Provides an analysis of the distribution of a selected metric. Returns a stacked bar plot by default. Additional options available to return a table with distribution elements.
Arguments
- data
A Standard Person Query dataset in the form of a data frame. This must be a panel dataset where each row represents one employee per time period, with the columns
PersonIdandMetricDatepresent. If your data is already aggregated (e.g. one row per group), use the equivalent*_asis()variant of this function instead.- metric
String containing the name of the metric, e.g. "Collaboration_hours"
- hrvar
String containing the name of the HR Variable by which to split metrics. Defaults to
"Organization". To run the analysis on the total instead of splitting by an HR attribute, supplyNULL(without quotes).- mingroup
Numeric value setting the privacy threshold / minimum group size. Defaults to 5.
- return
String specifying what to return. This must be one of the following strings:
"plot""table"
See
Valuefor more information.- cut
A numeric vector of length three to specify the breaks for the distribution, e.g. c(10, 15, 20)
- dist_colours
A character vector of length four to specify colour codes for the stacked bars.
- unit
String to specify what unit to use. This defaults to
"hours"but can accept any custom string. Seecut_hour()for more details.- lbound
Numeric. Specifies the lower bound (inclusive) value for the minimum label. Defaults to 0.
- ubound
Numeric. Specifies the upper bound (inclusive) value for the maximum label. Defaults to 100.
- sort_by
String to specify the bucket label to sort by. Defaults to
NULL(no sorting).- labels
Character vector to override labels for the created categorical variables. Must be a named vector - see examples.
Value
A different output is returned depending on the value passed to the return argument:
"plot": 'ggplot' object. A stacked bar plot for the metric."table": data frame. A summary table for the metric.
See also
Other Visualization:
afterhours_dist(),
afterhours_fizz(),
afterhours_line(),
afterhours_rank(),
afterhours_summary(),
afterhours_trend(),
collaboration_area(),
collaboration_dist(),
collaboration_fizz(),
collaboration_line(),
collaboration_rank(),
collaboration_sum(),
collaboration_trend(),
create_bar(),
create_bar_asis(),
create_boxplot(),
create_bubble(),
create_fizz(),
create_inc(),
create_line(),
create_line_asis(),
create_period_scatter(),
create_radar(),
create_rank(),
create_rogers(),
create_sankey(),
create_scatter(),
create_stacked(),
create_survival(),
create_tracking(),
create_trend(),
email_dist(),
email_fizz(),
email_line(),
email_rank(),
email_summary(),
email_trend(),
