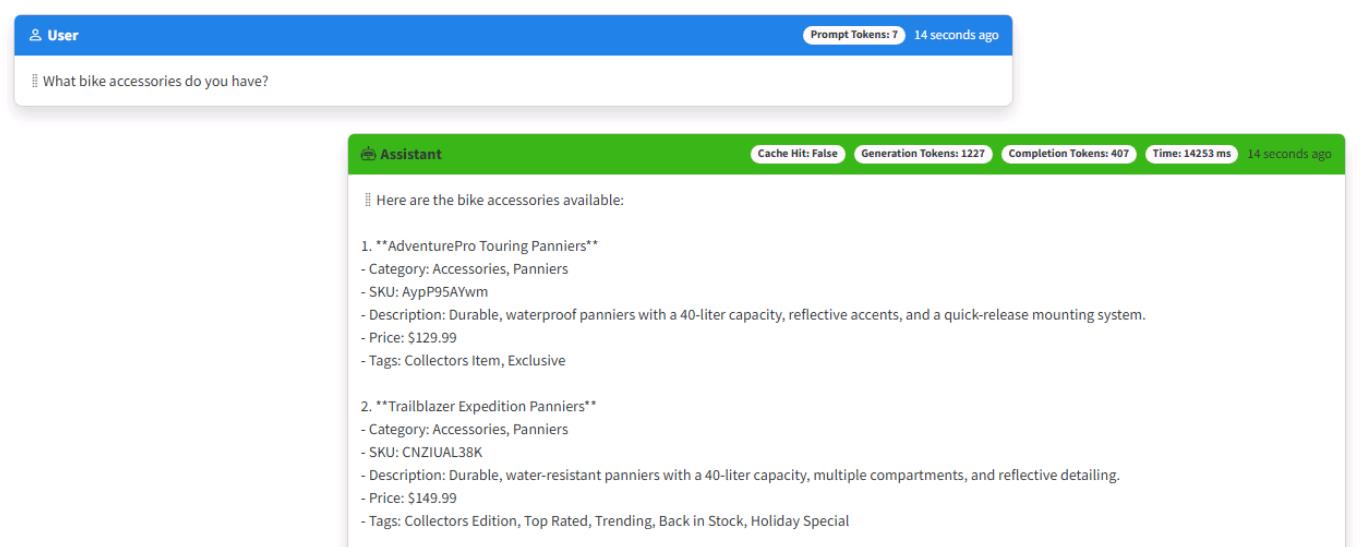
-
Start another new chat session, and ask the same question: What bike accessories do you have?
You should get a cache hit with an immediate response consuming zero generation tokens.
-
Go to the .NET Aspire dashboard tab in the browser.
-
Select Traces from the left toolbar.
You’ll see all the network requests in your application represented chronologically here. Notice there are several GET calls and a POST as the Blazor application starts up.
-
Select the bottom trace to expand the service calls being made in the application.
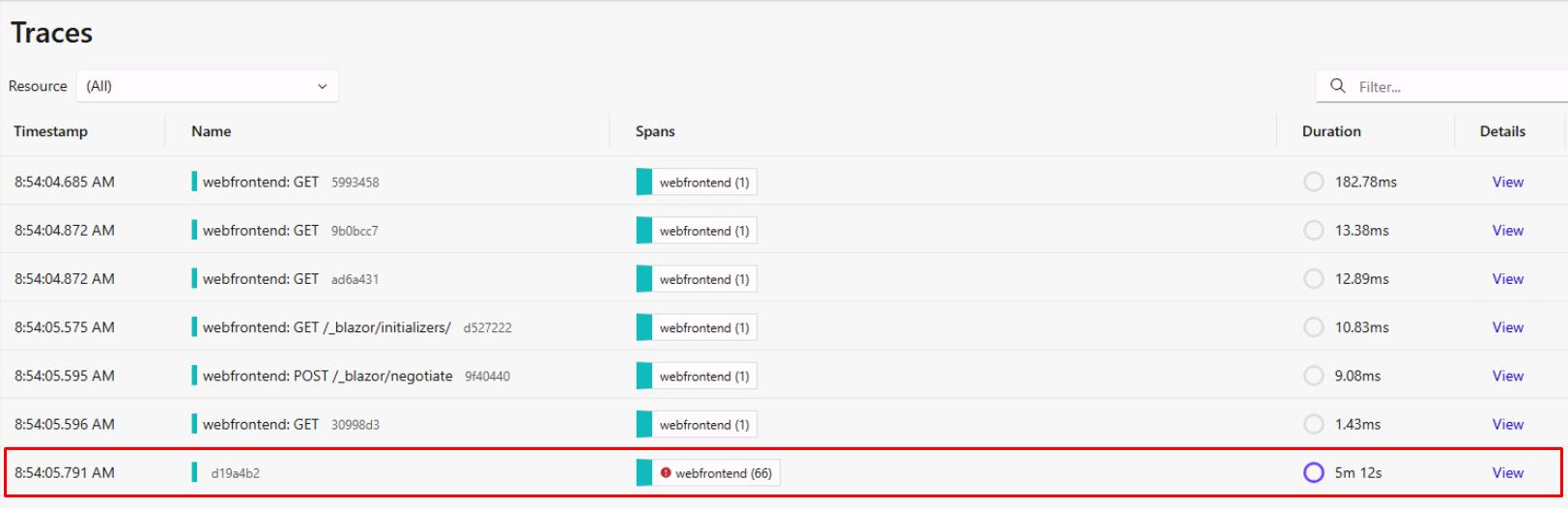
Each request made to Azure Cosmos DB or Azure OpenAI is represented as a span. The first few spans represent background tasks in the web application to query Azure Cosmos DB for existing chats and to verify the product data has been loaded.
Each time a new container in Azure Cosmos DB is accessed, the SDK makes several HTTP requests to get metadata for the container. You’ll see these represented as child spans. Let’s explore the spans in this dashboard and correlate them to the features you implemented so far in the chat application.
