Period comparison scatter plot for any two metrics
Source:R/create_period_scatter.R
create_period_scatter.RdReturns two side-by-side scatter plots representing two selected metrics, using colour to map an HR attribute and size to represent number of employees. Returns a faceted scatter plot by default, with additional options to return a summary table.
create_period_scatter(
data,
hrvar = "Organization",
metric_x = "Multitasking_meeting_hours",
metric_y = "Meeting_hours",
before_start = min(as.Date(data$Date, "%m/%d/%Y")),
before_end,
after_start = as.Date(before_end) + 1,
after_end = max(as.Date(data$Date, "%m/%d/%Y")),
before_label = "Period 1",
after_label = "Period 2",
mingroup = 5,
return = "plot"
)Arguments
- data
A Standard Person Query dataset in the form of a data frame.
- hrvar
HR Variable by which to split metrics. Accepts a character vector, defaults to "Organization" but accepts any character vector, e.g. "LevelDesignation"
- metric_x
Character string containing the name of the metric, e.g. "Collaboration_hours"
- metric_y
Character string containing the name of the metric, e.g. "Collaboration_hours"
- before_start
Start date of "before" time period in YYYY-MM-DD
- before_end
End date of "before" time period in YYYY-MM-DD
- after_start
Start date of "after" time period in YYYY-MM-DD
- after_end
End date of "after" time period in YYYY-MM-DD
- before_label
String to specify a label for the "before" period. Defaults to "Period 1".
- after_label
String to specify a label for the "after" period. Defaults to "Period 2".
- mingroup
Numeric value setting the privacy threshold / minimum group size. Defaults to 5.
- return
Character vector specifying what to return, defaults to "plot". Valid inputs are "plot" and "table".
Value
Returns a 'ggplot' object showing two scatter plots side by side representing the two periods.
Details
This is a general purpose function that powers all the functions in the package that produce faceted scatter plots.
See also
Other Visualization:
afterhours_dist(),
afterhours_fizz(),
afterhours_line(),
afterhours_rank(),
afterhours_summary(),
afterhours_trend(),
collaboration_area(),
collaboration_dist(),
collaboration_fizz(),
collaboration_line(),
collaboration_rank(),
collaboration_sum(),
collaboration_trend(),
create_bar(),
create_bar_asis(),
create_boxplot(),
create_bubble(),
create_dist(),
create_fizz(),
create_inc(),
create_line(),
create_line_asis(),
create_rank(),
create_sankey(),
create_scatter(),
create_stacked(),
create_tracking(),
create_trend(),
email_dist(),
email_fizz(),
email_line(),
email_rank(),
email_summary(),
email_trend(),
external_dist(),
external_fizz(),
external_line(),
external_network_plot(),
external_rank(),
external_sum(),