external_dist(),
external_fizz(),
external_line(),
external_rank(),
external_sum(),
hr_trend(),
hrvar_count(),
hrvar_trend(),
keymetrics_scan(),
meeting_dist(),
meeting_fizz(),
meeting_line(),
meeting_rank(),
meeting_summary(),
meeting_trend(),
one2one_dist(),
one2one_fizz(),
one2one_freq(),
one2one_line(),
one2one_rank(),
one2one_sum(),
one2one_trend()
Other Flexible:
create_bar(),
create_bar_asis(),
create_boxplot(),
create_bubble(),
create_density(),
create_fizz(),
create_hist(),
create_inc(),
create_line(),
create_line_asis(),
create_period_scatter(),
create_radar(),
create_rank(),
create_sankey(),
create_scatter(),
create_stacked(),
create_survival(),
create_tracking(),
create_trend()
Examples
# Return plot
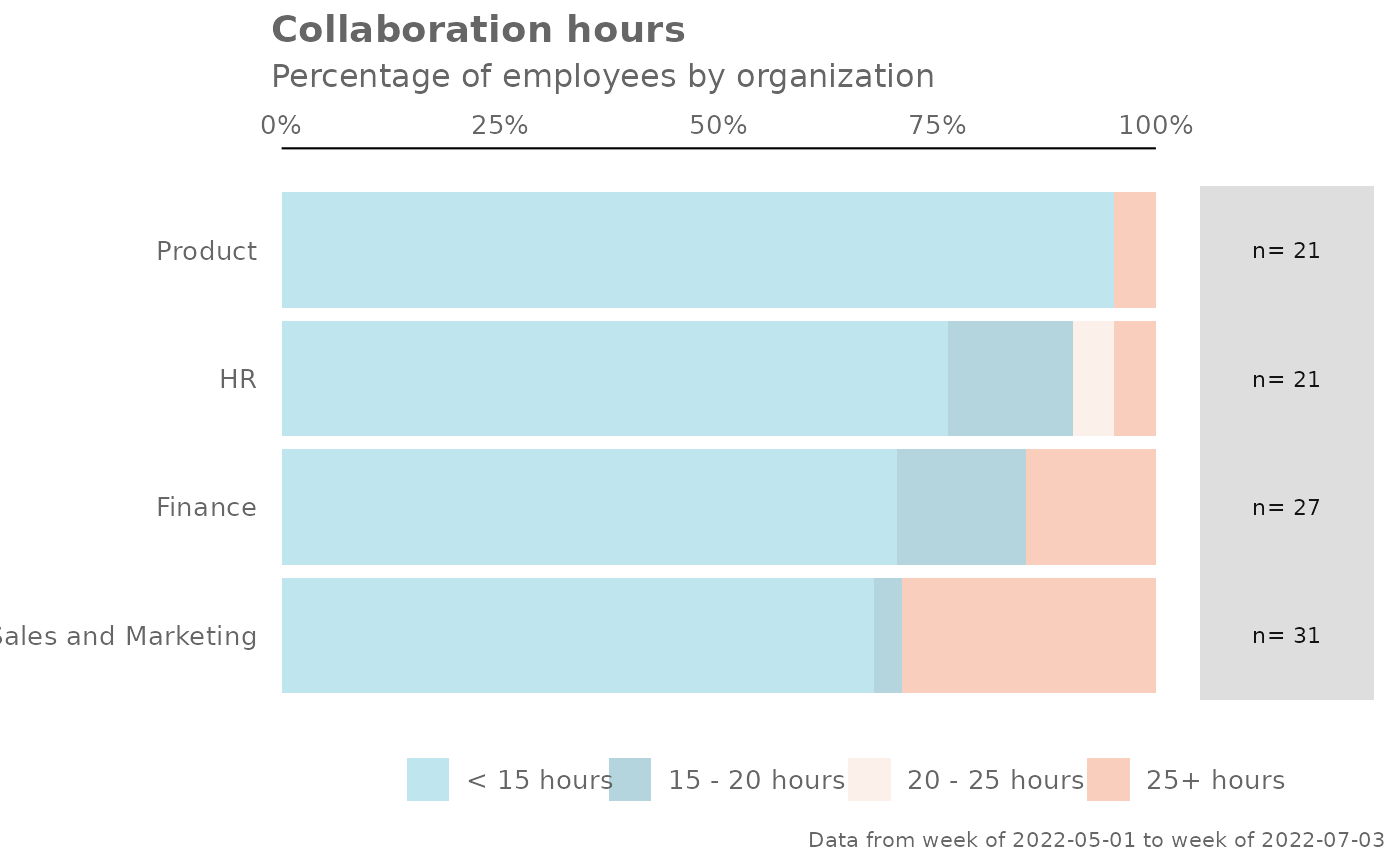
create_dist(pq_data, metric = "Collaboration_hours", hrvar = "Organization")
 # Return summary table
create_dist(pq_data, metric = "Collaboration_hours", hrvar = "Organization", return = "table")
#> # A tibble: 7 × 5
#> group `15 - 20 hours` `20 - 25 hours` `25+ hours` Employee_Count
#> <fct> <dbl> <dbl> <dbl> <int>
#> 1 Finance NA 0.897 0.103 68
#> 2 HR NA 1 NA 33
#> 3 IT NA 0.941 0.0588 68
#> 4 Legal 0.0227 0.977 NA 44
#> 5 Operations 0.0455 0.727 0.227 22
#> 6 Research NA 0.904 0.0962 52
#> 7 Sales NA 1 NA 13
# Use custom labels by providing a label vector
eh_labels <- c(