-
Scroll down in the list of traces. If you created a new chat session for this exercise, find the second DATA cosmosdb CreateItemAsync chat span (the first would be to create the chat session item itself). If you didn’t create a new chat session, find the first CreateItemAsync. This is the call to store your first prompt in the Azure Cosmos DB chat container.
You may need to expand the Name column by selecting the vertical line to the left of the 0s column and dragging it to the right.
-
Since you haven’t asked about bike accessories yet, this was a cache miss. Let’s explore the request flow and validate it matches expectations.
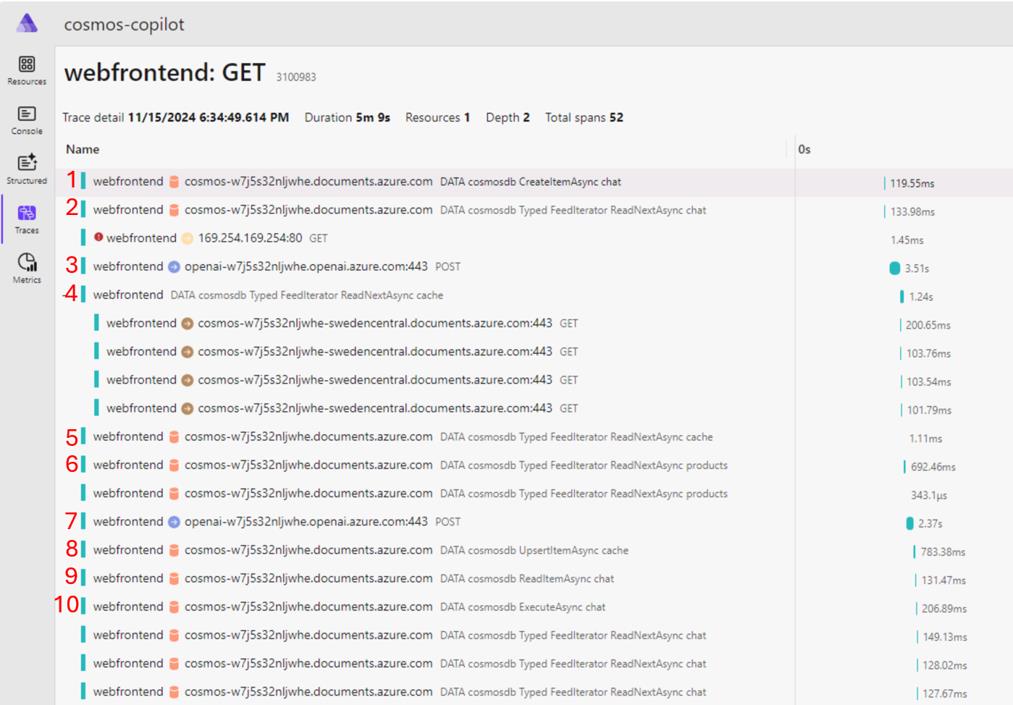
Your traces should resemble the image above. If you see an error from 169.254.169.254:80, this is a metadata request made by the SDK to get information about your compute environment. For unsupported VM types, this is expected to fail and is safe to ignore.
