실습 ③: 흐름 + Office Script + AI 프롬프트 — 그리고 함정
| 시간 | 소요 | 수강생 역할 |
|---|---|---|
| 10:48 | 10분 | 🟠 데모 + 따라보기 (시간 부족 시 데모 위주) |
실습 ① 에서 본 것처럼 — Excel Table만 잘 정의돼 있으면 흐름 없이도 충분하고, 실습 ② 처럼 코드 없이 커넥터+OData 필터만으로도 상당히 멀리 갈 수 있습니다. 그럼에도 Office Script까지 가는 이유는 그 자체가 만능이라서가 아니라, 커넥터의 한계(5,000행, 단순 필터)를 넘는 시나리오를 우회하기 위해서 입니다.
목차
- 1. Office Script까지 가야 할 때 — 솔직한 실익 검토
- 2. 이 실습이 만드는 것 — 4단 콤보
- Part A. 흐름 만들기 (Step 1~12)
- Step 1. 샘플 Excel 준비
- Step 2. 에이전트 흐름(Power Automate) 만들기
- Step 3. OneDrive에 임시 저장
- Step 4. 여기까지 테스트
- Step 5. Office Script 작성 (시트 → JSON)
- Step 6. 흐름에 “스크립트 실행” 노드 추가
- Step 7. AI 프롬프트 실행 노드 추가
- Step 8. 사용자 지정 프롬프트 작성 ⭐ (함정 회피 포인트)
- Step 9. 프롬프트 단독 테스트
- Step 10. 흐름으로 돌아와 입력 파라미터 매핑
- Step 11. 흐름의 응답 노드
- Step 12. 흐름 전체 테스트
- Part B. 토픽에 흐름 연결 (Step 13~17)
- 3. 같은 질문, 세 가지 길 — 실습 ① vs ② vs ③
- 4. 손에 쥔 4단 콤보 — 응용 포인트
1. Office Script까지 가야 할 때 — 솔직한 실익 검토
✅ Office Script가 진짜 필요한 경우
| 시나리오 | 왜 실습 ②(커넥터)로는 부족한가 |
|---|---|
| 매우 큰 엑셀 (수천~수만 행) | 커넥터 상한 5,000행 초과 — 스크립트로 사전 집계 |
| 컬럼 변환·피벗·복잡 그룹화 | OData 필터는 단순 비교만 가능 |
| 반복적·결정적 리포트 | 매월 같은 구조의 출력 — 스크립트가 결정성 보장 |
| 사전 데이터 가공 | 빈 칸·이상치 정리, 타입 변환 |
❌ Office Script가 오히려 손해인 경우
| 시나리오 | 왜 |
|---|---|
| 일회성 자연어 분석 | 실습 ①이 더 빠르고 답변 품질도 충분함 |
| 단순 필터링이면 충분 | 실습 ②(커넥터+OData) 가 더 가볍고 유지보수 쉬움 |
| 자유로운 후속 질문이 필요 | 흐름은 1회성 응답에 가까움 — 후속 질의가 어색해짐 |
⚠️ 함정 — AI 프롬프트의 코드 인터프리터
흐름의 마지막 단계인 AI 프롬프트는 코드 인터프리터를 켜면 수치 계산을 정확히 할 수 있습니다. 하지만 실전에는 다음과 같은 함정이 있습니다.
- 데이터를 그냥 던지고 “알아서 분석해” 라고 하면, 코드 인터프리터가 컬럼 구조를 잘못 추측해 오류가 자주 발생합니다.
- 프롬프트에 “컬럼이 무엇이고 어떤 타입인지” 를 자세히 설명해 줘야 안정적으로 동작합니다.
- 모델·요청 형태에 따라 코드 인터프리터를 끄는 게 오히려 답변이 깔끔 한 경우도 적지 않습니다.
요컨대 Office Script 길은 — 실습 ① 만큼 단순하지 않으며, 실익이 명확한 시나리오를 정해서 적용해야 합니다.
