Provides an analysis of the distribution of a selected metric. Returns a faceted histogram by default. Additional options available to return the underlying frequency table.
create_hist(
data,
metric,
hrvar = "Organization",
mingroup = 5,
binwidth = 1,
ncol = NULL,
return = "plot"
)Arguments
- data
A Standard Person Query dataset in the form of a data frame.
- metric
String containing the name of the metric, e.g. "Collaboration_hours"
- hrvar
String containing the name of the HR Variable by which to split metrics. Defaults to
"Organization". To run the analysis on the total instead of splitting by an HR attribute, supplyNULL(without quotes).- mingroup
Numeric value setting the privacy threshold / minimum group size. Defaults to 5.
- binwidth
Numeric value for setting
binwidthargument withinggplot2::geom_histogram(). Defaults to 1.- ncol
Numeric value setting the number of columns on the plot. Defaults to
NULL(automatic).- return
String specifying what to return. This must be one of the following strings:
"plot""table""data""frequency"
See
Valuefor more information.
Value
A different output is returned depending on the value passed to the return
argument:
"plot": 'ggplot' object. A faceted histogram for the metric."table": data frame. A summary table for the metric."data": data frame. Data with calculated person averages."frequency: list of data frames. Each data frame contains the frequencies used in each panel of the plotted histogram.
See also
Other Flexible:
create_bar(),
create_bar_asis(),
create_boxplot(),
create_bubble(),
create_density(),
create_dist(),
create_fizz(),
create_inc(),
create_line(),
create_line_asis(),
create_period_scatter(),
create_rank(),
create_sankey(),
create_scatter(),
create_stacked(),
create_tracking(),
create_trend(),
period_change()
Examples
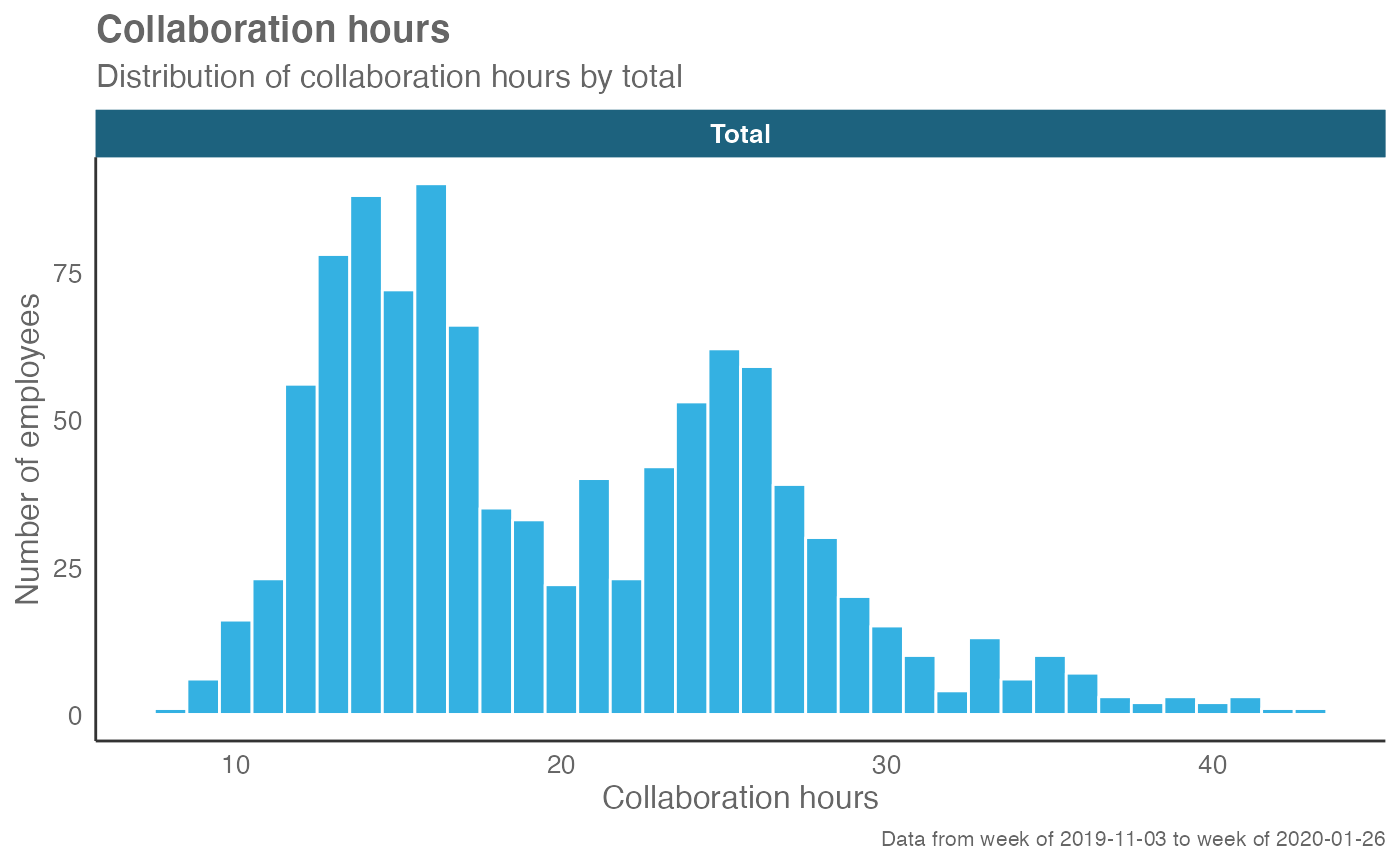
# Return plot for whole organization
create_hist(sq_data, metric = "Collaboration_hours", hrvar = NULL)
 # Return plot
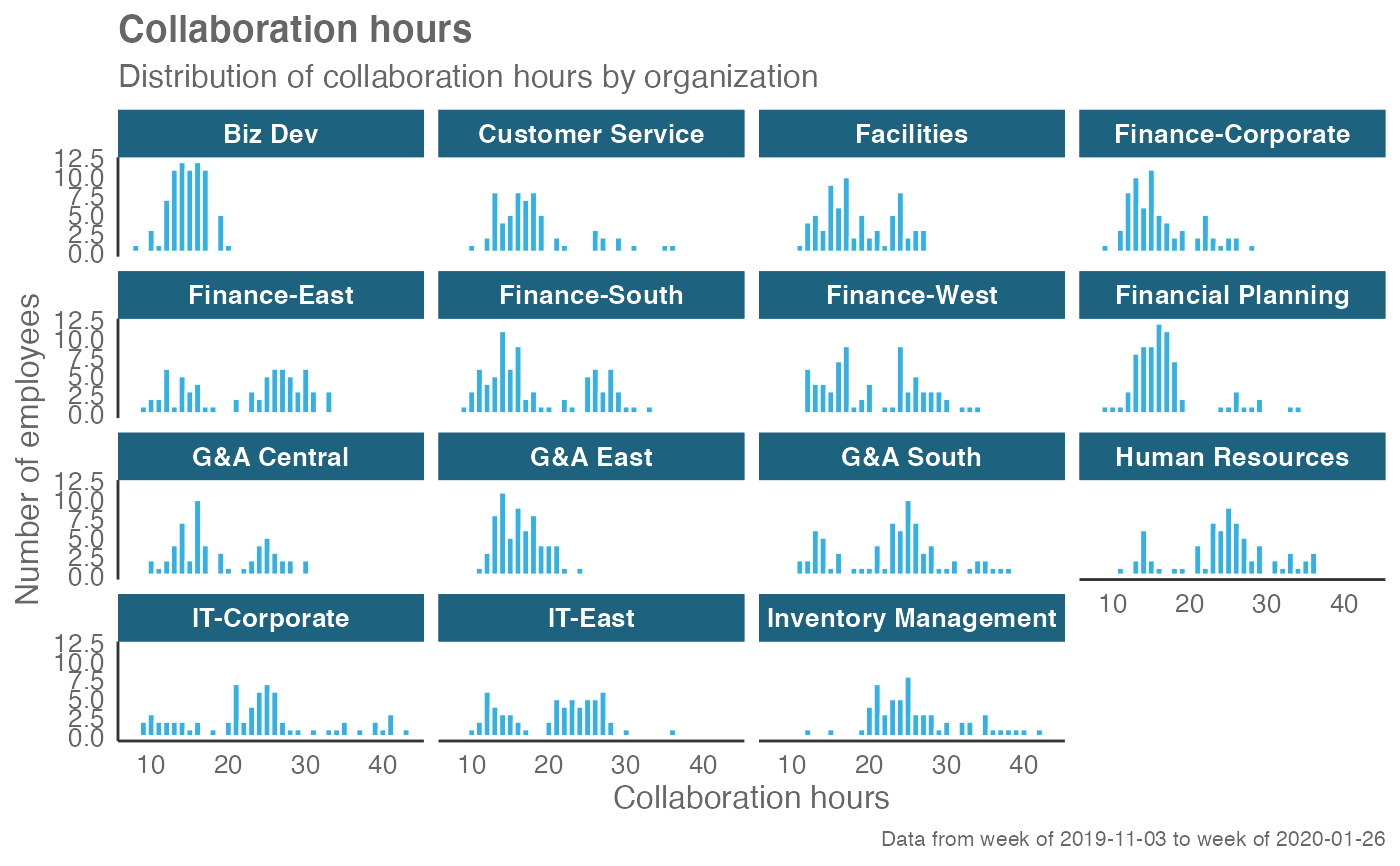
create_hist(sq_data, metric = "Collaboration_hours", hrvar = "Organization")
# Return plot
create_hist(sq_data, metric = "Collaboration_hours", hrvar = "Organization")
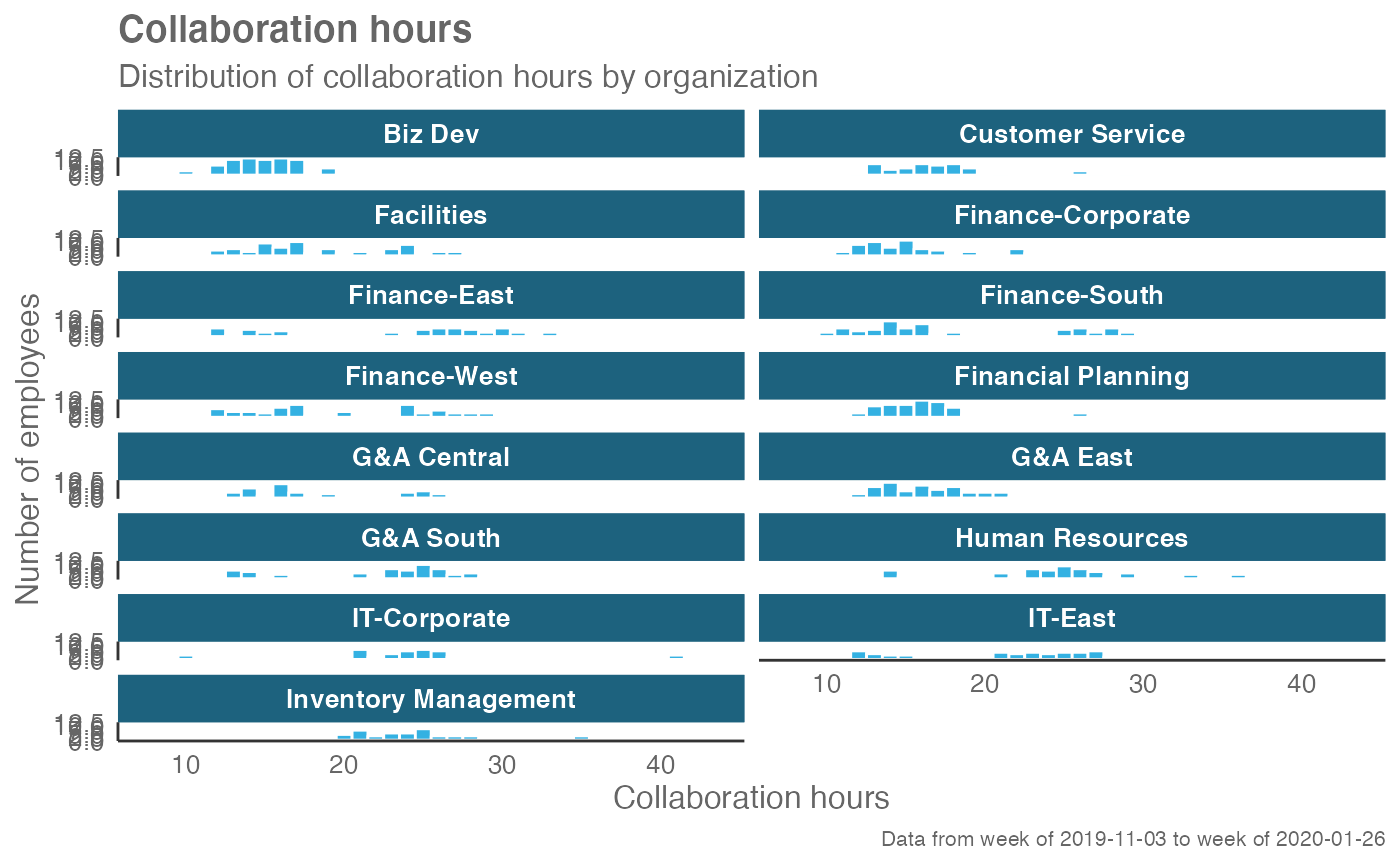
