This page was generated from
docs/examples/DataSet/Working-With-Pandas-and-XArray.ipynb.
Interactive online version:
![]() .
.
Working with Pandas and XArray¶
This notebook demonstrates how Pandas and XArray can be used to work with the QCoDeS DataSet. It is not meant as a general introduction to Pandas and XArray. We refer to the official documentation for Pandas and XArray for this. This notebook requires that both Pandas and XArray are installed.
Setup¶
First we borrow an example from the measurement notebook to have some data to work with. We split the measurement in two so we can try merging it with Pandas.
[1]:
%matplotlib inline
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import qcodes as qc
from qcodes.dataset import (
Measurement,
initialise_or_create_database_at,
load_or_create_experiment,
)
from qcodes.instrument_drivers.mock_instruments import (
DummyInstrument,
DummyInstrumentWithMeasurement,
)
[2]:
# preparatory mocking of physical setup
dac = DummyInstrument("dac", gates=["ch1", "ch2"])
dmm = DummyInstrumentWithMeasurement("dmm", setter_instr=dac)
station = qc.Station(dmm, dac)
/tmp/ipykernel_20774/2648453101.py:4: QCoDeSDeprecationWarning: Importing 'Station' from the top level 'qcodes' namespace is deprecated. Import it from 'qcodes.station' instead.
station = qc.Station(dmm, dac)
[3]:
initialise_or_create_database_at(
Path.cwd().parent / "example_output" / "working_with_pandas.db"
)
exp = load_or_create_experiment(
experiment_name="working_with_pandas", sample_name="no sample"
)
[4]:
meas = Measurement(exp)
meas.register_parameter(dac.ch1) # register the first independent parameter
meas.register_parameter(dac.ch2) # register the second independent parameter
meas.register_parameter(
dmm.v2, setpoints=(dac.ch1, dac.ch2)
) # register the dependent one
[4]:
<qcodes.dataset.measurements.Measurement at 0x7ffa6b58fe00>
We then perform a very basic experiment. To be able to demonstrate merging of datasets in Pandas we will perform the measurement in two parts.
[5]:
# run a 2D sweep
with meas.run() as datasaver:
for v1 in np.linspace(-1, 0, 50, endpoint=False):
for v2 in np.linspace(-1, 1, 51):
dac.ch1(v1)
dac.ch2(v2)
val = dmm.v2.get()
datasaver.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v2, val))
dataset1 = datasaver.dataset
Starting experimental run with id: 1.
[6]:
# run a 2D sweep
with meas.run() as datasaver:
for v1 in np.linspace(0, 1, 51):
for v2 in np.linspace(-1, 1, 51):
dac.ch1(v1)
dac.ch2(v2)
val = dmm.v2.get()
datasaver.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v2, val))
dataset2 = datasaver.dataset
Starting experimental run with id: 2.
Two methods exists for extracting data to pandas dataframes. to_pandas_dataframe exports all the data from the dataset into a single dataframe. to_pandas_dataframe_dict returns the data as a dict from measured (dependent) parameters to DataFrames.
Please note that the to_pandas_dataframe is only intended to be used when all dependent parameters have the same setpoint. If this is not the case for the DataSet then to_pandas_dataframe_dict should be used.
[7]:
df1 = dataset1.to_pandas_dataframe()
df2 = dataset2.to_pandas_dataframe()
Working with Pandas¶
Lets first inspect the Pandas DataFrame. Note how both dependent variables are used for the index. Pandas refers to this as a MultiIndex. For visual clarity, we just look at the first N points of the dataset.
[8]:
N = 10
[9]:
df1[:N]
[9]:
| dmm_v2 | ||
|---|---|---|
| dac_ch1 | dac_ch2 | |
| -1.0 | -1.00 | 0.000132 |
| -0.96 | 0.000894 | |
| -0.92 | 0.000803 | |
| -0.88 | -0.000171 | |
| -0.84 | 0.000585 | |
| -0.80 | -0.000033 | |
| -0.76 | 0.000067 | |
| -0.72 | 0.000194 | |
| -0.68 | -0.000390 | |
| -0.64 | 0.000402 |
We can also reset the index to return a simpler view where all data points are simply indexed by a running counter. As we shall see below this can be needed in some situations. Note that calling reset_index leaves the original dataframe untouched.