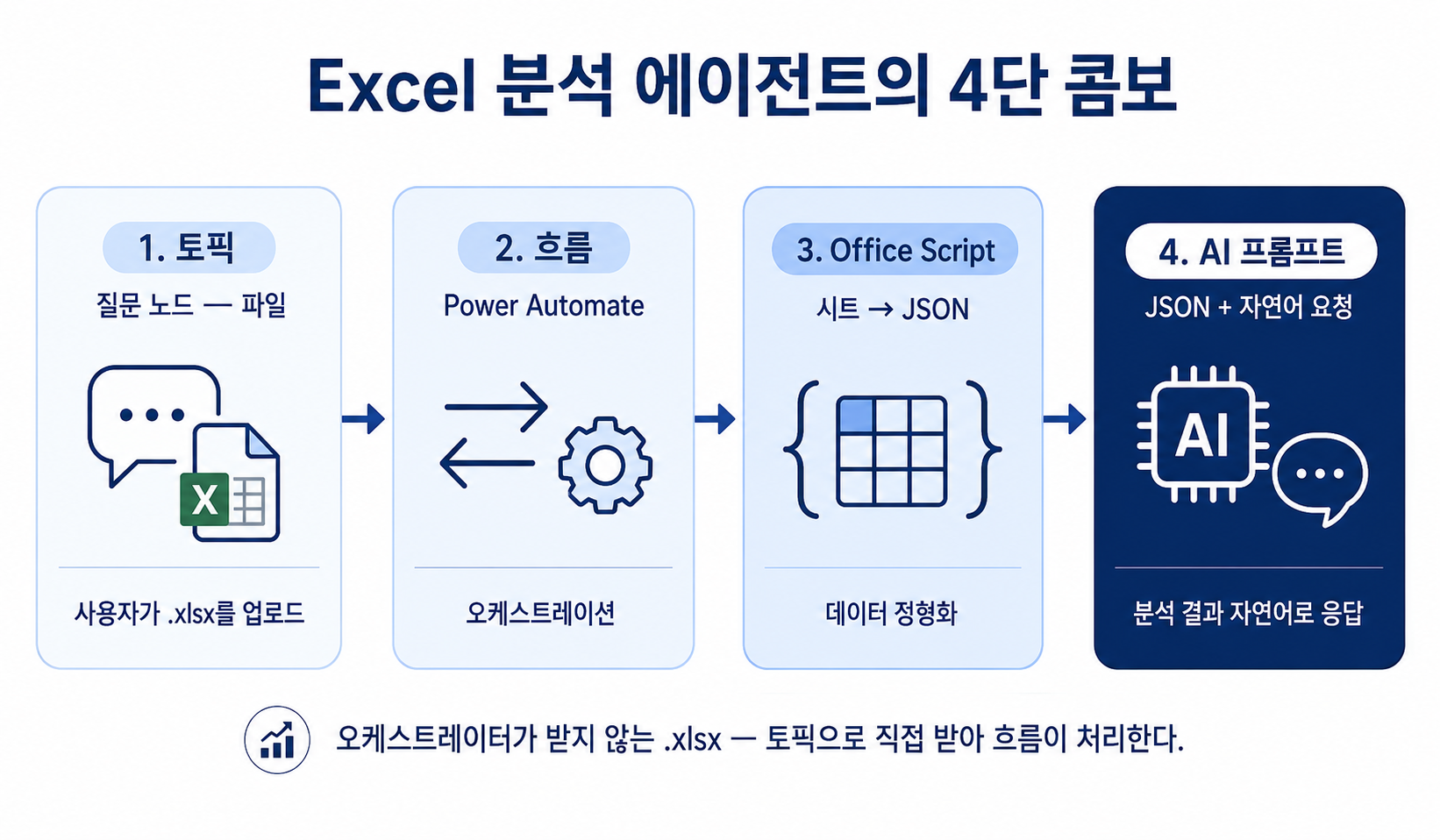
2. 이 실습이 만드는 것 — 4단 콤보
실습 ②(커넥터) 와 동일한 토픽 구조로 받되, 흐름의 데이터 처리 단계를 Office Script 로 교체합니다. 비교 학습을 위해 별개 토픽으로 만듭니다.
[사용자] → 토픽 (실습 ③ 전용)
├ 질문 노드 ① — 요청문
├ 질문 노드 ② — 파일
↓ 흐름 호출 (요청문 + 파일 record)
[Power Automate 흐름]
├ ① OneDrive 임시 저장
├ ② Office Script: 시트 → JSON
├ ③ AI 프롬프트: JSON + 요청문 → 분석 텍스트
↓
[토픽 메시지 노드] → [사용자]
시간이 부족한 경우: 강사 데모만 보고 코드는 본 가이드를 참고해 사후 따라해도 무방합니다.