 # Return plot but coerce plot to two columns
create_hist(sq_data, metric = "Collaboration_hours", hrvar = "Organization", ncol = 2)
# Return plot but coerce plot to two columns
create_hist(sq_data, metric = "Collaboration_hours", hrvar = "Organization", ncol = 2)
 # Return summary table
create_hist(sq_data,
metric = "Collaboration_hours",
hrvar = "Organization",
return = "table")
#> # A tibble: 5 × 6
#> group mean median max min Employee_Count
#> <chr> <dbl> <dbl> <dbl> <dbl> <int>
#> 1 Customer Service 18.9 18.2 33.3 10.4 61
#> 2 Finance 20.0 17.7 37.6 9.19 292
#> 3 Financial Planning 17.3 15.9 35.1 9.57 75
#> 4 Human Resources 24.9 25.8 37.4 10.8 71
#> 5 IT 22.6 23.6 43.5 8.06 130
# Return summary table
create_hist(sq_data,
metric = "Collaboration_hours",
hrvar = "Organization",
return = "table")
#> # A tibble: 5 × 6
#> group mean median max min Employee_Count
#> <chr> <dbl> <dbl> <dbl> <dbl> <int>
#> 1 Customer Service 18.9 18.2 33.3 10.4 61
#> 2 Finance 20.0 17.7 37.6 9.19 292
#> 3 Financial Planning 17.3 15.9 35.1 9.57 75
#> 4 Human Resources 24.9 25.8 37.4 10.8 71
#> 5 IT 22.6 23.6 43.5 8.06 130