This page was generated from
docs/examples/DataSet/Performing-measurements-using-qcodes-parameters-and-dataset.ipynb.
Interactive online version:
![]() .
.
Performing measurements using QCoDeS parameters and DataSet¶
This notebook shows some ways of performing different measurements using QCoDeS parameters and the DataSet via a powerful Measurement context manager. Here, it is assumed that the reader has some degree of familiarity with fundamental objects and methods of QCoDeS.
Implementing a measurement¶
Now, let us start with necessary imports:
[1]:
%matplotlib inline
from pathlib import Path
from time import monotonic, sleep
import numpy as np
import qcodes as qc
from qcodes.dataset import (
Measurement,
initialise_or_create_database_at,
load_by_guid,
load_by_run_spec,
load_or_create_experiment,
plot_dataset,
)
from qcodes.dataset.descriptions.detect_shapes import detect_shape_of_measurement
from qcodes.instrument_drivers.mock_instruments import (
DummyInstrument,
DummyInstrumentWithMeasurement,
)
from qcodes.logger import start_all_logging
start_all_logging()
Logging hadn't been started.
Activating auto-logging. Current session state plus future input saved.
Filename : /home/runner/.qcodes/logs/command_history.log
Mode : append
Output logging : True
Raw input log : False
Timestamping : True
State : active
Qcodes Logfile : /home/runner/.qcodes/logs/260513-18842-qcodes.log
In what follows, we shall define some utility functions as well as declare our dummy instruments. We, then, add these instruments to a Station object.
The dummy dmm is setup to generate an output depending on the values set on the dummy dac simulating a real experiment.
[2]:
# preparatory mocking of physical setup
dac = DummyInstrument("dac", gates=["ch1", "ch2"])
dmm = DummyInstrumentWithMeasurement(name="dmm", setter_instr=dac)
station = qc.Station(dmm, dac)
[3]:
# now make some silly set-up and tear-down actions
def veryfirst():
print("Starting the measurement")
def numbertwo(inst1, inst2):
print(f"Doing stuff with the following two instruments: {inst1}, {inst2}")
def thelast():
print("End of experiment")
Note that database and experiments may be missing.
If this is the first time you create a dataset, the underlying database file has most likely not been created. The following cell creates the database file. Please refer to documentation on The Experiment Container for details.
Furthermore, datasets are associated to an experiment. By default, a dataset (or “run”) is appended to the latest existing experiments. If no experiment has been created, we must create one. We do that by calling the load_or_create_experiment function.
Here we explicitly pass the loaded or created experiment to the Measurement object to ensure that we are always using the performing_meas_using_parameters_and_dataset Experiment created within this tutorial. Note that a keyword argument name can also be set as any string value for Measurement which later becomes the name of the dataset that running that Measurement produces.
[4]:
initialise_or_create_database_at(
Path.cwd().parent / "example_output" / "performing_meas.db"
)
exp = load_or_create_experiment(
experiment_name="performing_meas_using_parameters_and_dataset",
sample_name="no sample",
)
And then run an experiment:
[5]:
meas = Measurement(exp=exp, name="exponential_decay")
meas.register_parameter(dac.ch1) # register the first independent parameter
meas.register_parameter(dmm.v1, setpoints=(dac.ch1,)) # now register the dependent oone
meas.add_before_run(veryfirst, ()) # add a set-up action
meas.add_before_run(numbertwo, (dmm, dac)) # add another set-up action
meas.add_after_run(thelast, ()) # add a tear-down action
meas.write_period = 0.5
with meas.run() as datasaver:
for set_v in np.linspace(0, 25, 10):
dac.ch1.set(set_v)
get_v = dmm.v1.get()
datasaver.add_result((dac.ch1, set_v), (dmm.v1, get_v))
dataset1D = datasaver.dataset # convenient to have for data access and plotting
Starting the measurement
Doing stuff with the following two instruments: <DummyInstrumentWithMeasurement: dmm>, <DummyInstrument: dac>
Starting experimental run with id: 1.