[10]:
df1.reset_index()[0:N]
[10]:
| dac_ch1 | dac_ch2 | dmm_v2 | |
|---|---|---|---|
| 0 | -1.0 | -1.00 | 0.000132 |
| 1 | -1.0 | -0.96 | 0.000894 |
| 2 | -1.0 | -0.92 | 0.000803 |
| 3 | -1.0 | -0.88 | -0.000171 |
| 4 | -1.0 | -0.84 | 0.000585 |
| 5 | -1.0 | -0.80 | -0.000033 |
| 6 | -1.0 | -0.76 | 0.000067 |
| 7 | -1.0 | -0.72 | 0.000194 |
| 8 | -1.0 | -0.68 | -0.000390 |
| 9 | -1.0 | -0.64 | 0.000402 |
Pandas has built-in support for various forms of plotting. This does not, however, support MultiIndex at the moment so we use reset_index to make the data available for plotting.
[11]:
df1.reset_index().plot.scatter("dac_ch1", "dac_ch2", c="dmm_v2")
[11]:
<Axes: xlabel='dac_ch1', ylabel='dac_ch2'>
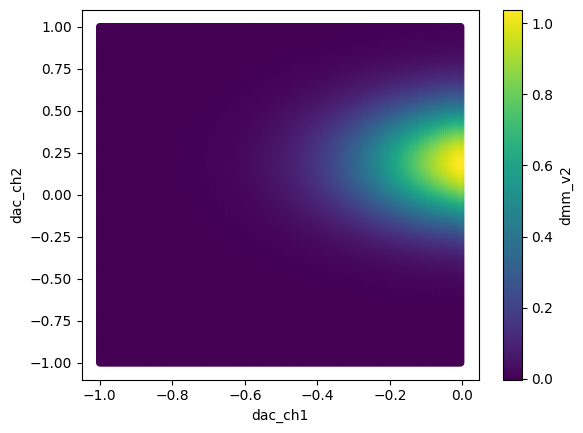
Similarly, for the other dataframe:
[12]:
df2.reset_index().plot.scatter("dac_ch1", "dac_ch2", c="dmm_v2")
[12]:
<Axes: xlabel='dac_ch1', ylabel='dac_ch2'>
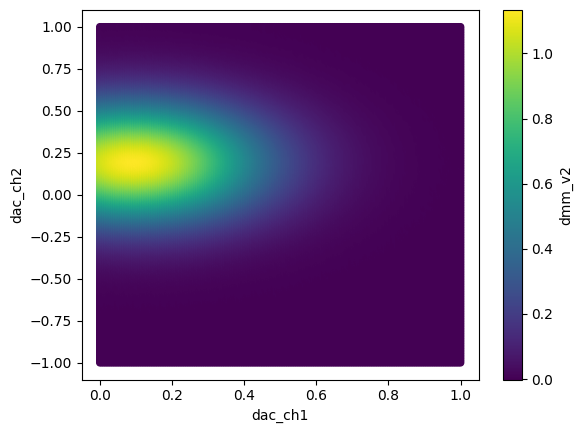
Merging two dataframes with the same labels is fairly simple.
[13]:
df = pd.concat([df1, df2], sort=True)
[14]:
df.reset_index().plot.scatter("dac_ch1", "dac_ch2", c="dmm_v2")
[14]:
<Axes: xlabel='dac_ch1', ylabel='dac_ch2'>
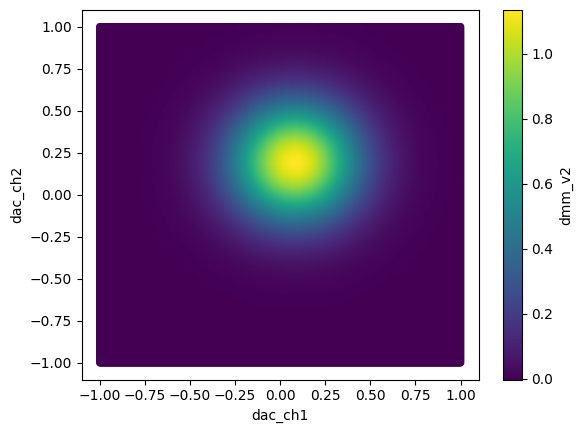
It is also possible to select a subset of data from the datframe based on the x and y values.
