Compute a Flexibility Index based on the Hourly Collaboration Query
Source:R/flex_index.R
flex_index.Rd![[Experimental]](figures/lifecycle-experimental.svg)
Pass an Hourly Collaboration query and compute a Flexibility Index for the entire population. The Flexibility Index is a quantitative measure of the freedom for employees to work at a time of their choice.
flex_index(
data,
hrvar = NULL,
signals = c("email", "IM"),
active_threshold = 0,
start_hour = "0900",
end_hour = "1700",
return = "plot",
plot_method = "common",
mode = "binary"
)Arguments
- data
Hourly Collaboration query to be passed through as data frame.
- hrvar
A string specifying the HR attribute to cut the data by. Defaults to NULL. This only affects the function when "table" is returned.
- signals
Character vector to specify which collaboration metrics to use:
a combination of signals, such as
c("email", "IM")(default)"email"for emails only"IM"for Teams messages only"unscheduled_calls"for Unscheduled Calls only"meetings"for Meetings only
- active_threshold
A numeric value specifying the minimum number of signals to be greater than in order to qualify as active. Defaults to 0.
- start_hour
A character vector specifying starting hours, e.g.
"0900"- end_hour
A character vector specifying end hours, e.g.
"1700"- return
String specifying what to return. This must be one of the following strings:
"plot""data""table"
See
Valuefor more information.- plot_method
Character string for determining which plot to return.
"sample"plots a sample of ten working pattern"common"plots the ten most common working patterns"time"plots the Flexibility Index for the group over time
- mode
String specifying aggregation method for plot. Only applicable when
return = "plot". Valid options include:"binary": convert hourly activity into binary blocks. In the plot, each block would display as solid."prop": calculate proportion of signals in each hour over total signals across 24 hours, then average across all work weeks. In the plot, each block would display as a heatmap.
Value
A different output is returned depending on the value passed to the return
argument:
"plot": 'ggplot' object. A random of ten working patterns are displayed, with diagnostic data and the Flexibility Index shown on the plot."data": data frame. The original input data appended with the Flexibility Index and the component scores. Can be used withplot_flex_index()to recreate visuals found inflex_index()."table": data frame. A summary table for the metric.
Details
The Flexibility Index is a metric that has been developed to quantify and measure flexibility using behavioural data from Viva Insights. Flexibility here refers to the freedom of employees to adopt a working arrangement of their own choice, and more specifically refers to time flexibility (whenever I want) as opposed to geographical flexibility (wherever I want).
The Flexibility Index is a score between 0 and 1, and is calculated based on three component measures:
ChangeHours: this represents the freedom to define work start and end time. Teams that embrace flexibility allow members to start and end their workday at different times.TakeBreaks: this represents the freedom define one's own schedule. In teams that embrace flexibility, some members will choose to organize / split their day in different ways (e.g. take a long lunch-break, disconnect in the afternoon and reconnect in the evening, etc.).ControlHours: this represents the freedom to switch off. Members who choose alternative arrangements should be able to maintain a workload that is broadly equivalent to those that follow standard arrangements.
The Flexibility Index returns with one single score for each person-week,
plus the three sub-component binary variables (TakeBreaks,
ChangeHours, ControlHours). At the person-week level, each score can only
have the values 0, 0.33, 0.66, and 1. The Flexibility Index should only be
interpreted as a group of person-weeks, e.g. the average Flexibility
Index of a team of 6 over time, where the possible values would range from 0
to 1.
Context
The central feature of flexible working arrangements is that it is the employee rather the employer who chooses the working arrangement. Observed flexibility serves as a proxy to assess whether a flexible working arrangement are in place. The Flexibility Index is an attempt to create such a proxy for quantifying and measuring flexibility, using behavioural data from Viva Insights.
Recurring disconnection time
The key component of TakeBreaks in the Flexibility Index is best
interpreted as 'recurring disconnection time'. This denotes an hourly block
where there is consistently no activity occurring throughout the week. Note
that this applies a stricter criterion compared to the common definition of
a break, which is simply a time interval where no active work is being
done, and thus the more specific terminology 'recurring disconnection time'
is preferred.