- First, there is a call to the Azure Cosmos DB chat container to store the prompt you typed in the chat.
- Next, the call to the chat container represents building the context window. You need to query for any previous messages in the chat session to get contextually relevant results.
- Then, this call to Azure OpenAI represents getting the vector embeddings from the prompt.
- This call to the cache container checks if a cache hit was found by passing in the vector embeddings and performing a vector search for similar responses. Notice there are child HTTP calls under this request. That is the SDK initializing connections for the cache container. The other containers had already been used earlier on in the application and therefore had already been initialized.
- This call represents a second round trip for the get cache query.
- Because there was a cache miss, the next query was for products relevant to the user prompt. This call uses vector search to find products from the products container to later pass to Azure OpenAI. The product data returned is the key component for implementing the RAG pattern.
- Next, there’s the call to Azure OpenAI to get the chat completion for the prompt and RAG data. Notice the calls to Azure OpenAI have a higher duration than the rest of the calls, this is because it’s sending a lot of context to the model to generate a completion.
- After generating a completion, the results are stored in the cache to avoid having to compute a response for similar questions in the future.
- Then you call to retrieve the chat container item representing this chat session.
- Last, you execute a bulk upload of the chat completion and session to the chat container.
This request flow maps to the LLM Pipeline we created in the ChatService/GetChatCompletionAsync() function.
-
Below the cache miss request flow, let’s analyze the spans for the second prompt. This time, you started another new chat session and entered the same question, generating a cache hit. You’ll notice the first three spans are the same, but because you had a cache hit, there are fewer steps.
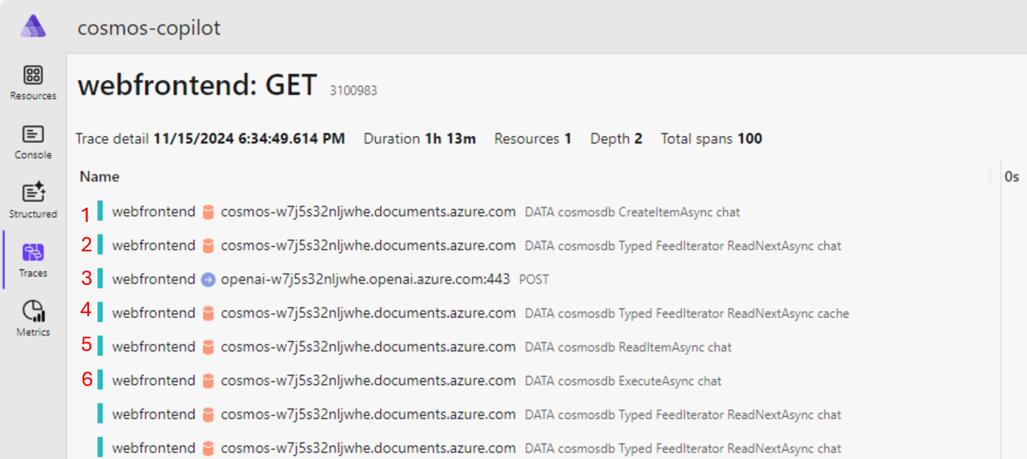
- First, there’s a call to the Azure Cosmos DB chat container to store the prompt you typed in the chat.
- Next, the call to the chat container represents building the context window. You need to query for any previous messages in the chat session to get contextually relevant results.
- Then, this call to Azure OpenAI represents getting the vector embeddings from the prompt.
- This call to the cache container checks if a cache hit was found by passing in the vector embeddings and performing a vector search for similar responses. Because you’ve already made requests to the cache container in the previous chat, there are no child span initialization calls either.
- Then you call to retrieve the chat container item representing this chat session.
- Last, you execute a bulk upload of the chat completion and session to the chat container.
This request flow also maps to the LLM Pipeline we created in the ChatService/GetChatCompletionAsync() function. Because there was a cache hit, the code executed in the if statement that skips the calls to find relevant products and generate a completion from Azure OpenAI. Instead, it can return the cached completion to the user.