End of experiment
[6]:
ax, cbax = plot_dataset(dataset1D)
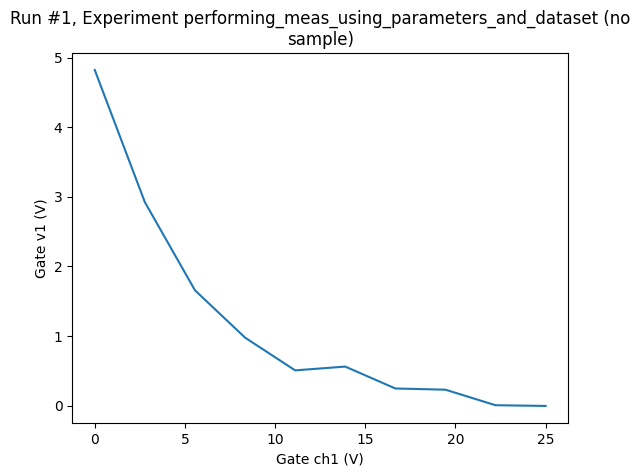
And let’s add an example of a 2D measurement. For the 2D, we’ll need a new batch of parameters, notably one with two other parameters as setpoints. We therefore define a new Measurement with new parameters.
[7]:
meas = Measurement(exp=exp, name="2D_measurement_example")
meas.register_parameter(dac.ch1) # register the first independent parameter
meas.register_parameter(dac.ch2) # register the second independent parameter
meas.register_parameter(
dmm.v2, setpoints=(dac.ch1, dac.ch2)
) # now register the dependent oone
[7]:
<qcodes.dataset.measurements.Measurement at 0x7fd587ea1490>
[8]:
# run a 2D sweep
with meas.run() as datasaver:
for v1 in np.linspace(-1, 1, 50):
for v2 in np.linspace(-1, 1, 50):
dac.ch1(v1)
dac.ch2(v2)
val = dmm.v2.get()
datasaver.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v2, val))
dataset2D = datasaver.dataset
Starting experimental run with id: 2.
[9]:
ax, cbax = plot_dataset(dataset2D)
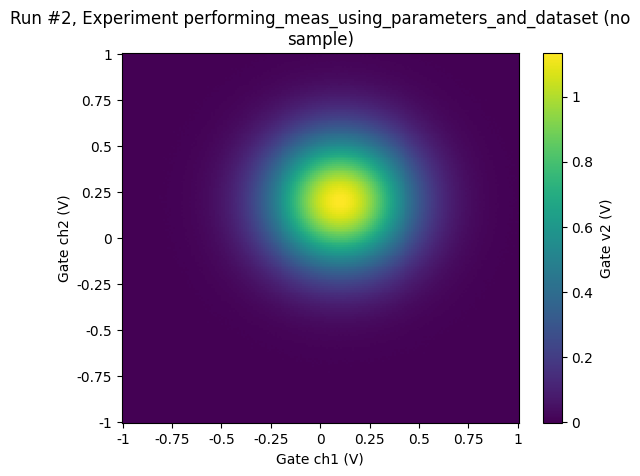
Accessing and exporting the measured data¶
QCoDeS DataSet implements a number of methods for accessing the data of a given dataset. Here we will concentrate on the two most user friendly methods. For a more detailed walkthrough of the DataSet class, refer to DataSet class walkthrough notebook.
The method get_parameter_data returns the data as a dictionary of numpy arrays. The dictionary is indexed by the measured (dependent) parameter in the outermost level and the names of the dependent and independent parameters in the innermost level. The first parameter in the innermost level is always the dependent parameter.
