Create a hierarchical clustering of email or IMs by hour of day
Source:R/workpatterns_hclust.R
workpatterns_hclust.Rd![[Experimental]](figures/lifecycle-experimental.svg)
Apply hierarchical clustering to emails sent by hour of day. The hierarchical clustering uses cosine distance and the ward.D method of agglomeration.
workpatterns_hclust(
data,
k = 4,
return = "plot",
values = "percent",
signals = "email",
start_hour = "0900",
end_hour = "1700"
)Arguments
- data
A data frame containing data from the Hourly Collaboration query.
- k
Numeric vector to specify the
knumber of clusters to cut by.- return
String specifying what to return. This must be one of the following strings:
"plot""data""table""plot-area""hclust""dist"
See
Valuefor more information.- values
Character vector to specify whether to return percentages or absolute values in "data" and "plot". Valid values are:
"percent": percentage of signals divided by total signals (default)
"abs": absolute count of signals
- signals
Character vector to specify which collaboration metrics to use:
"email"(default) for emails only"IM"for Teams messages only"unscheduled_calls"for Unscheduled Calls only"meetings"for Meetings onlyor a combination of signals, such as
c("email", "IM")
- start_hour
A character vector specifying starting hours, e.g. "0900"
- end_hour
A character vector specifying starting hours, e.g. "1700"
Value
A different output is returned depending on the value passed to the return
argument:
"plot": ggplot object of a bar plot (default)"data": data frame containing raw data with the clusters"table": data frame containing a summary table. Percentages of signals are shown, e.g. x% of signals are sent by y hour of the day."plot-area": ggplot object. An overlapping area plot"hclust":hclustobject for the hierarchical model"dist": distance matrix used to build the clustering model
Details
The hierarchical clustering is applied on the person-average volume-based (pav) level. In other words, the clustering is applied on a dataset where the collaboration hours are averaged by person and calculated as % of total daily collaboration.
See also
Other Clustering:
personas_hclust(),
workpatterns_classify()
Other Working Patterns:
flex_index(),
identify_shifts(),
identify_shifts_wp(),
plot_flex_index(),
workpatterns_area(),
workpatterns_classify(),
workpatterns_classify_bw(),
workpatterns_classify_pav(),
workpatterns_rank(),
workpatterns_report()
Examples
# \donttest{
# Run clusters, returning plot
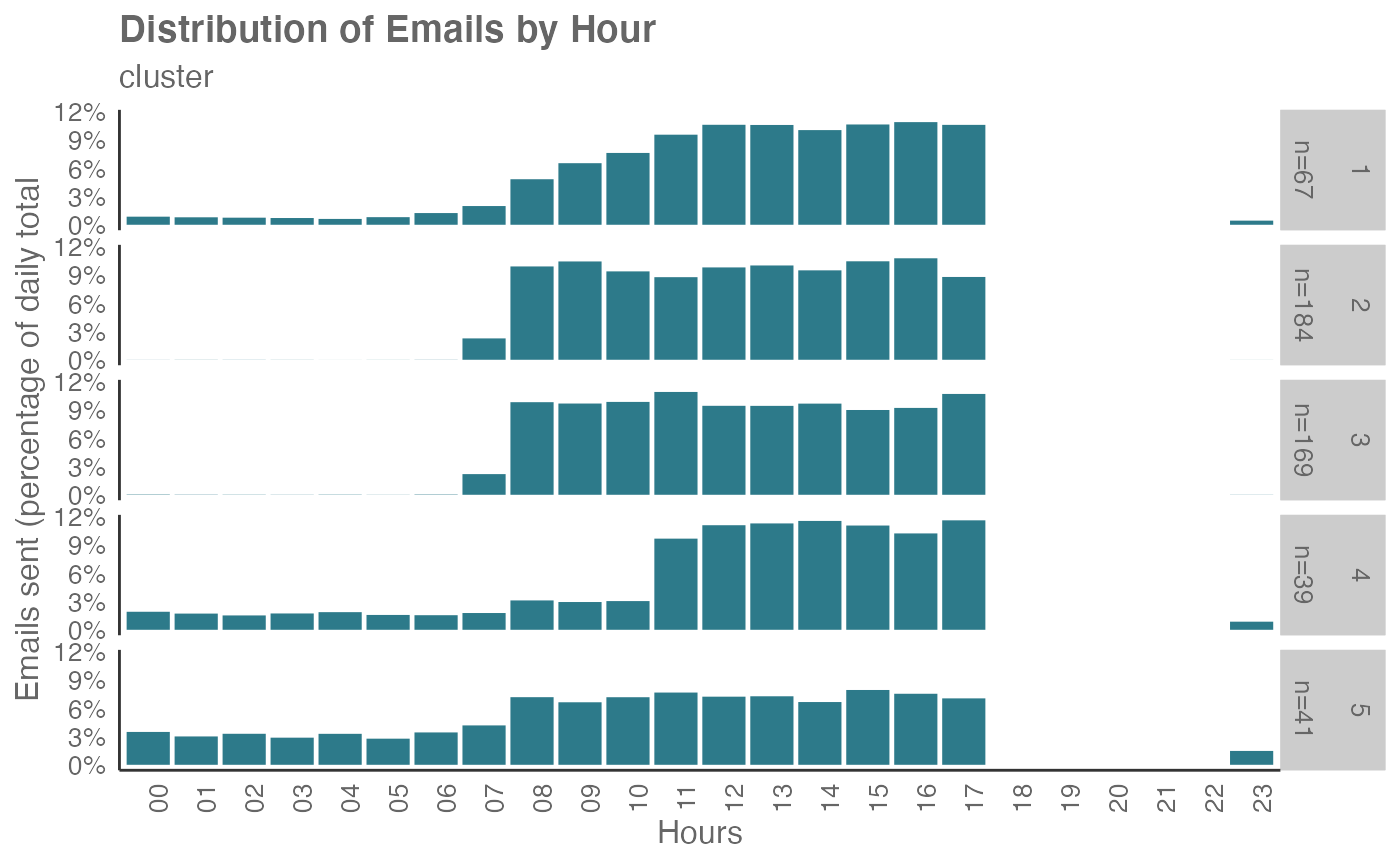
workpatterns_hclust(em_data, k = 5, return = "plot")
 # Run clusters, return raw data
workpatterns_hclust(em_data, k = 4, return = "data") %>% head()
#> PersonId
#> 1 0248F8070D89F3CCDCA7274006516ECC173437A839531652A0BF1F41087A224E
#> 2 024BDDF8FB7C74EBC74C2A97AF92B3285E2DB672A62361E08B6D1892BE9BACCE
#> 3 0250022146CE0A7AC68A3B0C9DFE91E29234ECBB8609F752CC2EE1C3ADBEFF90
#> 4 0358DEF2813F6911B73AEE141837040511768BA66E3B0EA5BF3347C93D319213
#> 5 041A56AAD54F0690E37F0A35AFF71AD59DD46634D15B192EB9BAC36E70132EEC
#> 6 0421E39EEB90A61A3FC504FC8DF33B15A47AD5228713C9AFBA8DB575C654C145
#> Emails_sent_00_01 Emails_sent_01_02 Emails_sent_02_03 Emails_sent_03_04
#> 1 0.007575758 0.003787879 0.011363636 0.01136364
#> 2 0.000000000 0.000000000 0.000000000 0.00000000
#> 3 0.000000000 0.000000000 0.000000000 0.00000000
#> 4 0.000000000 0.000000000 0.000000000 0.00000000
#> 5 0.031620553 0.027667984 0.003952569 0.01976285
#> 6 0.037267081 0.049689441 0.049689441 0.03105590
#> Emails_sent_04_05 Emails_sent_05_06 Emails_sent_06_07 Emails_sent_07_08
#> 1 0.003787879 0.018939394 0.003787879 0.011363636
#> 2 0.000000000 0.000000000 0.000000000 0.034246575
#> 3 0.000000000 0.000000000 0.000000000 0.009803922
#> 4 0.000000000 0.000000000 0.000000000 0.020618557
#> 5 0.015810277 0.007905138 0.015810277 0.023715415
#> 6 0.018633540 0.012422360 0.037267081 0.037267081
#> Emails_sent_08_09 Emails_sent_09_10 Emails_sent_10_11 Emails_sent_11_12
#> 1 0.08333333 0.06060606 0.10227273 0.07954545
#> 2 0.08219178 0.10273973 0.08219178 0.11643836
#> 3 0.11764706 0.08823529 0.09803922 0.10294118
#> 4 0.10309278 0.08247423 0.09793814 0.10824742
#> 5 0.04347826 0.03557312 0.05533597 0.11462451
#> 6 0.08074534 0.05590062 0.09316770 0.11801242
#> Emails_sent_12_13 Emails_sent_13_14 Emails_sent_14_15 Emails_sent_15_16
#> 1 0.10984848 0.09469697 0.09090909 0.11363636
#> 2 0.11643836 0.06164384 0.11643836 0.11643836
#> 3 0.12254902 0.07352941 0.10784314 0.09803922
#> 4 0.11855670 0.08247423 0.04639175 0.12371134
#> 5 0.11067194 0.08695652 0.09090909 0.10671937
#> 6 0.08695652 0.05590062 0.06832298 0.05590062
#> Emails_sent_16_17 Emails_sent_17_18 Emails_sent_18_19 Emails_sent_19_20
#> 1 0.12500000 0.06818182 0 0
#> 2 0.11643836 0.05479452 0 0
#> 3 0.10784314 0.07352941 0 0
#> 4 0.08762887 0.12886598 0 0
#> 5 0.07509881 0.12648221 0 0
#> 6 0.08074534 0.02484472 0 0
#> Emails_sent_20_21 Emails_sent_21_22 Emails_sent_22_23 Emails_sent_23_24
#> 1 0 0 0 0.000000000
#> 2 0 0 0 0.000000000
#> 3 0 0 0 0.000000000
#> 4 0 0 0 0.000000000
#> 5 0 0 0 0.007905138
#> 6 0 0 0 0.006211180
#> cluster
#> 1 1
#> 2 2
#> 3 2
#> 4 3
#> 5 1
#> 6 4
# Run clusters for instant messages only, return hclust object
workpatterns_hclust(em_data, k = 4, return = "hclust", signals = c("IM"))
#>
#> Call:
#> stats::hclust(d = ., method = "ward.D")
#>
#> Cluster method : ward.D
#> Distance : cosine
#> Number of objects: 500
#>
# }
# Run clusters, return raw data
workpatterns_hclust(em_data, k = 4, return = "data") %>% head()