Part A. 흐름 만들기 (Step 1~12)
Step 1. 샘플 Excel 준비
- 과일판매_Table.xlsx 를 OneDrive 작업 폴더로 업로드
- 첫 번째 시트 이름은 그대로 두기 (
Sheet1) - 컬럼:
연도,분기,과일,판매량(헤더는 1행)
Step 2. 에이전트 흐름(Power Automate) 만들기
- make.powerautomate.com 접속
- 만들기 → 인스턴트 클라우드 흐름
- 트리거: Copilot Studio (V2) → “Copilot에서 흐름을 호출할 때”
- 흐름 이름:
엑셀분석_스크립트_흐름 - 트리거 입력 추가:
요청문(텍스트)파일(파일) — 콘텐츠와 파일명을 모두 받도록 파일 형식 선택
포인트: 입력 파라미터의 이름과 타입은 토픽에서 호출할 때 동일하게 매핑되어야 합니다.
Step 3. OneDrive에 임시 저장
- 새 작업: OneDrive for Business → 파일 만들기
- 폴더 경로:
/Apps/엑셀분석_임시/ - 파일 이름:
temp_@{utcNow('yyyyMMddHHmmss')}.xlsx - 파일 콘텐츠: 트리거 입력의 파일 콘텐츠
포인트: 임시 폴더는 OneDrive에 미리 만들어두면 깔끔합니다.
Step 4. 여기까지 테스트
- 흐름 저장 → 테스트 → “수동으로”
- 입력: 요청문
"test", 파일과일판매_Table.xlsx - OneDrive
/Apps/엑셀분석_임시/에 파일 생성 확인
체크포인트: 실패 시 OneDrive 권한 또는 트리거 입력 매핑을 다시 확인.
Step 5. Office Script 작성 (시트 → JSON)
- OneDrive에서
과일판매_Table.xlsx열기 (Excel for the web) - 리본 메뉴: 자동화 → 새 스크립트
- Excel Copilot 사용 권장: 우측 Copilot 창에 다음 프롬프트
“이 통합 문서의 첫 번째 시트에 있는 모든 데이터를 헤더 포함한 객체 배열 JSON 문자열로 반환하는 Office Script를 만들어줘. main 함수의 반환 타입은 string이어야 해.”
- 생성된 코드 검토 후 저장
- 스크립트 이름:
시트_to_JSON
샘플 코드:
function main(workbook: ExcelScript.Workbook): string {
const sheet = workbook.getFirstWorksheet();
const range = sheet.getUsedRange();
if (!range) return "[]";
const values = range.getValues();
if (values.length < 2) return "[]";
const headers = values[0].map(String);
const rows = values.slice(1).map(row => {
const obj: { [key: string]: string | number | boolean } = {};
headers.forEach((h, i) => obj[h] = row[i]);
return obj;
});
return JSON.stringify(rows);
}
포인트: 반환 타입을
string(JSON 문자열) 으로 잡으면 다음 단계 AI 프롬프트가 받기에 가장 편합니다.
Step 6. 흐름에 “스크립트 실행” 노드 추가
- Power Automate 흐름으로 돌아옴
- 새 작업: Excel Online (Business) → 스크립트 실행
- 매개변수:
- 위치:
OneDrive for Business - 문서 라이브러리:
OneDrive - 파일: 동적 콘텐츠에서 Step 3에서 만든 파일의 ID
- 스크립트:
시트_to_JSON
- 위치:
Step 7. AI 프롬프트 실행 노드 추가
- 새 작업: AI Builder → 프롬프트로 텍스트 만들기 (Create text with GPT using a prompt)
- 새 프롬프트 만들기 클릭
Step 8. 사용자 지정 프롬프트 작성 ⭐ (함정 회피 포인트)
새 창에서 프롬프트 디자이너가 열립니다.
프롬프트 이름: 엑셀_분석_프롬프트_스크립트
프롬프트 본문:
당신은 Excel 데이터 분석가입니다. 아래 [데이터]는 Excel 시트의 행을
JSON 배열로 변환한 것입니다. [요청문]에 따라 데이터를 분석하고,
한국어로 친절하게 답변하세요.