[10]:
dataset1D.get_parameter_data()
[10]:
{'dmm_v1': {'dmm_v1': array([ 5.04922184e+00, 2.76851620e+00, 1.52010955e+00, 8.68414016e-01,
5.23328541e-01, 2.90414165e-01, 1.49044063e-01, 1.58898294e-01,
-1.07168853e-02, 3.18149834e-03]),
'dac_ch1': array([ 0. , 2.77777778, 5.55555556, 8.33333333, 11.11111111,
13.88888889, 16.66666667, 19.44444444, 22.22222222, 25. ])}}
By default get_parameter_data returns all data stored in the dataset. The data that is specific to one or more measured parameters can be returned by passing the parameter name(s) or by using ParamSpec object:
[11]:
dataset1D.get_parameter_data("dmm_v1")
[11]:
{'dmm_v1': {'dmm_v1': array([ 5.04922184e+00, 2.76851620e+00, 1.52010955e+00, 8.68414016e-01,
5.23328541e-01, 2.90414165e-01, 1.49044063e-01, 1.58898294e-01,
-1.07168853e-02, 3.18149834e-03]),
'dac_ch1': array([ 0. , 2.77777778, 5.55555556, 8.33333333, 11.11111111,
13.88888889, 16.66666667, 19.44444444, 22.22222222, 25. ])}}
You can also simply fetch the data for one or more dependent parameter
[12]:
dataset1D.get_parameter_data("dac_ch1")
[12]:
{'dac_ch1': {'dac_ch1': array([ 0. , 2.77777778, 5.55555556, 8.33333333, 11.11111111,
13.88888889, 16.66666667, 19.44444444, 22.22222222, 25. ])}}
For more details about accessing data of a given DataSet, see Accessing data in DataSet notebook.
The data can also be exported as one or more Pandas DataFrames. The DataFrames cane be returned either as a single dataframe or as a dictionary from measured parameters to DataFrames. If you measure all parameters as a function of the same set of parameters you probably want to export to a single dataframe.
[13]:
dataset1D.to_pandas_dataframe()
[13]:
| dmm_v1 | |
|---|---|
| dac_ch1 | |
| 0.000000 | 5.049222 |
| 2.777778 | 2.768516 |
| 5.555556 | 1.520110 |
| 8.333333 | 0.868414 |
| 11.111111 | 0.523329 |
| 13.888889 | 0.290414 |
| 16.666667 | 0.149044 |
| 19.444444 | 0.158898 |
| 22.222222 | -0.010717 |
| 25.000000 | 0.003181 |
However, there may be cases where the data within a dataset cannot be put into a single dataframe. In those cases you can use the other method to export the dataset to a dictionary from name of the measured parameter to Pandas dataframes.
[14]:
dataset1D.to_pandas_dataframe_dict()
[14]:
{'dmm_v1': dmm_v1
dac_ch1
0.000000 5.049222
2.777778 2.768516
5.555556 1.520110
8.333333 0.868414
11.111111 0.523329
13.888889 0.290414
16.666667 0.149044
19.444444 0.158898
22.222222 -0.010717
25.000000 0.003181}
When exporting a two or higher dimensional datasets as a Pandas DataFrame a MultiIndex is used to index the measured parameter based on all the dependencies
[15]:
dataset2D.to_pandas_dataframe()[0:10]
[15]:
| dmm_v2 | ||
|---|---|---|
| dac_ch1 | dac_ch2 | |
| -1.0 | -1.000000 | -0.000454 |
| -0.959184 | 0.000232 | |
| -0.918367 | 0.000732 | |
| -0.877551 | -0.000050 | |
| -0.836735 | 0.000090 | |
| -0.795918 | -0.000044 | |
| -0.755102 | 0.000063 | |
| -0.714286 | -0.000280 | |
| -0.673469 | 0.001178 | |
| -0.632653 | 0.000135 |
If your data is on a regular grid it may make sense to view the data as an XArray Dataset. The dataset can be directly exported to a XArray Dataset.