Returning the raw data
The raw data containing the computed Flexibility Index can be returned with the following:
See also
Examples
# \donttest{
# Create a sample small dataset
orgs <- c("Customer Service", "Financial Planning", "Biz Dev")
em_data <- em_data[em_data$Organization %in% orgs, ]
# Examples of how to test the plotting options individually
# Sample of 10 work patterns
em_data %>%
flex_index(return = "plot", plot_method = "sample")
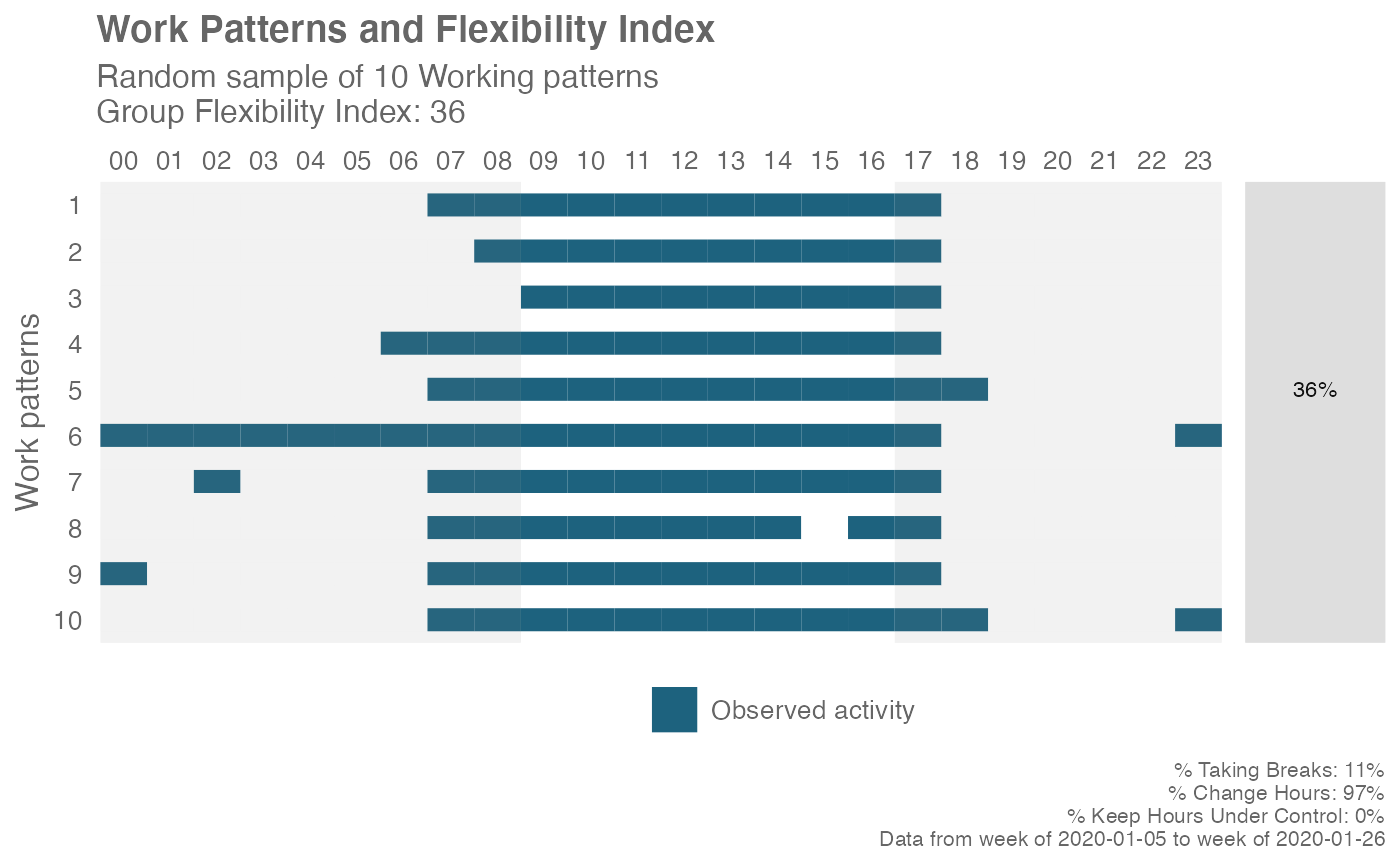 # 10 most common work patterns
em_data %>%
flex_index(return = "plot", plot_method = "common")