-
These traces and spans are emitted using OpenTelemetry, which is configured by default when you use .NET Aspire. Every SDK can provide custom OpenTelemetry attributes to add extra information to spans about the request. Azure Cosmos DB emits several custom attributes that can help you understand what’s happening in your application. Select the fourth span from the previous step, which represents the query to the cache container. Optionally, select the icon to switch from horizontal to vertical view.
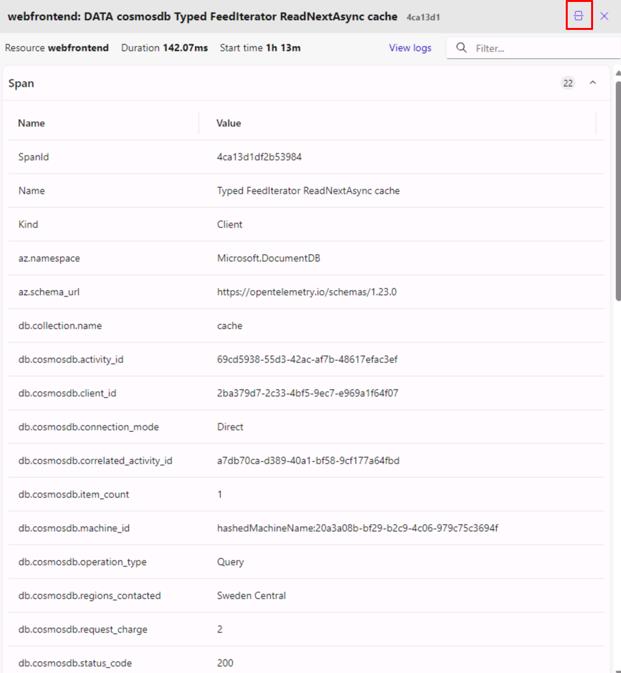
Notice the db.cosmosdb.item_count with a value of 1. This shows that we had one result returned from the query. Explore the other attributes provided and select spans for different operations to see the attributes provided for every request type.
-
Keep the .NET Aspire dashboard open and leave the application running, as you’ll use it again in the next set of steps.
The Azure Cosmos DB SDK also emits logs through OpenTelemetry which appear in the .NET Aspire dashboard. Depending on the log level configured for your application, you can receive logs for errors and warnings. These logs are very helpful during application development to gain more information about failed or slow requests.
First, let’s look at the log configuration for Azure Cosmos DB.
-
Open the src/cosmos-copilot.WebApp/`Program.cs file.
-
Find the builder.AddAzureCosmosClient`() function call, copied again here.
builder.AddAzureCosmosClient( "cosmos-copilot", settings => { settings.AccountEndpoint = new Uri(cosmosEndpoint); settings.Credential = new DefaultAzureCredential(); settings.DisableTracing = false; }, clientOptions => { clientOptions.ApplicationName = "cosmos-copilot"; clientOptions.UseSystemTextJsonSerializerWithOptions = new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }; clientOptions.CosmosClientTelemetryOptions = new() { CosmosThresholdOptions = new() { PointOperationLatencyThreshold = TimeSpan.FromMilliseconds(10), NonPointOperationLatencyThreshold = TimeSpan.FromMilliseconds(20) } }; });Notice the clientOptions.CosmosClientTelemetryOptions call. This is where threshold options are configured for emitting logs from Azure Cosmos DB requests.
[!knowledge] There are separate configurations for PointOperationLatencyThreshold and NonPointOperationLatencyThreshold because requests interacting with a single item are frequently much lower latency than multi-item operations. These two thresholds are set extremely low in this application to ensure you have some logs to look at.
In a production application, you’ll likely want to set this to a higher value to avoid having noisy logs for every request.
-
In the .NET Aspire dashboard, select Structured on the left side menu.
-
Select any of the warnings with a ThresholdViolation.
