Modern Analytics Academy - Data Engineering
Data Engineering explores topics related to the infrastructure and systems that process data. In our original series, we referred to this as “Data Pipelines.” These topics focus on data movement in Synapse Pipelines, Azure Data Factory, and Fabric Data Engineering (which encompasses Fabric Data Factory, data pipelines, and Spark/notebooks). Data Engineering often overlaps with storage and modeling, particularly with Lakehouse implementations, so we’ll include topics related to data modeling. We’ll also include material related to observability and monitoring.
- Microsoft Learn: Data engineering in Fabric
- Azure Data Factory
- Microsoft Architecture Center: Extract, transform, and load (ETL)
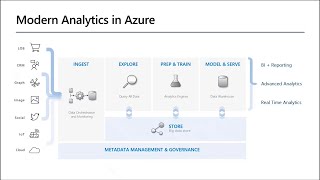 In Data Modeling we'll look at how to structure a Data Lake, and how to leverage technologies like Synapse Spark, Synapse SQL, and Synapse Serverless SQL in conjunction with technologies like Delta to provde a mechanism for users and downstream visualization tools to query and explore data.
more »
In Data Modeling we'll look at how to structure a Data Lake, and how to leverage technologies like Synapse Spark, Synapse SQL, and Synapse Serverless SQL in conjunction with technologies like Delta to provde a mechanism for users and downstream visualization tools to query and explore data.
more »
 In Data Pipelines, we'll look at the definition and key concepts of creating a data pipeline. We will dive into four Microsoft cloud resources, including Azure Data Factory, Azure Synapse Data Pipelines, Power BI Data Flow, and Azure Streaming Analytics. Lastly, we will review the comparison metrics to help you decide which service to choose for your scenario.
more »
In Data Pipelines, we'll look at the definition and key concepts of creating a data pipeline. We will dive into four Microsoft cloud resources, including Azure Data Factory, Azure Synapse Data Pipelines, Power BI Data Flow, and Azure Streaming Analytics. Lastly, we will review the comparison metrics to help you decide which service to choose for your scenario.
more »
“Vignette” Sessions
Our ongoing Modern Analytics Academy series, which we’ve called “vignettes”, dive into topical areas related to analytics. For a complete list of sessions, visit the vignette page. The following vignettes are related to acquisition and storage:
 In this video, we'll dive into how to use Data Wrangler in Microsoft Fabric to cleanse and group by/aggregate data as part our ETL pipeline. We'll walk through some common steps used in data transformation, and include a few examples on deriving new columns from existing ones, such as extracting the hour from a timestamp. workspace.
more »
In this video, we'll dive into how to use Data Wrangler in Microsoft Fabric to cleanse and group by/aggregate data as part our ETL pipeline. We'll walk through some common steps used in data transformation, and include a few examples on deriving new columns from existing ones, such as extracting the hour from a timestamp. workspace.
more »
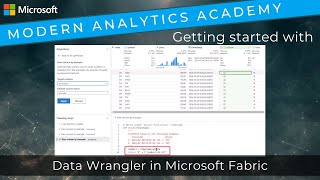 In this video, we'll dive into how to use Data Wrangler in Microsoft Fabric to cleanse and group by/aggregate data as part our ETL pipeline. We'll walk through some common steps used in data transformation, and include a few examples on deriving new columns from existing ones, such as extracting the hour from a timestamp. workspace.
more »
In this video, we'll dive into how to use Data Wrangler in Microsoft Fabric to cleanse and group by/aggregate data as part our ETL pipeline. We'll walk through some common steps used in data transformation, and include a few examples on deriving new columns from existing ones, such as extracting the hour from a timestamp. workspace.
more »
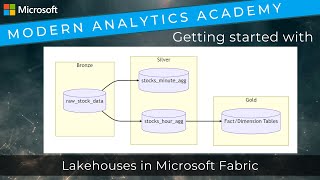
 In this vignette video, solution architect Armando Marrero looks at building out a data warehouse in Microsoft Fabric based off our real-time analytics lab (https://aka.ms/lakehouselab) by building a pipeline to do data ingestion from the KQL database, and aggregate the data into a simple dimensional model.
more »
In this vignette video, solution architect Armando Marrero looks at building out a data warehouse in Microsoft Fabric based off our real-time analytics lab (https://aka.ms/lakehouselab) by building a pipeline to do data ingestion from the KQL database, and aggregate the data into a simple dimensional model.
more »
 Data Activator is an observability tool in Microsoft Fabric for automatically monitoring and taking actions when certain conditions (or patterns) emerge in the underlying data stream. This is often used for sensors, sales data, KPIs, system health/performance counters. We'll take a look at configuring Data Activator from a Power BI visual and getting started using our recently published lab.
more »
Data Activator is an observability tool in Microsoft Fabric for automatically monitoring and taking actions when certain conditions (or patterns) emerge in the underlying data stream. This is often used for sensors, sales data, KPIs, system health/performance counters. We'll take a look at configuring Data Activator from a Power BI visual and getting started using our recently published lab.
more »
 Real-time Analytics in Microsoft Fabric is a fully managed analytics platform optimized for streaming and time-series data. In this video, Cameron walks though getting started with setting up an environment, generating and ingesting test data, and visualize the data using KQL in Power BI. See this hack and others at https://aka.ms/wth
more »
Real-time Analytics in Microsoft Fabric is a fully managed analytics platform optimized for streaming and time-series data. In this video, Cameron walks though getting started with setting up an environment, generating and ingesting test data, and visualize the data using KQL in Power BI. See this hack and others at https://aka.ms/wth
more »
 This deployment accelerator demonstrates how to use Azure Synapse Analytics with the extensive family of Azure Data Services to build a modern data platform that's capable of handling the most common data challenges in an organization.
more »
This deployment accelerator demonstrates how to use Azure Synapse Analytics with the extensive family of Azure Data Services to build a modern data platform that's capable of handling the most common data challenges in an organization.
more »
 Polybase and Copy are very performant ways to load data from Azure Storage into Azure Synapse. In this session, we will discuss how they differ from one another and when to use one over the other.
more »
Polybase and Copy are very performant ways to load data from Azure Storage into Azure Synapse. In this session, we will discuss how they differ from one another and when to use one over the other.
more »
 Mike Shelton explores the basics of schema design in a SQL Pool (SQL DW). What is a star schema and why do we use it?
more »
Mike Shelton explores the basics of schema design in a SQL Pool (SQL DW). What is a star schema and why do we use it?
more »