hr_trend(),
hrvar_count(),
hrvar_trend(),
internal_network_plot(),
keymetrics_scan(),
meeting_dist(),
meeting_fizz(),
meeting_line(),
meeting_quality(),
meeting_rank(),
meeting_summary(),
meeting_trend(),
meetingtype_dist(),
meetingtype_dist_ca(),
meetingtype_dist_mt(),
meetingtype_summary(),
mgrcoatt_dist(),
mgrrel_matrix(),
one2one_dist(),
one2one_fizz(),
one2one_freq(),
one2one_line(),
one2one_rank(),
one2one_sum(),
one2one_trend(),
period_change(),
workloads_dist(),
workloads_fizz(),
workloads_line(),
workloads_rank(),
workloads_summary(),
workloads_trend(),
workpatterns_area(),
workpatterns_rank()
Other Flexible:
create_bar(),
create_bar_asis(),
create_boxplot(),
create_bubble(),
create_density(),
create_dist(),
create_fizz(),
create_hist(),
create_inc(),
create_line(),
create_line_asis(),
create_rank(),
create_sankey(),
create_scatter(),
create_stacked(),
create_tracking(),
create_trend(),
period_change()
Other Time-series:
IV_by_period(),
create_line(),
create_line_asis(),
create_trend(),
period_change()
Examples
# Return plot
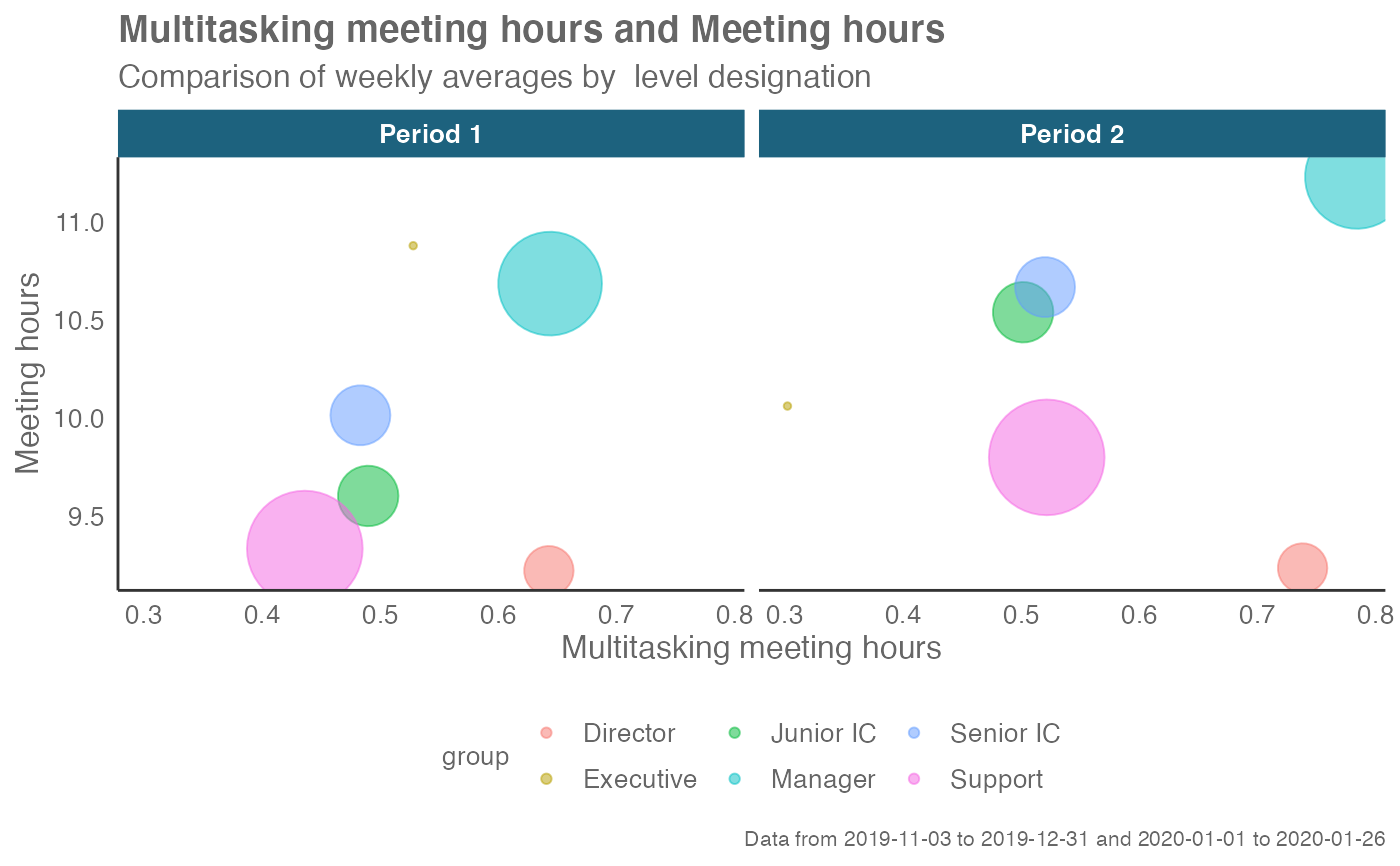
create_period_scatter(sq_data,
hrvar = "LevelDesignation",
before_start = "2019-12-15",
before_end = "2019-12-29",
after_start = "2020-01-05",
after_end = "2020-01-26")
#> Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
#> of ggplot2 3.3.4.
#> ℹ The deprecated feature was likely used in the wpa package.
#> Please report the issue at <https://github.com/microsoft/wpa/issues/>.
 # Return a summary table
create_period_scatter(sq_data, before_end = "2019-12-31", return = "table")
#> # A tibble: 10 × 5
#> group Multitasking_meeting_hours Meeting_hours Period n
#> <chr> <dbl> <dbl> <chr> <int>
#> 1 Customer Service 0.417 9.02 Period 1 61
#> 2 Finance 0.661 10.2 Period 1 292
#> 3 Financial Planning 0.424 8.07 Period 1 75
#> 4 Human Resources 0.656 13.0 Period 1 71
#> 5 IT 0.469 11.6 Period 1 130
#> 6 Customer Service 0.560 9.20 Period 2 61
#> 7 Finance 0.698 9.96 Period 2 292
#> 8 Financial Planning 0.391 8.64 Period 2 75
#> 9 Human Resources 0.712 13.0 Period 2 71
#> 10 IT 0.712 11.8 Period 2 130
# Return a summary table
create_period_scatter(sq_data, before_end = "2019-12-31", return = "table")
#> # A tibble: 10 × 5
#> group Multitasking_meeting_hours Meeting_hours Period n
#> <chr> <dbl> <dbl> <chr> <int>
#> 1 Customer Service 0.417 9.02 Period 1 61
#> 2 Finance 0.661 10.2 Period 1 292
#> 3 Financial Planning 0.424 8.07 Period 1 75
#> 4 Human Resources 0.656 13.0 Period 1 71
#> 5 IT 0.469 11.6 Period 1 130
#> 6 Customer Service 0.560 9.20 Period 2 61
#> 7 Finance 0.698 9.96 Period 2 292
#> 8 Financial Planning 0.391 8.64 Period 2 75
#> 9 Human Resources 0.712 13.0 Period 2 71
#> 10 IT 0.712 11.8 Period 2 130