# 10 most common work patterns
em_data %>%
flex_index(return = "plot", plot_method = "common")
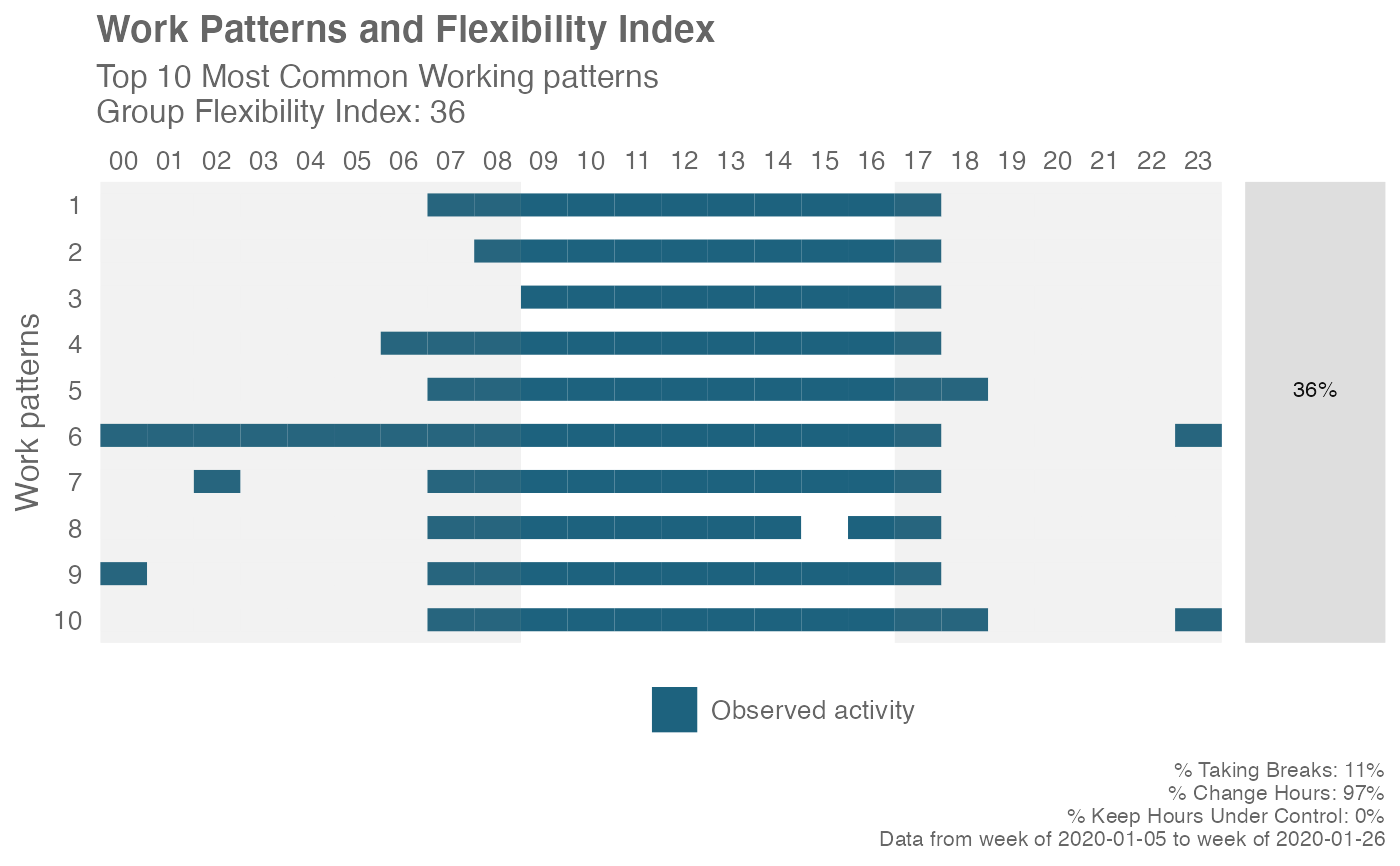 # Plot Flexibility Index over time
em_data %>%
flex_index(return = "plot", plot_method = "time")
# Plot Flexibility Index over time
em_data %>%
flex_index(return = "plot", plot_method = "time")
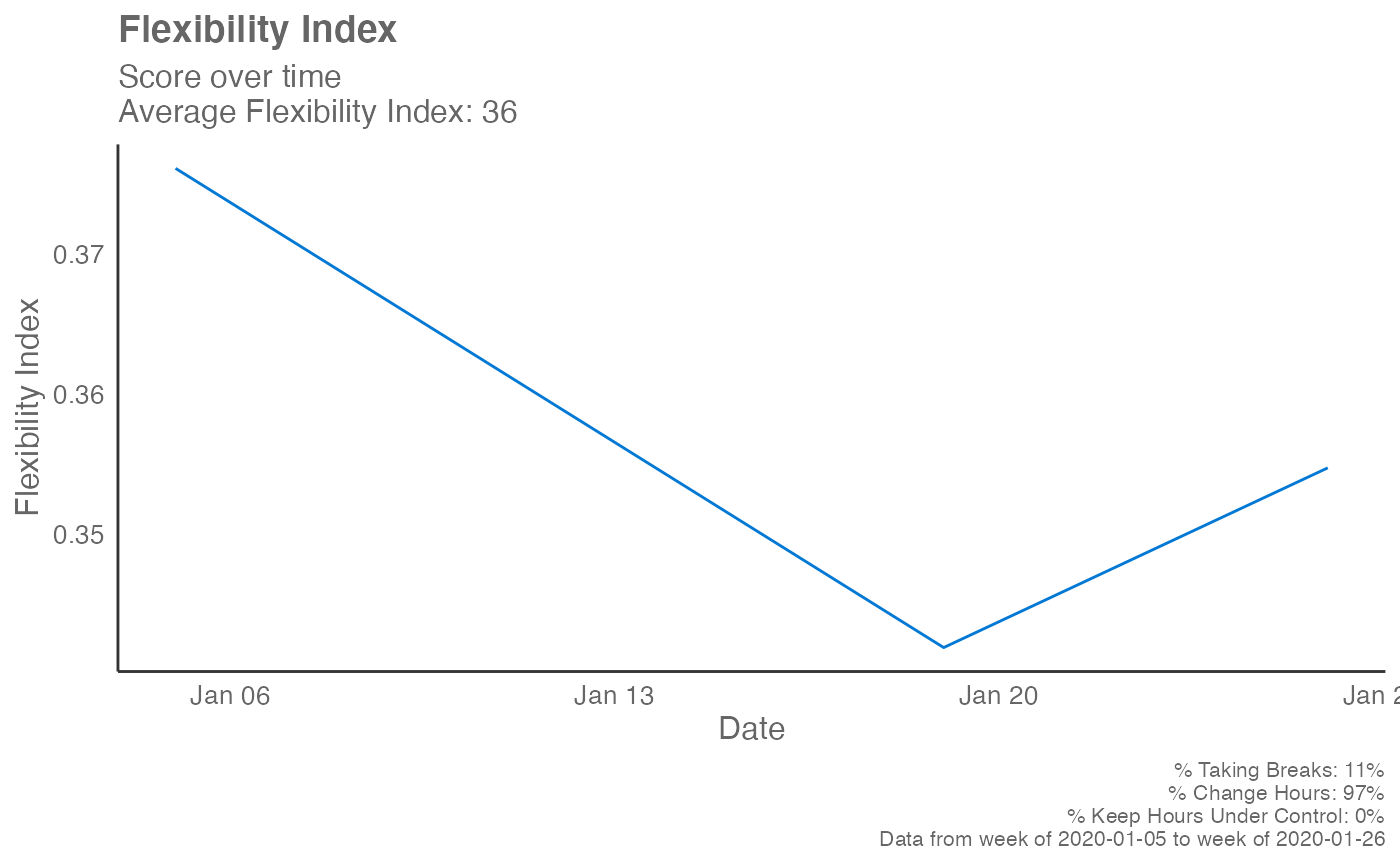 # Return a summary table with the computed Flexibility Index
em_data %>%
flex_index(hrvar = "Organization", return = "table")
#> # A tibble: 3 × 5
#> Organization TakeBreaks ChangeHours ControlHours FlexibilityIndex
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Biz Dev 0.120 1 0 0.373
#> 2 Customer Service 0.115 0.948 0 0.354
#> 3 Financial Planning 0.0833 0.954 0 0.346
# }
# Return a summary table with the computed Flexibility Index
em_data %>%
flex_index(hrvar = "Organization", return = "table")
#> # A tibble: 3 × 5
#> Organization TakeBreaks ChangeHours ControlHours FlexibilityIndex
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Biz Dev 0.120 1 0 0.373
#> 2 Customer Service 0.115 0.948 0 0.354
#> 3 Financial Planning 0.0833 0.954 0 0.346
# }