[15]:
df.loc[(slice(-1, -0.95), slice(-1, -0.97)), :]
[15]:
| dmm_v2 | ||
|---|---|---|
| dac_ch1 | dac_ch2 | |
| -1.00 | -1.0 | 0.000132 |
| -0.98 | -1.0 | -0.000513 |
| -0.96 | -1.0 | -0.000975 |
Working with XArray¶
In many cases when working with data on rectangular grids it may be more convenient to export the data to a XArray Dataset or DataArray. This is especially true when working in multi-dimentional parameter space.
Let’s setup and rerun the above measurment with the added dependent parameter dmm.v1.
[16]:
meas.register_parameter(
dmm.v1, setpoints=(dac.ch1, dac.ch2)
) # register the 2nd dependent parameter
[16]:
<qcodes.dataset.measurements.Measurement at 0x7ffa6b58fe00>
[17]:
# run a 2D sweep
with meas.run() as datasaver:
for v1 in np.linspace(-1, 1, 50):
for v2 in np.linspace(-1, 1, 51):
dac.ch1(v1)
dac.ch2(v2)
val1 = dmm.v1.get()
val2 = dmm.v2.get()
datasaver.add_result(
(dac.ch1, v1), (dac.ch2, v2), (dmm.v1, val1), (dmm.v2, val2)
)
dataset3 = datasaver.dataset
Starting experimental run with id: 3.
The QCoDeS DataSet can be directly converted to a XArray Dataset from the to_xarray_dataset method. This method returns the data from measured (dependent) parameters to an XArray Dataset. It’s also possible to return a dictionary of XArray DataArray’s if you were only interested in a single parameter using the to_xarray_dataarray method. For convenience we will access the DataArray’s from XArray’s Dataset directly.
Please note that the to_xarray_dataset is only intended to be used when all dependent parameters have the same setpoint. If this is not the case for the DataSet then to_xarray_dataarray should be used.
[18]:
xaDataSet = dataset3.to_xarray_dataset()
[19]:
xaDataSet
[19]:
<xarray.Dataset> Size: 42kB
Dimensions: (dac_ch1: 50, dac_ch2: 51)
Coordinates:
* dac_ch1 (dac_ch1) float64 400B -1.0 -0.9592 -0.9184 ... 0.9184 0.9592 1.0
* dac_ch2 (dac_ch2) float64 408B -1.0 -0.96 -0.92 -0.88 ... 0.92 0.96 1.0
Data variables:
dmm_v1 (dac_ch1, dac_ch2) float64 20kB 6.149 5.939 6.009 ... 4.104 4.192
dmm_v2 (dac_ch1, dac_ch2) float64 20kB -0.0004611 ... -9.262e-05
Attributes: (12/14)
ds_name: results
sample_name: no sample
exp_name: working_with_pandas
snapshot: {"station": {"instruments": {"dmm": {"functions...
guid: 66d5e09e-0000-0000-0000-019fa297b43d
run_timestamp: 2026-07-27 08:01:18
... ...
captured_counter: 3
run_id: 3
run_description: {"version": 3, "interdependencies": {"paramspec...
parent_dataset_links: []
run_timestamp_raw: 1785139278.9180424
completed_timestamp_raw: 1785139279.4032986As mentioned above it’s also possible to work with a XArray DataArray directly from the DataSet. The DataArray can only contain a single dependent variable and can be obtained from the Dataset by indexing using the parameter name.