[데이터 스키마] ← ⚠️ 이 절을 생략하면 코드 인터프리터가 자주 실패합니다
- 연도 (number): 2006 ~ 2025
- 분기 (string): "Q1" | "Q2" | "Q3" | "Q4"
- 과일 (string): "사과" | "배" | "감"
- 판매량 (number): 정수
[규칙]
- 숫자는 천 단위 콤마로 표기합니다.
- 평균/합계 등 계산이 필요하면 정확히 계산합니다.
- 데이터에 없는 값은 추측하지 말고 "데이터에 없습니다"라고 답하세요.
- 답변은 결론 한 줄 + 근거 표(또는 목록)로 구성하세요.
[요청문]
[데이터]
입력 변수 추가:
요청문(텍스트)데이터JSON(텍스트)
모델 설정:
- 모델: GPT-5 (또는 사용 가능한 최신 모델)
- 코드 인터프리터: 🟡 상황에 따라 선택
- 켜기: 평균·합계·그룹화 등 결정적 수치 계산이 정말 필요할 때
- 끄기: 모델이 충분히 강하고 데이터가 작아 LLM이 직접 풀어내는 게 더 깔끔한 경우 — 실제 테스트해보고 더 좋은 쪽으로
테스트:
- 요청문: “사과의 연도별 평균 판매량은?”
- 데이터JSON: Step 5에서 한 번 실행해본 JSON 결과를 그대로 붙여넣기
테스트 결과가 그럴듯하면 프롬프트 저장.
💡 함정 회피 1: 데이터 스키마를 안 적으면 코드 인터프리터가 컬럼 타입을 잘못 추측하기 쉽습니다. 위 [데이터 스키마] 절이 핵심.
💡 함정 회피 2: 같은 데이터·같은 질문에 대해 코드 인터프리터 ON / OFF 양쪽을 한 번씩 테스트해보고 더 안정적인 쪽을 채택. “켜기 = 항상 더 정확”이 아닙니다.
Step 9. 프롬프트 단독 테스트
프롬프트 디자이너의 테스트 모드에서 다양한 요청문으로 점검:
- “사과의 연도별 평균 판매량은?”
- “가장 많이 팔린 과일 Top 3는?”
- “2024년 전체 판매량 합계는?”
Step 10. 흐름으로 돌아와 입력 파라미터 매핑
- AI 프롬프트 노드에 두 입력이 보임
요청문→ 트리거의요청문동적 콘텐츠 매핑데이터JSON→ Step 6 “스크립트 실행”의 결과(result) 동적 콘텐츠 매핑
Step 11. 흐름의 응답 노드
- 마지막 작업: Copilot Studio에 응답 (Respond to Copilot)
- 출력 추가:
- 이름:
결과텍스트(텍스트) - 값: AI 프롬프트 노드의 응답 텍스트 동적 콘텐츠
- 이름:
Step 12. 흐름 전체 테스트
- 저장 후 테스트 → 수동으로
- 요청문: “사과의 연도별 평균 판매량은?”
- 파일:
과일판매_Table.xlsx - 결과 텍스트가 자연어 분석 결과로 나오는지 확인
체크포인트: 여기까지 성공하면 백엔드(흐름)는 완성. 이제 토픽에서 호출합니다.
Part B. 토픽에 흐름 연결 (Step 13~17)
실습 ①·② 와 충돌하지 않게 별개의 새 토픽 으로 만듭니다. 같은 에이전트 안에서 세 실습의 결과를 나란히 비교할 수 있게 두는 것이 학습 효과가 큽니다.
Step 13. 새 토픽 만들기 + 질문 노드 ① (요청문)
- Copilot Studio → 실습 ①의 에이전트 열기 → 토픽 → 새 토픽 (빈 토픽)
- 토픽 이름:
엑셀 분석 (스크립트) - 트리거 구문:
엑셀 분석 스크립트오피스 스크립트로 엑셀 분석
- 첫 노드: 질문 (Question)
- 메시지: “어떤 분석을 원하시나요? (예: 사과의 연도별 평균은?)”
- 식별: 사용자의 전체 응답 (텍스트)
- 변수 이름:
Topic.요청문
Step 14. 질문 노드 ② (파일)
다음 노드로 또 하나의 질문 노드 추가:
- 메시지: “분석할 Excel 파일을 첨부해주세요.”
