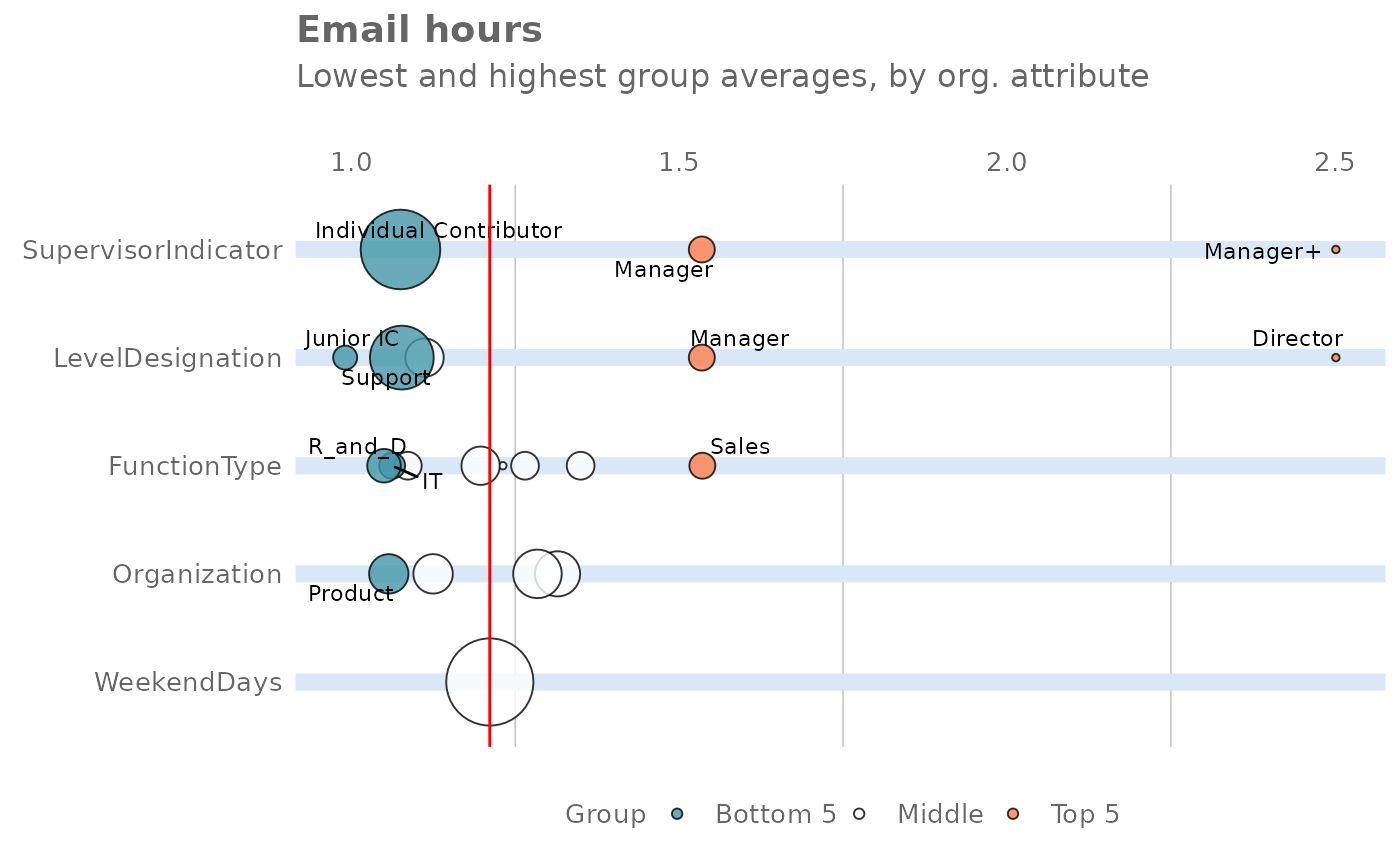
This function scans a standard query output for groups with high levels of 'Weekly Email Collaboration'. Returns a plot by default, with an option to return a table with a all of groups (across multiple HR attributes) ranked by hours of digital collaboration.