"Fewer than fifteen" = "< 15 hours",
"Between fifteen and twenty" = "15 - 20 hours",
"Between twenty and twenty-five" = "20 - 25 hours",
"More than twenty-five" = "25+ hours"
)
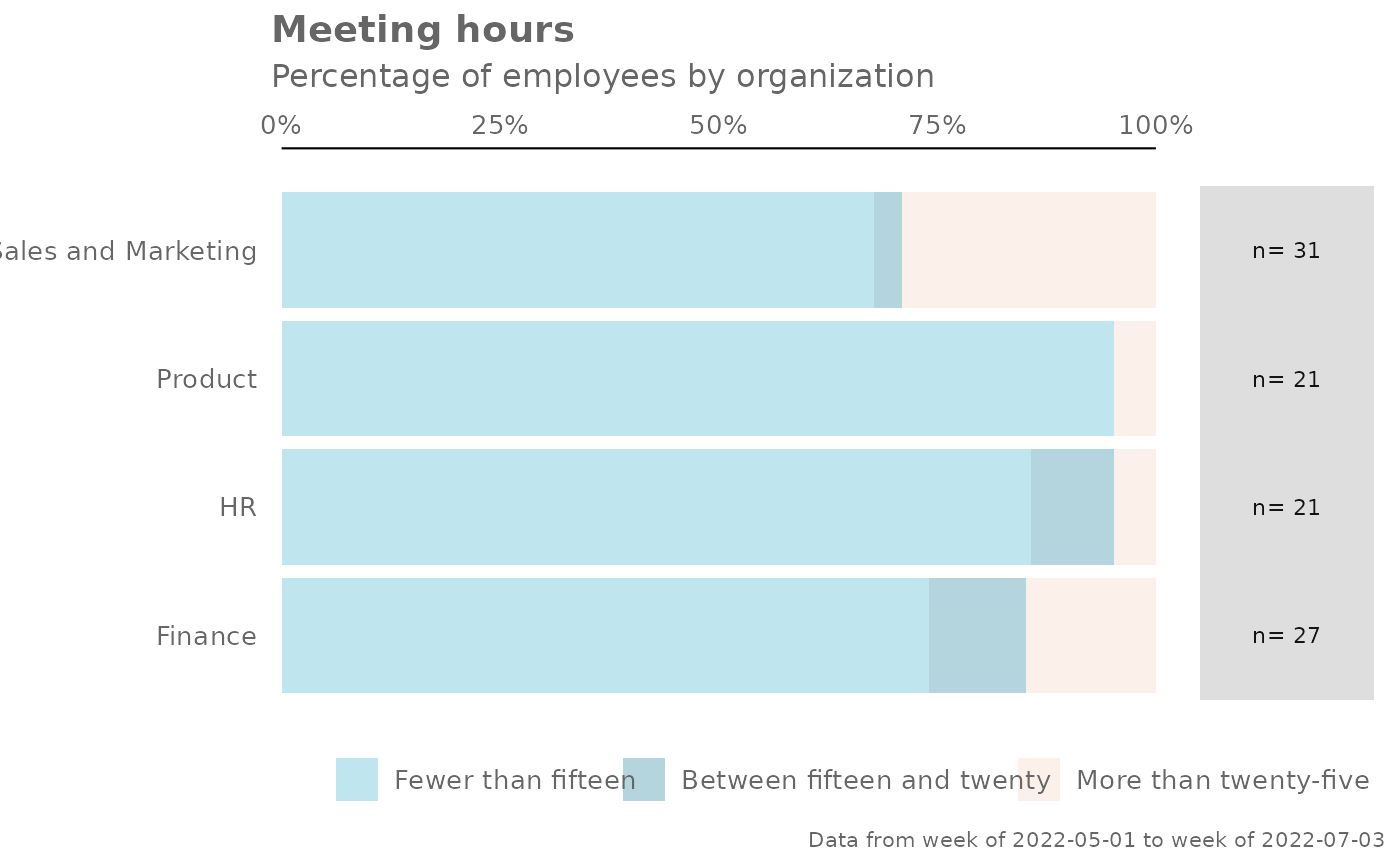
pq_data %>% create_dist(metric = "Meeting_hours", labels = eh_labels, return = "plot")
# Return summary table
create_dist(pq_data, metric = "Collaboration_hours", hrvar = "Organization", return = "table")
#> # A tibble: 7 × 5
#> group `15 - 20 hours` `20 - 25 hours` `25+ hours` Employee_Count
#> <fct> <dbl> <dbl> <dbl> <int>
#> 1 Finance NA 0.897 0.103 68
#> 2 HR NA 1 NA 33
#> 3 IT NA 0.941 0.0588 68
#> 4 Legal 0.0227 0.977 NA 44
#> 5 Operations 0.0455 0.727 0.227 22
#> 6 Research NA 0.904 0.0962 52
#> 7 Sales NA 1 NA 13
# Use custom labels by providing a label vector
eh_labels <- c(
"Fewer than fifteen" = "< 15 hours",
"Between fifteen and twenty" = "15 - 20 hours",
"Between twenty and twenty-five" = "20 - 25 hours",
"More than twenty-five" = "25+ hours"
)
pq_data %>% create_dist(metric = "Meeting_hours", labels = eh_labels, return = "plot")
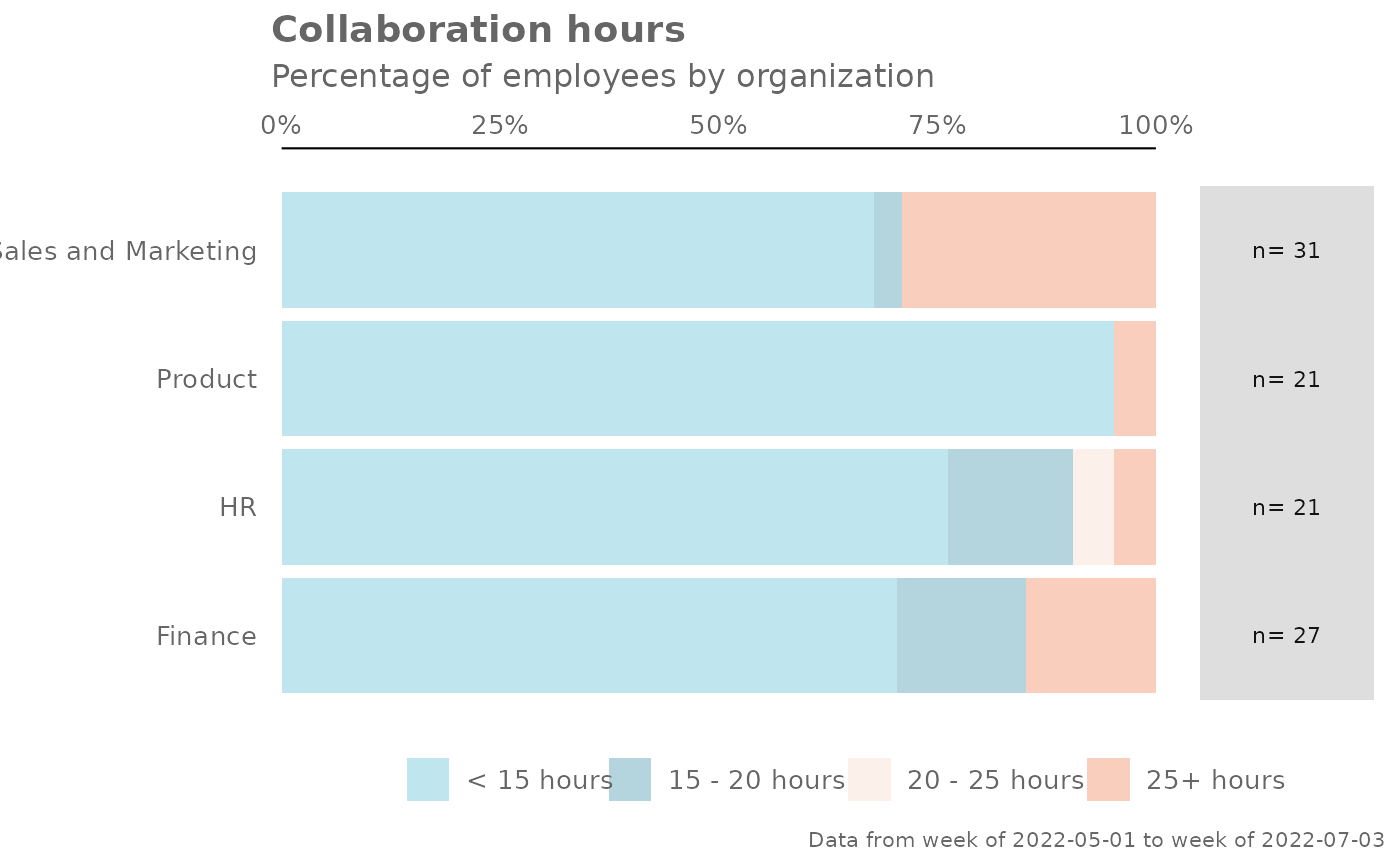
 # Sort by a category
pq_data %>% create_dist(metric = "Collaboration_hours", sort_by = "25+ hours")
# Sort by a category
pq_data %>% create_dist(metric = "Collaboration_hours", sort_by = "25+ hours")