[20]:
xaDataArray = xaDataSet["dmm_v2"] # or xaDataSet.dmm_v2
[21]:
xaDataArray
[21]:
<xarray.DataArray 'dmm_v2' (dac_ch1: 50, dac_ch2: 51)> Size: 20kB
array([[-4.61118325e-04, -7.14510711e-04, 5.52608355e-04, ...,
-7.44438372e-04, 1.33972808e-04, 1.21523218e-03],
[ 1.05482388e-03, 5.50798876e-05, 2.25732669e-04, ...,
-8.10531860e-04, 2.10618330e-04, 7.91172025e-04],
[-1.77574518e-04, 7.93806686e-05, 1.05777370e-03, ...,
-1.57123990e-04, -2.23663768e-04, -8.87602212e-05],
...,
[ 1.51700270e-04, 6.50110709e-04, 3.26238006e-04, ...,
-5.60348974e-04, -2.49863038e-04, -5.69708471e-04],
[ 3.21202971e-04, 7.62364654e-04, 3.75423538e-04, ...,
-2.22708248e-04, 5.09634637e-04, 5.19073065e-04],
[ 1.03151376e-03, -7.29667305e-04, 1.39237185e-04, ...,
5.17932759e-04, -1.43071825e-04, -9.26213767e-05]],
shape=(50, 51))
Coordinates:
* dac_ch1 (dac_ch1) float64 400B -1.0 -0.9592 -0.9184 ... 0.9184 0.9592 1.0
* dac_ch2 (dac_ch2) float64 408B -1.0 -0.96 -0.92 -0.88 ... 0.92 0.96 1.0
Attributes:
name: dmm_v2
paramtype: numeric
label: Gate v2
unit: V
inferred_from: []
depends_on: ['dac_ch1', 'dac_ch2']
units: V
long_name: Gate v2[22]:
fig, ax = plt.subplots(2, 2)
xaDataSet.dmm_v2.plot(ax=ax[0, 0])
xaDataSet.dmm_v1.plot(ax=ax[1, 1])
xaDataSet.dmm_v2.mean(dim="dac_ch1").plot(ax=ax[1, 0])
xaDataSet.dmm_v1.mean(dim="dac_ch2").plot(ax=ax[0, 1])
fig.tight_layout()
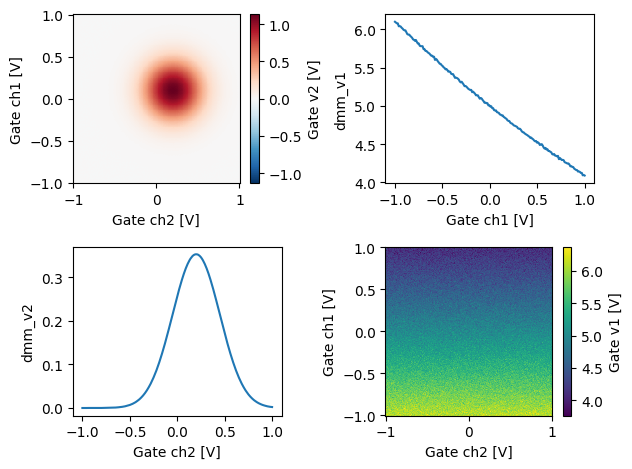
Above we demonstrated a few ways to index the data from a DataArray. For instance the DataArray can be directly plotted, the extracted mean or a specific row/column can also be plotted.
Working with XArray on non gridded data.¶
Sometimes your data does not fit well on a regular grid. Perhaps you are sweeping 2 parameters at the same time or you are messuring at random points.
[23]:
# run a 2D sweep
with meas.run() as datasaver:
for v1, v2 in zip(np.linspace(-1, 1, 50), np.linspace(-1, 1, 51)):
dac.ch1(v1)
dac.ch2(v2)
val1 = dmm.v1.get()
val2 = dmm.v2.get()
datasaver.add_result(
(dac.ch1, v1), (dac.ch2, v2), (dmm.v1, val1), (dmm.v2, val2)
)
dataset4 = datasaver.dataset
Starting experimental run with id: 4.
[24]:
xaDataSet = dataset4.to_xarray_dataset()
If this is the case QCoDeS will export the data using a XArray MultiIndex.
[25]:
xaDataSet
[25]:
<xarray.Dataset> Size: 2kB
Dimensions: (multi_index: 50)
Coordinates:
* multi_index (multi_index) object 400B MultiIndex
* dac_ch1 (multi_index) float64 400B -1.0 -0.9592 -0.9184 ... 0.9592 1.0
* dac_ch2 (multi_index) float64 400B -1.0 -0.96 -0.92 ... 0.88 0.92 0.96
Data variables:
dmm_v1 (multi_index) float64 400B 5.79 6.156 5.926 ... 4.202 4.013
dmm_v2 (multi_index) float64 400B -6.733e-06 0.0003082 ... -0.0001626
Attributes: (12/14)
ds_name: results
sample_name: no sample
exp_name: working_with_pandas
snapshot: {"station": {"instruments": {"dmm": {"functions...
guid: 5cded572-0000-0000-0000-019fa297babc
run_timestamp: 2026-07-27 08:01:20
... ...
captured_counter: 4
run_id: 4
run_description: {"version": 3, "interdependencies": {"paramspec...
parent_dataset_links: []
run_timestamp_raw: 1785139280.581354
completed_timestamp_raw: 1785139280.601087Note how the expected coordinates can be seen above along with a coordinate called multi_index
QCoDeS has build in support for exporting such datasets to NetCDF files using cf_xarray to compress and decompress the data. Note however, that if you manually export or import such XArray datasets to / from NetCDF you will be responsible for compressing / decompressing as needed.