[16]:
dataset2D.to_xarray_dataset()
[16]:
<xarray.Dataset> Size: 21kB
Dimensions: (dac_ch1: 50, dac_ch2: 50)
Coordinates:
* dac_ch1 (dac_ch1) float64 400B -1.0 -0.9592 -0.9184 ... 0.9184 0.9592 1.0
* dac_ch2 (dac_ch2) float64 400B -1.0 -0.9592 -0.9184 ... 0.9184 0.9592 1.0
Data variables:
dmm_v2 (dac_ch1, dac_ch2) float64 20kB -0.0004537 0.0002316 ... -0.0002644
Attributes: (12/14)
ds_name: 2D_measurement_example
sample_name: no sample
exp_name: performing_meas_using_parameters_and_dataset
snapshot: {"station": {"instruments": {"dmm": {"functions...
guid: d3bc6889-0000-0000-0000-019e1fd40f7f
run_timestamp: 2026-05-13 05:34:11
... ...
captured_counter: 2
run_id: 2
run_description: {"version": 3, "interdependencies": {"paramspec...
parent_dataset_links: []
run_timestamp_raw: 1778650451.8454213
completed_timestamp_raw: 1778650452.1406958Note, however, that XArray is only suited for data that is on a rectangular grid with few or no missing values. If the data does not lie on a grid, all the measured data points will have an unique combination of the two dependent parameters. When exporting to XArray, NaN’s will therefore replace all the missing combinations of dac_ch1 and dac_ch2 and the data is unlikely to be useful in this format.
For more details about using Pandas and XArray see Working With Pandas and XArray
It is also possible to export the datasets directly to various file formats see Exporting QCoDes Datasets
Reloading datasets¶
To load existing datasets QCoDeS provides several functions. The most useful and generic function is called load_by_run_spec. This function takes one or more pieces of information about a dataset and will either, if the dataset is uniquely identifiable by the information, load the dataset or print information about all the datasets that match the supplied information allowing you to provide more information to uniquely identify the dataset.
Here, we will load a dataset based on the captured_run_id printed on the plot above.
[17]:
dataset1D.captured_run_id
[17]:
1
[18]:
loaded_ds = load_by_run_spec(captured_run_id=dataset1D.captured_run_id)
[19]:
loaded_ds.the_same_dataset_as(dataset1D)
[19]:
True
As long as you are working within one database file the dataset should be uniquely identified by captured_run_id. However, once you mix several datasets from different database files this is likely not unique. See the following section and Extracting runs from one DB file to another for more information on how to handle this.
DataSet GUID¶
Internally each dataset is refereed too by a Globally Unique Identifier (GUID) that ensures that the dataset uniquely identified even if datasets from several databases with potentially identical captured_run_id, experiment and sample names. A dataset can always be reloaded from the GUID if known.
[20]:
print(f"Dataset GUID is: {dataset1D.guid}")
Dataset GUID is: 80958d25-0000-0000-0000-019e1fd40ef0
[21]:
loaded_ds = load_by_guid(dataset1D.guid)
[22]:
loaded_ds.the_same_dataset_as(dataset1D)
[22]:
True
Specifying shape of measurement¶
As the context manager allows you to store data of any shape (with the only restriction being that you supply values for both dependent and independent parameters together), it cannot know if the data is being measured on a grid. As a consequence, the Numpy array of data loaded from the dataset may not be of the shape that you expect. plot_dataset, DataSet.to_pandas... and DataSet.to_xarray... contain logic that can detect the shape of the data measured at load time. However, if you
know the shape of the measurement that you are going to perform up front, you can choose to specify it before initializing the measurement using Measurement.set_shapes method.
dataset.get_parameter_data and dataset.cache.data automatically makes use of this information to return shaped data when loaded from the database. Note that these two methods behave slightly different when loading data on a partially completed dataset. dataset.get_parameter_data will only reshape the data if the number of points measured matches the number of points expected according to the metadata. dataset.cache.data will however return a dataset with empty placeholders
(either NaN, zeros or empty strings depending on the datatypes) for missing values in a partially filled dataset.