- 식별: 파일 (File)
- 변수 이름:
Topic.첨부파일 - 속성 → 고급 → 파일 메타데이터 활성화 ← 체크
Step 15. 흐름 호출 노드 추가 (record 타입 변환 ⭐)
- 새 노드 추가 → 작업(Action) → 흐름 →
엑셀분석_스크립트_흐름선택 - 입력 파라미터 매핑:
요청문→Topic.요청문-
파일→ 수식(fx) 사용:{ name: Topic.첨부파일.Name, contentBytes: Topic.첨부파일.Content }
포인트: Copilot Studio의 파일 변수와 Power Automate 트리거의 파일 입력은 스키마가 달라서, Copilot Studio 쪽에서 record(레코드)로 직접 매핑해줘야 합니다.
Name,Content두 속성이 핵심. (테넌트 버전에 따라 속성 이름이Name/Content또는name/contentBytes등으로 다를 수 있으니 흐름 트리거의 입력 스키마와 일치하도록 확인하세요.)
Step 16. 결과 메시지 노드
- 흐름 호출 노드 다음 → 메시지 노드 추가
- 메시지 본문에 흐름 출력 변수
결과텍스트삽입 - 토픽 저장 + 게시
Step 17. 전체 테스트
- 우측 테스트 패널 → 새 대화 시작
- 첫 입력:
엑셀 분석 스크립트 - “어떤 분석을 원하시나요?” →
사과의 연도별 평균 판매량은? - “분석할 Excel 파일을 첨부해주세요” →
과일판매_Table.xlsx - 약 5~15초 대기 후 분석 결과 출력 확인
체크포인트: 결과가 일반론으로만 나오면 다음 순서로 확인:
- 흐름 실행 이력에서
데이터JSON입력이 비어있지 않은지- 토픽 변수 매핑의
Name/Content속성명이 흐름 트리거 입력과 일치하는지- 질문 노드의 파일 메타데이터 활성화 가 켜져 있는지
- AI 프롬프트 결과가 이상하면 → 코드 인터프리터 ON/OFF 를 바꿔 재시도
3. 같은 질문, 세 가지 길 — 실습 ① vs ② vs ③
| 실습 ① (질문 노드만) | 실습 ② (커넥터+OData) | 실습 ③ (Office Script) | |
|---|---|---|---|
| 적용 범위 | 모든 채널 | 모든 채널 | 모든 채널 |
| 셋업 비용 | 매우 낮음 (5분) | 낮음 (10~12분) | 중간 (20~25분) |
| 흐름 / 코드 | ❌ / ❌ | ✅ / ❌ | ✅ / ✅ |
| 데이터 크기 | 중소형 (Table 필요) | 중형 (≤5,000행) | 중대형 가능 |
| 데이터 가공 | ❌ | △ 단순 필터 | ✅ 결정적 처리 |
| 후속 행동 자동화 | ❌ | ✅ | ✅ |
| 답변 품질 | Table이면 우수 | 우수 | 프롬프트 정교화 필요 |
| 후속 자유 질문 | ✅ 자연스러움 | △ 한 번에 끝남 | △ 한 번에 끝남 |
기본은 실습 ①, 그 다음 실습 ② 입니다. 실습 ③ 은 “커넥터 한계를 넘는 데이터·결정적 가공이 명확히 필요한 시나리오” 에서만 꺼내쓰는 도구로 두세요.
4. 손에 쥔 4단 콤보 — 응용 포인트
이 17 단계를 마치면 다음 자산을 얻습니다.
| 자산 | 한 줄 |
|---|---|
| 토픽 (질문 노드 + 파일) | 채널 무관한 결정적 입력 |
| 흐름 (OneDrive 임시 저장) | 첨부 파일을 LLM 처리 가능한 위치로 이동 |
| Office Script (시트→JSON) | LLM이 읽을 수 있는 형태로 변환 |
| AI 프롬프트 (스키마 + 코드 인터프리터) | 정확한 수치 계산 + 자연어 요약 |
이 4단 콤보는 다른 정형 데이터 시나리오에 그대로 옮겨 쓸 수 있는 패턴입니다. 다음 S3 — 12 패턴 카탈로그 에서 이 패턴을 포함한 12 설계 패턴을 한 자리에 정리합니다.