This page was generated from
docs/examples/DataSet/Dataset_Performance.ipynb.
Interactive online version:
![]() .
.
DataSet Performance¶
This notebook shows the trade-off between inserting data into a database row-by-row and as binary blobs. Inserting the data row-by-row means that we have direct access to all the data and may perform queries directly on the values of the data. On the other hand, as we shall see, this is much slower than inserting the data directly as binary blobs.
First, we choose a new location for the database to ensure that we don’t add a bunch of benchmarking data to the default one.
[1]:
from pathlib import Path
import qcodes as qc
qc.config["core"]["db_location"] = str(
Path.cwd().parent / "example_output" / "testing.db"
)
[2]:
%matplotlib inline
import time
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import qcodes as qc
from qcodes.dataset import (
Measurement,
initialise_or_create_database_at,
load_or_create_experiment,
)
from qcodes.parameters import ManualParameter
[3]:
initialise_or_create_database_at(
Path.cwd().parent / "example_output" / "dataset_performance.db"
)
exp = load_or_create_experiment(experiment_name="tutorial_exp", sample_name="no sample")
Here, we define a simple function to benchmark the time it takes to insert n points with either numeric or array data type. We will compare both the time used to call add_result and the time used for the full measurement.
[4]:
def insert_data(paramtype, npoints, nreps=1):
meas = Measurement(exp=exp)
x1 = ManualParameter("x1")
x2 = ManualParameter("x2")
x3 = ManualParameter("x3")
y1 = ManualParameter("y1")
y2 = ManualParameter("y2")
meas.register_parameter(x1, paramtype=paramtype)
meas.register_parameter(x2, paramtype=paramtype)
meas.register_parameter(x3, paramtype=paramtype)
meas.register_parameter(y1, setpoints=[x1, x2, x3], paramtype=paramtype)
meas.register_parameter(y2, setpoints=[x1, x2, x3], paramtype=paramtype)
start = time.perf_counter()
rng = np.random.default_rng()
with meas.run() as datasaver:
start_adding = time.perf_counter()
for i in range(nreps):
datasaver.add_result(
(x1, rng.random(npoints)),
(x2, rng.random(npoints)),
(x3, rng.random(npoints)),
(y1, rng.random(npoints)),
(y2, rng.random(npoints)),
)
stop_adding = time.perf_counter()
run_id = datasaver.run_id
stop = time.perf_counter()
tot_time = stop - start
add_time = stop_adding - start_adding
return tot_time, add_time, run_id
Comparison between numeric/array data and binary blob¶
Case1: Short experiment time¶
[5]:
sizes = [1, 250, 500, 750, 1000]
t_numeric = []
t_numeric_add = []
t_array = []
t_array_add = []
for size in sizes:
tn, tna, run_id_n = insert_data("numeric", size)
t_numeric.append(tn)
t_numeric_add.append(tna)
ta, taa, run_id_a = insert_data("array", size)
t_array.append(ta)
t_array_add.append(taa)
Starting experimental run with id: 1.
Starting experimental run with id: 2.
Starting experimental run with id: 3.
Starting experimental run with id: 4.
Starting experimental run with id: 5.
Starting experimental run with id: 6.
Starting experimental run with id: 7.
Starting experimental run with id: 8.
Starting experimental run with id: 9.
Starting experimental run with id: 10.
[6]:
fig, ax = plt.subplots(1, 1)
ax.plot(sizes, t_numeric, "o-", label="Inserting row-by-row")
ax.plot(sizes, t_numeric_add, "o-", label="Inserting row-by-row: add_result only")
ax.plot(sizes, t_array, "d-", label="Inserting as binary blob")
ax.plot(sizes, t_array_add, "d-", label="Inserting as binary blob: add_result only")
ax.legend()
ax.set_xlabel("Array length")
ax.set_ylabel("Time (s)")
fig.tight_layout()
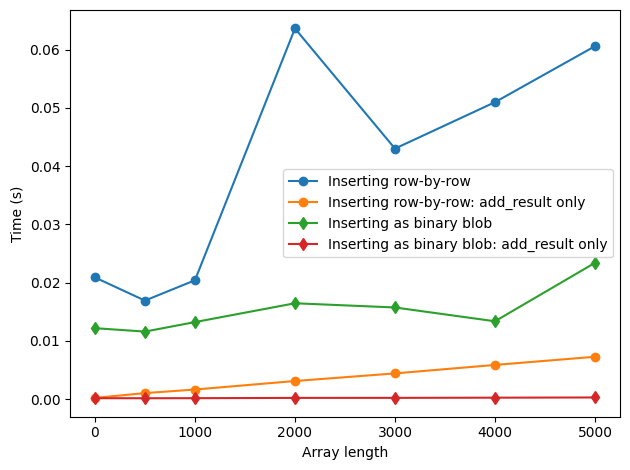
As shown in the latter figure, the time to setup and and close the experiment is approximately 0.4 sec. In case of small array sizes, the difference between inserting values of data as arrays and inserting them row-by-row is relatively unimportant. At larger array sizes, i.e. above 10000 points, the cost of writing data as individual datapoints starts to become important.