Note that if you use the doNd functions demonstrated in Using doNd functions in comparison to Measurement context manager for performing measurements the shape information will be detected and stored automatically.
In the example below we show how the shape can be specified manually.
[23]:
n_points_1 = 25
n_points_2 = 50
meas_with_shape = Measurement(exp=exp, name="shape_specification_example_measurement")
meas_with_shape.register_parameter(dac.ch1) # register the first independent parameter
meas_with_shape.register_parameter(dac.ch2) # register the second independent parameter
meas_with_shape.register_parameter(
dmm.v2, setpoints=(dac.ch1, dac.ch2)
) # now register the dependent oone
meas_with_shape.set_shapes(
detect_shape_of_measurement((dmm.v2,), (n_points_1, n_points_2))
)
with meas_with_shape.run() as datasaver:
for v1 in np.linspace(-1, 1, n_points_1):
for v2 in np.linspace(-1, 1, n_points_2):
dac.ch1(v1)
dac.ch2(v2)
val = dmm.v2.get()
datasaver.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v2, val))
dataset = datasaver.dataset # convenient to have for plotting
Starting experimental run with id: 3.
[24]:
for name, data in dataset.get_parameter_data()["dmm_v2"].items():
print(
f"{name}: data.shape={data.shape}, expected_shape=({n_points_1},{n_points_2})"
)
assert data.shape == (n_points_1, n_points_2)
dmm_v2: data.shape=(25, 50), expected_shape=(25,50)
dac_ch1: data.shape=(25, 50), expected_shape=(25,50)
dac_ch2: data.shape=(25, 50), expected_shape=(25,50)
Performing several measuments concurrently¶
It is possible to perform two or more measurements at the same time. This may be convenient if you need to measure several parameters as a function of the same independent parameters.
[25]:
# setup two measurements
meas1 = Measurement(exp=exp, name="multi_measurement_1")
meas1.register_parameter(dac.ch1)
meas1.register_parameter(dac.ch2)
meas1.register_parameter(dmm.v1, setpoints=(dac.ch1, dac.ch2))
meas2 = Measurement(exp=exp, name="multi_measurement_2")
meas2.register_parameter(dac.ch1)
meas2.register_parameter(dac.ch2)
meas2.register_parameter(dmm.v2, setpoints=(dac.ch1, dac.ch2))
with meas1.run() as datasaver1, meas2.run() as datasaver2:
v1points = np.concatenate(
(
np.linspace(-2, -0.5, 10),
np.linspace(-0.51, 0.5, 30),
np.linspace(0.51, 2, 10),
)
)
v2points = np.concatenate(
(
np.linspace(-2, -0.25, 10),
np.linspace(-0.26, 0.5, 30),
np.linspace(0.51, 2, 10),
)
)
for v1 in v1points:
for v2 in v2points:
dac.ch1(v1)
dac.ch2(v2)
val1 = dmm.v1.get()
datasaver1.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v1, val1))
val2 = dmm.v2.get()
datasaver2.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v2, val2))
Starting experimental run with id: 4.
Starting experimental run with id: 5.