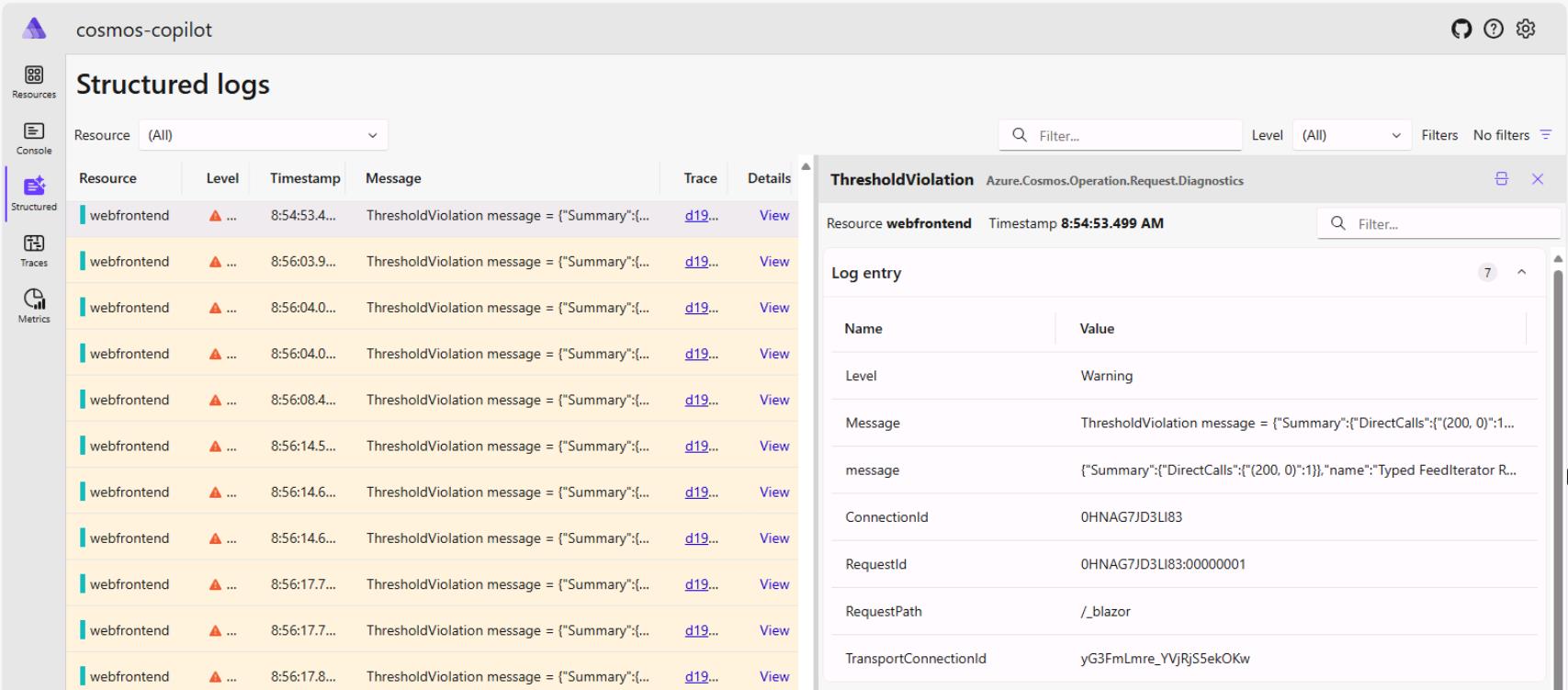
These represent requests that had higher latency than the thresholds you configured while creating the Cosmos client. The Message contains the Azure Cosmos DB diagnostic string with detailed information about the request.
Summary
You’ve successfully implemented the new generative AI application using Azure Cosmos DB and Azure OpenAI Service. You’ve learned new concepts for building generative AI applications such as tokens, context windows, semantic caching, similarity scores, and RAG Pattern.
With the SDKs for Azure Cosmos DB for NoSQL and Semantic Kernel including its extensions and connectors, you were able to add these services to your application with little friction. The services you implemented illustrate the best practices for using each SDK across various operations. The .NET SDKs for each service made it possible to add the required functionality to your ASP.NET Core Blazor web application using .NET Aspire with lightweight method implementations.
References
This hands on lab is available as a completed sample here, Build a custom Copilot application.
Take some time to explore the services and capabilities you saw today to get more familiar with them.
- Semantic Kernel
- Azure Cosmos DB Vector Search
Take your knowledge even further. We’ve built a complete end-to-end RAG Pattern solution that takes this lab you did today and expands it to a fully functional, production grade solution accelerator. The solution has the same ASP.NET Blazor web interface and the back end is entirely built using the latest features from Semantic Kernel. The solution can be deployed to either AKS or Azure Container Apps, along with a host of other services designed for deploying production grade applications in Azure.
- Official Microsoft Solution Accelerator for building RAG pattern applications
Conclusion
Congratulations! You’ve successfully completed this task and have completed the Build a serverless, AI RAG application using data from Azure Cosmos DB lab!