Case2: Long experiment time¶
[7]:
sizes = [1, 250, 500, 750, 1000]
nreps = 10
t_numeric = []
t_numeric_add = []
t_numeric_run_ids = []
t_array = []
t_array_add = []
t_array_run_ids = []
for size in sizes:
tn, tna, run_id_n = insert_data("numeric", size, nreps=nreps)
t_numeric.append(tn)
t_numeric_add.append(tna)
t_numeric_run_ids.append(run_id_n)
ta, taa, run_id_a = insert_data("array", size, nreps=nreps)
t_array.append(ta)
t_array_add.append(taa)
t_array_run_ids.append(run_id_a)
Starting experimental run with id: 11.
Starting experimental run with id: 12.
Starting experimental run with id: 13.
Starting experimental run with id: 14.
Starting experimental run with id: 15.
Starting experimental run with id: 16.
Starting experimental run with id: 17.
Starting experimental run with id: 18.
Starting experimental run with id: 19.
Starting experimental run with id: 20.
[8]:
fig, ax = plt.subplots(1, 1)
ax.plot(sizes, t_numeric, "o-", label="Inserting row-by-row")
ax.plot(sizes, t_numeric_add, "o-", label="Inserting row-by-row: add_result only")
ax.plot(sizes, t_array, "d-", label="Inserting as binary blob")
ax.plot(sizes, t_array_add, "d-", label="Inserting as binary blob: add_result only")
ax.legend()
ax.set_xlabel("Array length")
ax.set_ylabel("Time (s)")
fig.tight_layout()
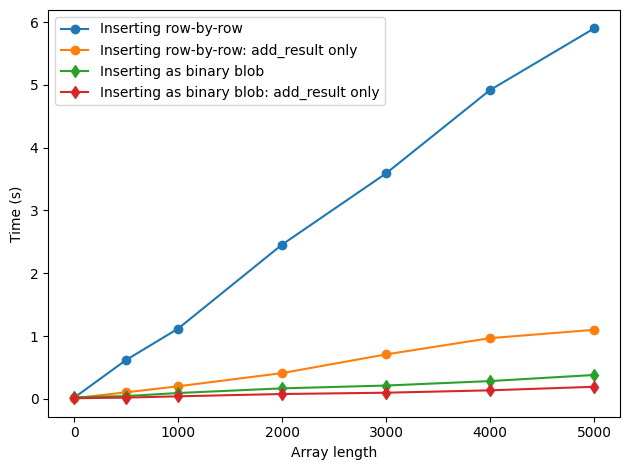
However, as we increase the length of the experiment, as seen here by repeating the insertion 100 times, we see a big difference between inserting values of the data row-by-row and inserting it as a binary blob.
Loading the data¶
[9]:
from qcodes.dataset import load_by_id
As usual you can load the data by using the load_by_id function but you will notice that the different storage methods are reflected in shape of the data as it is retrieved.
[10]:
run_id_n = t_numeric_run_ids[0]
run_id_a = t_array_run_ids[0]
[11]:
ds = load_by_id(run_id_n)
ds.get_parameter_data("x1")
[11]:
{'x1': {'x1': array([0.29299937, 0.29299937, 0.12832296, 0.12832296, 0.40660771,
0.40660771, 0.37240218, 0.37240218, 0.45008651, 0.45008651,
0.73195619, 0.73195619, 0.92821591, 0.92821591, 0.99152499,
0.99152499, 0.54669543, 0.54669543, 0.2898504 , 0.2898504 ])}}
And a dataset stored as binary arrays
[12]:
ds = load_by_id(run_id_a)
ds.get_parameter_data("x1")
[12]:
{'x1': {'x1': array([[0.71922696],
[0.71922696],
[0.0726944 ],
[0.0726944 ],
[0.23327809],
[0.23327809],
[0.82635092],
[0.82635092],
[0.45866718],
[0.45866718],
[0.98357243],
[0.98357243],
[0.32176325],
[0.32176325],
[0.66753241],
[0.66753241],
[0.54807644],
[0.54807644],
[0.64214662],
[0.64214662]])}}
[ ]: