Creates a sum total calculation using selected metrics, where the typical use case is to create different definitions of collaboration hours. Returns a stacked bar plot by default. Additional options available to return a summary table.
create_stacked(
data,
hrvar = "Organization",
metrics = c("Meeting_hours", "Email_hours"),
mingroup = 5,
return = "plot",
stack_colours = c("#1d627e", "#34b1e2", "#b4d5dd", "#adc0cb"),
percent = FALSE,
plot_title = "Collaboration Hours",
plot_subtitle = paste("Average by", tolower(camel_clean(hrvar))),
legend_lab = NULL,
rank = "descending",
xlim = NULL,
text_just = 0.5,
text_colour = "#FFFFFF"
)Arguments
- data
A Standard Person Query dataset in the form of a data frame.
- hrvar
String containing the name of the HR Variable by which to split metrics. Defaults to
"Organization". To run the analysis on the total instead of splitting by an HR attribute, supplyNULL(without quotes).- metrics
A character vector to specify variables to be used in calculating the "Total" value, e.g. c("Meeting_hours", "Email_hours"). The order of the variable names supplied determine the order in which they appear on the stacked plot.
- mingroup
Numeric value setting the privacy threshold / minimum group size. Defaults to 5.
- return
Character vector specifying what to return, defaults to "plot". Valid inputs are "plot" and "table".
- stack_colours
A character vector to specify the colour codes for the stacked bar charts.
- percent
Logical value to determine whether to show labels as percentage signs. Defaults to
FALSE.- plot_title
String. Option to override plot title.
- plot_subtitle
String. Option to override plot subtitle.
- legend_lab
String. Option to override legend title/label. Defaults to
NULL, where the metric name will be populated instead.- rank
String specifying how to rank the bars. Valid inputs are:
"descending"- ranked highest to lowest from top to bottom (default)."ascending"- ranked lowest to highest from top to bottom.NULL- uses the original levels of the HR attribute.
- xlim
An option to set max value in x axis.
- text_just
![[Experimental]](figures/lifecycle-experimental.svg) A numeric value
controlling for the horizontal position of the text labels. Defaults to
0.5.
A numeric value
controlling for the horizontal position of the text labels. Defaults to
0.5.- text_colour
- String to specify
colour to use for the text labels. Defaults to
"#FFFFFF".
Value
Returns a 'ggplot' object by default, where 'plot' is passed in return.
When 'table' is passed, a summary table is returned as a data frame.
See also
Other Visualization:
afterhours_dist(),
afterhours_fizz(),
afterhours_line(),
afterhours_rank(),
afterhours_summary(),
afterhours_trend(),
collaboration_area(),
collaboration_dist(),
collaboration_fizz(),
collaboration_line(),
collaboration_rank(),
collaboration_sum(),
collaboration_trend(),
create_bar(),
create_bar_asis(),
create_boxplot(),
create_bubble(),
create_dist(),
create_fizz(),
create_inc(),
create_line(),
create_line_asis(),
create_period_scatter(),
create_rank(),
create_sankey(),
create_scatter(),
create_tracking(),
create_trend(),
email_dist(),
email_fizz(),
email_line(),
email_rank(),
email_summary(),
email_trend(),
external_dist(),
external_fizz(),
external_line(),
external_network_plot(),
external_rank(),
external_sum(),
hr_trend(),
hrvar_count(),
hrvar_trend(),
internal_network_plot(),
keymetrics_scan(),
meeting_dist(),
meeting_fizz(),
meeting_line(),
meeting_quality(),
meeting_rank(),
meeting_summary(),
meeting_trend(),
meetingtype_dist(),
meetingtype_dist_ca(),
meetingtype_dist_mt(),
meetingtype_summary(),
mgrcoatt_dist(),
mgrrel_matrix(),
one2one_dist(),
one2one_fizz(),
one2one_freq(),
one2one_line(),
one2one_rank(),
one2one_sum(),
one2one_trend(),
period_change(),
workloads_dist(),
workloads_fizz(),
workloads_line(),
workloads_rank(),
workloads_summary(),
workloads_trend(),
workpatterns_area(),
workpatterns_rank()
Other Flexible:
create_bar(),
create_bar_asis(),
create_boxplot(),
create_bubble(),
create_density(),
create_dist(),
create_fizz(),
create_hist(),
create_inc(),
create_line(),
create_line_asis(),
create_period_scatter(),
create_rank(),
create_sankey(),
create_scatter(),
create_tracking(),
create_trend(),
period_change()
Examples
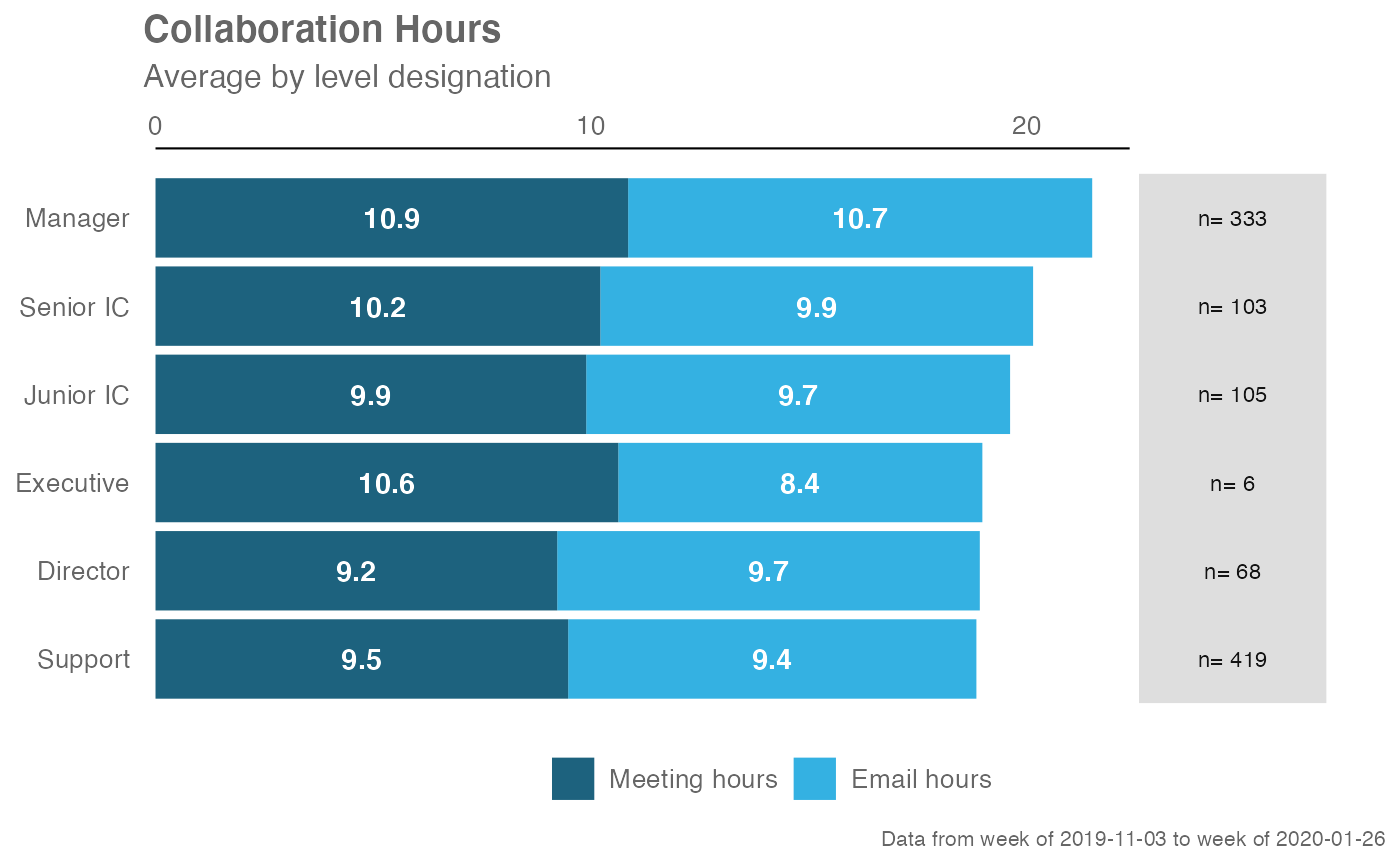
sq_data %>%
create_stacked(hrvar = "LevelDesignation",
metrics = c("Meeting_hours", "Email_hours"),
return = "plot")
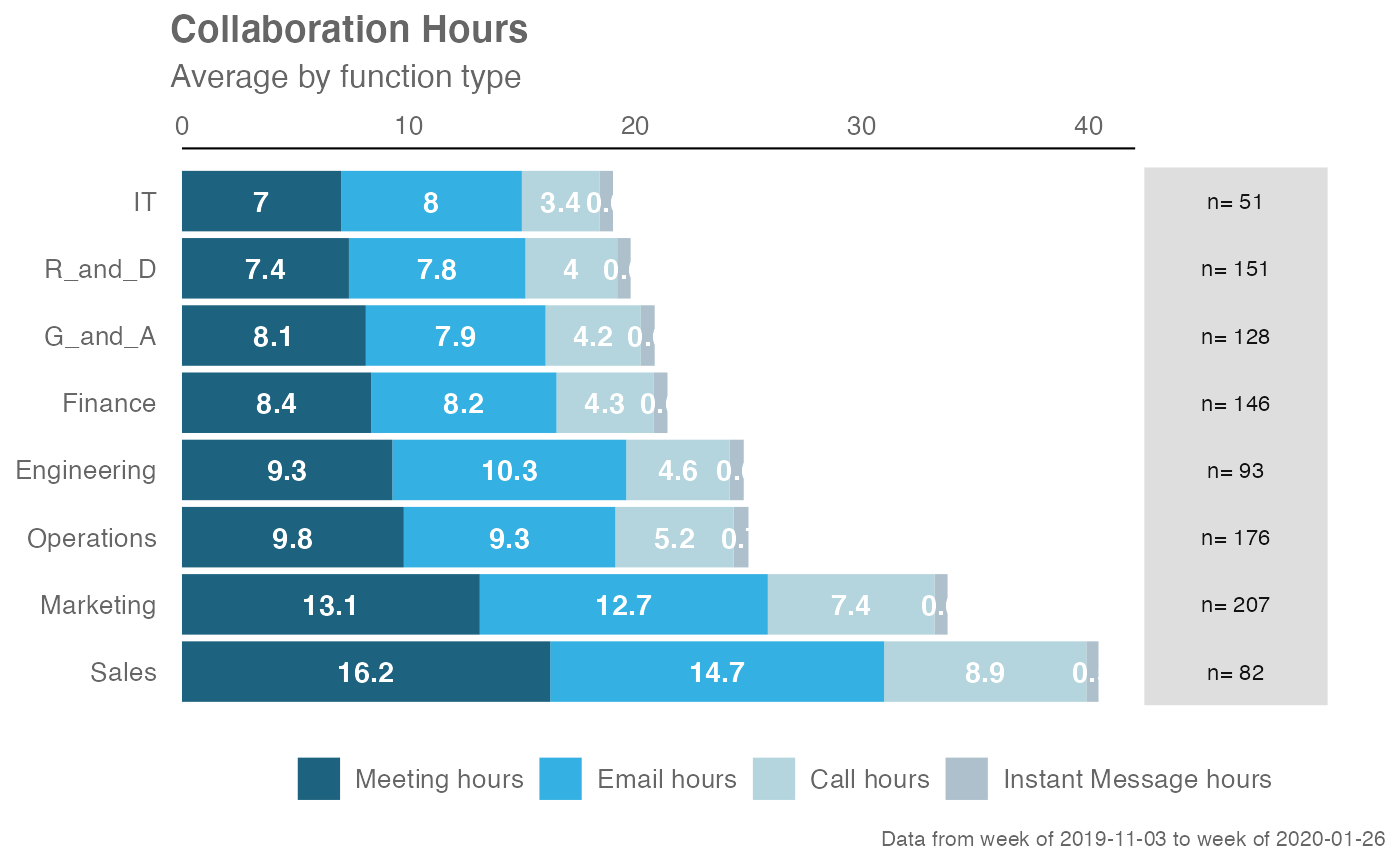
 sq_data %>%
create_stacked(hrvar = "FunctionType",
metrics = c("Meeting_hours",
"Email_hours",
"Call_hours",
"Instant_Message_hours"),
return = "plot",
rank = "ascending")
sq_data %>%
create_stacked(hrvar = "FunctionType",
metrics = c("Meeting_hours",
"Email_hours",
"Call_hours",
"Instant_Message_hours"),
return = "plot",
rank = "ascending")
 sq_data %>%
create_stacked(hrvar = "FunctionType",
metrics = c("Meeting_hours",
"Email_hours",
"Call_hours",
"Instant_Message_hours"),
return = "table")
#> # A tibble: 8 × 7
#> group Meeting_hours Email_hours Call_hours Instant_Message_hours Total
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Engineering 9.41 10.5 4.26 0.654 24.9
#> 2 Finance 7.83 7.88 3.87 0.618 20.2
#> 3 G_and_A 7.72 7.75 3.74 0.609 19.8
#> 4 IT 7.71 9.37 3.22 0.651 20.9
#> 5 Marketing 13.5 13.1 7.15 0.582 34.3
#> 6 Operations 10.6 9.72 5.21 0.680 26.2
#> 7 R_and_D 7.71 8.06 3.92 0.634 20.3
#> 8 Sales 16.4 14.7 8.52 0.529 40.1
#> # ℹ 1 more variable: Employee_Count <int>
sq_data %>%
create_stacked(hrvar = "FunctionType",
metrics = c("Meeting_hours",
"Email_hours",
"Call_hours",
"Instant_Message_hours"),
return = "table")
#> # A tibble: 8 × 7
#> group Meeting_hours Email_hours Call_hours Instant_Message_hours Total
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Engineering 9.41 10.5 4.26 0.654 24.9
#> 2 Finance 7.83 7.88 3.87 0.618 20.2
#> 3 G_and_A 7.72 7.75 3.74 0.609 19.8
#> 4 IT 7.71 9.37 3.22 0.651 20.9
#> 5 Marketing 13.5 13.1 7.15 0.582 34.3
#> 6 Operations 10.6 9.72 5.21 0.680 26.2
#> 7 R_and_D 7.71 8.06 3.92 0.634 20.3
#> 8 Sales 16.4 14.7 8.52 0.529 40.1
#> # ℹ 1 more variable: Employee_Count <int>