
TIP
💡 Learn more : Azure Databricks (opens new window)
This post was brought to you by Kumar Allamraju (opens new window).
# Getting Started with Azure Databricks
# What is Azure Databricks?
Azure Databricks provides a fast, easy, and collaborative Apache Spark™-based analytics platform to accelerate and simplify the process of building big data and AI solutions backed by industry leading SLAs (opens new window).
With Azure Databricks, customers can set up an optimized Apache Spark environment in minutes. Data scientists and Data engineers can collaborate using an interactive workspace with languages and tools of their choice. Native integration with Azure Active Directory (Azure AD) and other Azure services enables customers to build end-to-end modern data warehouse, machine learning and real-time analytics solutions.
# Why Databricks on Azure?
Azure Databricks is a first party service on Microsoft Azure that helps you to reap the benefits of a fully managed service and reduces the infrastructure complexity that allows you to focus more on innovation, while keeping data safe and secure. This platform provides the latest versions of Apache Spark and allows you to seamlessly integrate with open source libraries. Customers can spin up the Spark clusters in minutes in a fully managed Apache Spark environment with the global scale and availability of Azure. Clusters are set up, configured, and fine-tuned to ensure reliability and performance.
# Setting up Azure Databricks on Azure
(1) Go to azure portal, Click on + Creat a resource and select Analytics >> Azure Databricks
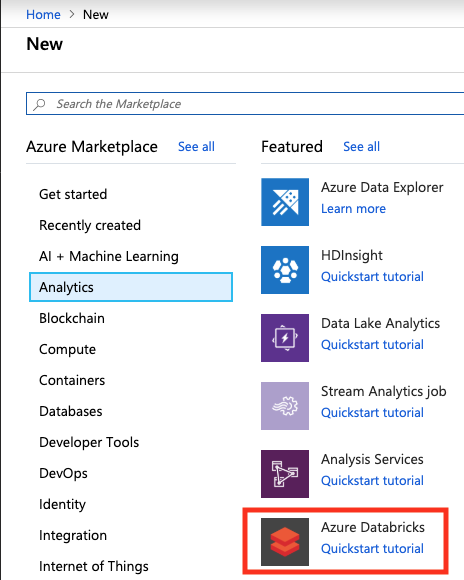
(2) Create a new Databricks workspace
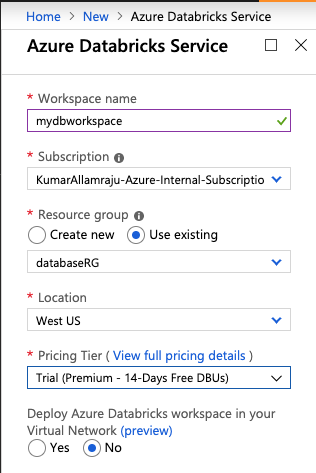
(3) Once the workspace is provisioned, Click on "Launch Workspace". It will open up a new window and you will be signed in to databricks using your Azure AD account.
(4) Click on Explore the Quickstart Tutorial. It will open a "Quickstart Notebook".

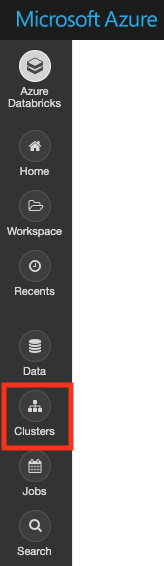
(5) We first need to create a databricks cluster and attach the same to your Quickstart Notebook. On the left pane, click on Clusters >> + Create Cluster
(6) Name your Cluster and pick the defaults as shown below
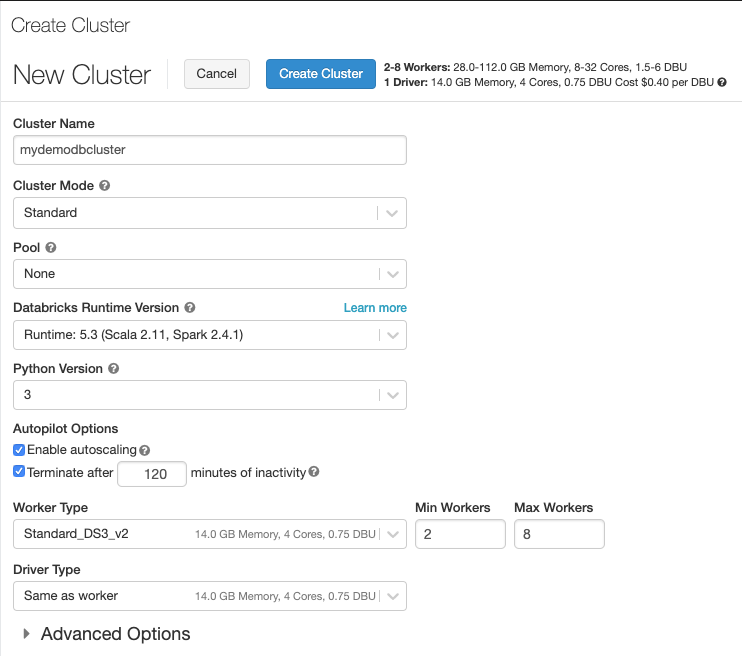
(7) Attach your cluster to the Notebook
Now you can play with the Notebook by executing the code in each cell.
(8) You can SSH to the spark master node from the Advanced Options >> SSH tab and submit the spark jobs from CLI

This is just a quick start to give you a feel of Azure Databricks. You can create new notebooks, import existing notebooks or you can upload the datasets and write your own spark code in suported programming languages like Scale, Python, R etc..
# Conclusion
Azure Databricks builds on the capabilities of Spark by providing a zero-management cloud platform that provides fully managed Spark Clusters, an interactive workspace for exploration and visualization. It provides advanced features like auto-scaling of your spark clusters, VNet integration, scheduled termination (to save on compute costs) monitoring. As we have seen in the demo it's easy to spin up Spark clusters in minutes to perform big data, structured streaming, Machine Learning and AI solutions.