Usage
email_rank(
data,
hrvar = extract_hr(data),
mingroup = 5,
mode = "simple",
plot_mode = 1,
return = "plot"
)Arguments
- data
A Standard Person Query dataset in the form of a data frame. This must be a panel dataset where each row represents one employee per time period, with the columns
PersonIdandMetricDatepresent. If your data is already aggregated (e.g. one row per group), use the equivalent*_asis()variant of this function instead.- hrvar
String containing the name of the HR Variable by which to split metrics. Defaults to
"Organization". To run the analysis on the total instead of splitting by an HR attribute, supplyNULL(without quotes).- mingroup
Numeric value setting the privacy threshold / minimum group size. Defaults to 5.
- mode
String to specify calculation mode. Must be either:
"simple""combine"
- plot_mode
Numeric vector to determine which plot mode to return. Must be either
1or2, and is only used whenreturn = "plot".1: Top and bottom five groups across the data population are highlighted2: Top and bottom groups per organizational attribute are highlighted
- return
String specifying what to return. This must be one of the following strings:
"plot"(default)"table"
See
Valuefor more information.
Value
A different output is returned depending on the value passed to the return
argument:
"plot": 'ggplot' object. A bubble plot where the x-axis represents the metric, the y-axis represents the HR attributes, and the size of the bubbles represent the size of the organizations. Note that there is no plot output ifmodeis set to"combine"."table": data frame. A summary table for the metric.
Details
Uses the metric Email_hours.
See create_rank() for applying the same analysis to a different metric.
See also
Other Visualization:
afterhours_dist(),
afterhours_fizz(),
afterhours_line(),
afterhours_rank(),
afterhours_summary(),
afterhours_trend(),
collaboration_area(),
collaboration_dist(),
collaboration_fizz(),
collaboration_line(),
collaboration_rank(),
collaboration_sum(),
collaboration_trend(),
create_bar(),
create_bar_asis(),
create_boxplot(),
create_bubble(),
create_dist(),
create_fizz(),
create_inc(),
create_line(),
create_line_asis(),
create_period_scatter(),
create_radar(),
create_rank(),
create_rogers(),
create_sankey(),
create_scatter(),
create_stacked(),
create_survival(),
create_tracking(),
create_trend(),
email_dist(),
email_fizz(),
email_line(),
email_summary(),
email_trend(),
external_dist(),
external_fizz(),
external_line(),
external_rank(),
external_sum(),
hr_trend(),
hrvar_count(),
hrvar_trend(),
keymetrics_scan(),
meeting_dist(),
meeting_fizz(),
meeting_line(),
meeting_rank(),
meeting_summary(),
meeting_trend(),
one2one_dist(),
one2one_fizz(),
one2one_freq(),
one2one_line(),
one2one_rank(),
one2one_sum(),
one2one_trend()
Other Emails:
email_dist(),
email_fizz(),
email_line(),
email_summary(),
email_trend()
Examples
# Return rank table
email_rank(
data = pq_data,
return = "table"
)
#> 1 column(s) excluded due to max_unique = 50: PersonId (300).
#> Adjust the `max_unique` argument if you wish to include these columns.
#> # A tibble: 22 × 4
#> hrvar group Email_hours n
#> <chr> <chr> <dbl> <int>
#> 1 Organization Operations 8.92 22
#> 2 Organization Research 8.89 52
#> 3 FunctionType Technician 8.88 274
#> 4 Level Level1 8.83 37
#> 5 LevelDesignation Executive 8.83 37
#> 6 Level Level3 8.82 87
#> 7 LevelDesignation Senior IC 8.82 87
#> 8 FunctionType Consultant 8.81 288
#> 9 Organization HR 8.80 33
#> 10 Organization Finance 8.79 68
#> # ℹ 12 more rows
# Return plot
email_rank(
data = pq_data,
return = "plot"
)
#> 1 column(s) excluded due to max_unique = 50: PersonId (300).
#> Adjust the `max_unique` argument if you wish to include these columns.