Task 01: Read from Bronze layer, convert the data into delta format and write to the Silver layer
With this move we aim to clean and refine data within the Bronze layer, improving data quality and preparing it for further processing, aligning with Contoso’s focus on reliable data foundations.
Data will be written as external tables.
-
On your local machine, open File Explorer and go to the Downloads folder.
-
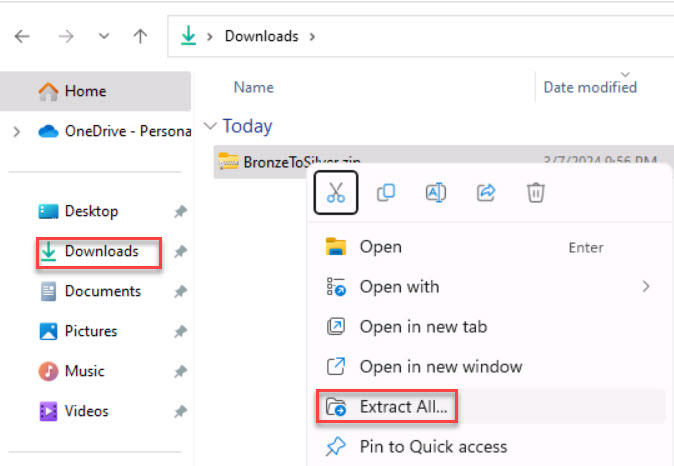
Right-click the BronzeToSilver.zip compressed folder and select Extract All….
-
Select Extract and then close the File Explorer window.
-
Return to the Databricks Workspace browser tab.
-
In the left navigation pane, select Workspace. This action causes the page to refresh.
-
In the Workspace pane, select Workspace and then select Users. Select @lab.CloudPortalCredential(User1).Username.
-
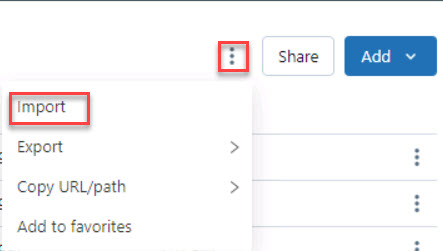
In the upper-right pane, select the vertical ellipses and then select Import.
-
In the Import window, next to Import from select File and then select browse.
-
In File Explorer, go to Downloads and then double-click the BronzeToSilver folder.
-
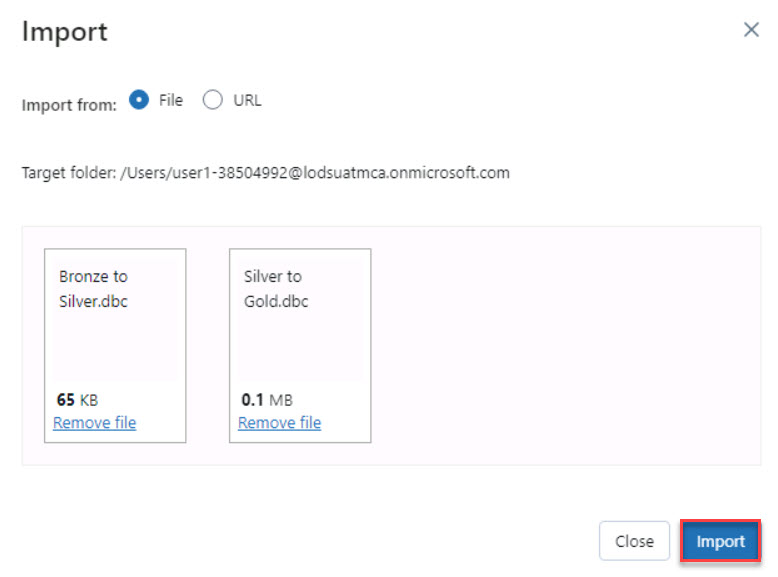
Select the Bronze to Silver.dbc and Silver to Gold.dbc files, then select Open.
-
Select Import.
-
After the notebooks are imported, select the Bronze to Silver notebook.
We’re now getting ready to transform and store processed data in the Silver layer in delta format, enhancing Contoso’s data storage efficiency and accessibility for analytical processes.
-
In the first code cell, replace the ENTERHERE placeholders with the following information:
Name Value Comment scope scopesecret key appServiceRegistrationSecret You can also retrieve the secret from the Keys page for the key vault storage_account [Your Storage Account Name] You can also retrieve the Storage Account name from the Storage Account resource page application_id [Your Application ID] You can also retrieve this ID from the Microsoft Entra > App registration Overview page directory_id [Your Directory (Tenant) ID] You can also retrieve this ID from the Microsoft Entra > App registration Overview page If a value in the Values column is missing, use the information from the Comment column to retrieve the values that you need.
-
In the second code cell, populate the <ENTERHERE> placeholders with the following information:
Line Name Value 1 container_name “medallion” 8 df spark.read.format(“csv”).options(inferSchema=”true”, header=”true”).load(path=f”{file_path.path}*”) 11 df.createOrReplaceTempView df.createOrReplaceTempView(file_path.name.removesuffix(‘.csv’).replace(‘.’, ‘’)) -
In the third code cell, replace the <ENTERHERE> placeholder with the following command. This command displays available views.
SHOW VIEWS -
In the fourth code cell, replace the <ENTERHERE> placeholder with the following command. This command displays the first 100 rows from salesltaddress.
SELECT * FROM salesltaddress LIMIT 100 -
In the fifth code cell, replace the <ENTERHERE> placeholder with the following command.
spark.sql("SHOW VIEWS") -
Select Run all.

-
Review the output for each cell.