#> PersonId
#> 1 0248F8070D89F3CCDCA7274006516ECC173437A839531652A0BF1F41087A224E
#> 2 024BDDF8FB7C74EBC74C2A97AF92B3285E2DB672A62361E08B6D1892BE9BACCE
#> 3 0250022146CE0A7AC68A3B0C9DFE91E29234ECBB8609F752CC2EE1C3ADBEFF90
#> 4 0358DEF2813F6911B73AEE141837040511768BA66E3B0EA5BF3347C93D319213
#> 5 041A56AAD54F0690E37F0A35AFF71AD59DD46634D15B192EB9BAC36E70132EEC
#> 6 0421E39EEB90A61A3FC504FC8DF33B15A47AD5228713C9AFBA8DB575C654C145
#> Emails_sent_00_01 Emails_sent_01_02 Emails_sent_02_03 Emails_sent_03_04
#> 1 0.007575758 0.003787879 0.011363636 0.01136364
#> 2 0.000000000 0.000000000 0.000000000 0.00000000
#> 3 0.000000000 0.000000000 0.000000000 0.00000000
#> 4 0.000000000 0.000000000 0.000000000 0.00000000
#> 5 0.031620553 0.027667984 0.003952569 0.01976285
#> 6 0.037267081 0.049689441 0.049689441 0.03105590
#> Emails_sent_04_05 Emails_sent_05_06 Emails_sent_06_07 Emails_sent_07_08
#> 1 0.003787879 0.018939394 0.003787879 0.011363636
#> 2 0.000000000 0.000000000 0.000000000 0.034246575
#> 3 0.000000000 0.000000000 0.000000000 0.009803922
#> 4 0.000000000 0.000000000 0.000000000 0.020618557
#> 5 0.015810277 0.007905138 0.015810277 0.023715415
#> 6 0.018633540 0.012422360 0.037267081 0.037267081
#> Emails_sent_08_09 Emails_sent_09_10 Emails_sent_10_11 Emails_sent_11_12
#> 1 0.08333333 0.06060606 0.10227273 0.07954545
#> 2 0.08219178 0.10273973 0.08219178 0.11643836
#> 3 0.11764706 0.08823529 0.09803922 0.10294118
#> 4 0.10309278 0.08247423 0.09793814 0.10824742
#> 5 0.04347826 0.03557312 0.05533597 0.11462451
#> 6 0.08074534 0.05590062 0.09316770 0.11801242
#> Emails_sent_12_13 Emails_sent_13_14 Emails_sent_14_15 Emails_sent_15_16
#> 1 0.10984848 0.09469697 0.09090909 0.11363636
#> 2 0.11643836 0.06164384 0.11643836 0.11643836
#> 3 0.12254902 0.07352941 0.10784314 0.09803922
#> 4 0.11855670 0.08247423 0.04639175 0.12371134
#> 5 0.11067194 0.08695652 0.09090909 0.10671937
#> 6 0.08695652 0.05590062 0.06832298 0.05590062
#> Emails_sent_16_17 Emails_sent_17_18 Emails_sent_18_19 Emails_sent_19_20
#> 1 0.12500000 0.06818182 0 0
#> 2 0.11643836 0.05479452 0 0
#> 3 0.10784314 0.07352941 0 0
#> 4 0.08762887 0.12886598 0 0
#> 5 0.07509881 0.12648221 0 0
#> 6 0.08074534 0.02484472 0 0
#> Emails_sent_20_21 Emails_sent_21_22 Emails_sent_22_23 Emails_sent_23_24
#> 1 0 0 0 0.000000000
#> 2 0 0 0 0.000000000
#> 3 0 0 0 0.000000000
#> 4 0 0 0 0.000000000
#> 5 0 0 0 0.007905138
#> 6 0 0 0 0.006211180
#> cluster
#> 1 1
#> 2 2
#> 3 2
#> 4 3
#> 5 1
#> 6 4
# Run clusters for instant messages only, return hclust object
workpatterns_hclust(em_data, k = 4, return = "hclust", signals = c("IM"))
#>
#> Call:
#> stats::hclust(d = ., method = "ward.D")
#>
#> Cluster method : ward.D
#> Distance : cosine
#> Number of objects: 500
#>
# }