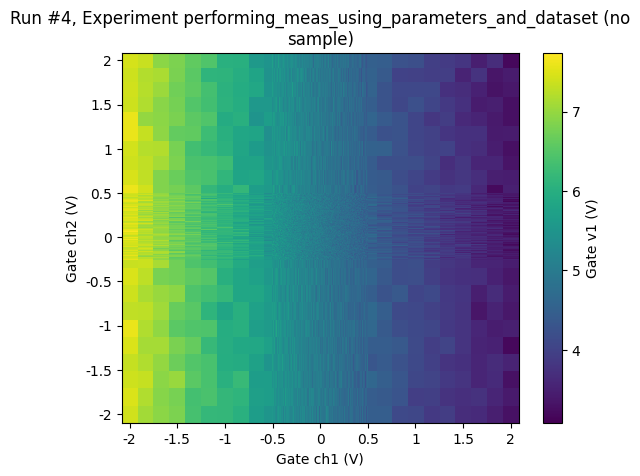
[26]:
ax, cbax = plot_dataset(datasaver1.dataset)
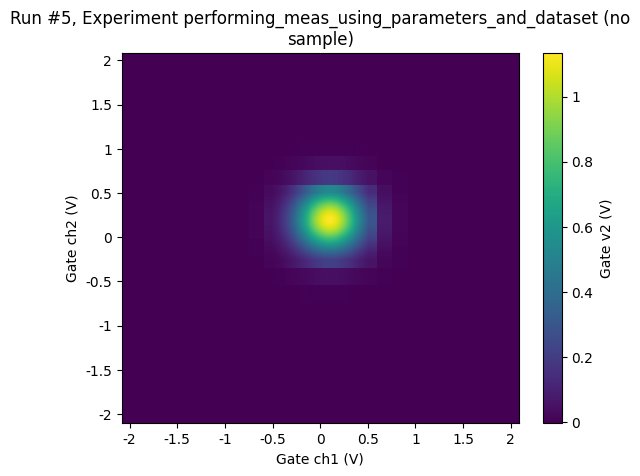
[27]:
ax, cbax = plot_dataset(datasaver2.dataset)
Interrupting measurements early¶
There may be cases where you do not want to complete a measurement. Currently QCoDeS is designed to allow the user to interrupt the measurements with a standard KeyBoardInterrupt. KeyBoardInterrupts can be raised with either a Ctrl-C keyboard shortcut or using the interrupt button in Juypter / Spyder which is typically in the form of a Square stop button. QCoDeS is designed such that KeyboardInterrupts are delayed around critical parts of the code and the measurement is stopped when its safe to do so.
QCoDeS Array and MultiParameter¶
The Measurement object supports automatic handling of Array and MultiParameters. When registering these parameters the individual components are unpacked and added to the dataset as if they were separate parameters. Lets consider a MultiParamter with array components as the most general case.
First lets use a dummy instrument that produces data as Array and MultiParameters.
[28]:
from qcodes.instrument_drivers.mock_instruments import DummyChannelInstrument
[29]:
mydummy = DummyChannelInstrument("MyDummy")
This instrument produces two Arrays with the names, shapes and setpoints given below.
[30]:
mydummy.A.dummy_2d_multi_parameter.names
[30]:
('this', 'that')
[31]:
mydummy.A.dummy_2d_multi_parameter.shapes
[31]:
((5, 3), (5, 3))
[32]:
mydummy.A.dummy_2d_multi_parameter.setpoint_names
[32]:
(('multi_2d_setpoint_param_this_setpoint',
'multi_2d_setpoint_param_that_setpoint'),
('multi_2d_setpoint_param_this_setpoint',
'multi_2d_setpoint_param_that_setpoint'))
[33]:
meas = Measurement(exp=exp)
meas.register_parameter(mydummy.A.dummy_2d_multi_parameter)
meas.parameters
[33]:
{'MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint': ParamSpecBase('MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint', 'numeric', 'this setpoint', 'this setpointunit'),
'MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint': ParamSpecBase('MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint', 'numeric', 'that setpoint', 'that setpointunit'),
'MyDummy_ChanA_this': ParamSpecBase('MyDummy_ChanA_this', 'numeric', 'this label', 'this unit'),
'MyDummy_ChanA_that': ParamSpecBase('MyDummy_ChanA_that', 'numeric', 'that label', 'that unit')}
When adding the MultiParameter to the measurement we can see that we add each of the individual components as a separate parameter.
[34]:
with meas.run() as datasaver:
datasaver.add_result(
(mydummy.A.dummy_2d_multi_parameter, mydummy.A.dummy_2d_multi_parameter())
)
Starting experimental run with id: 6.
And when adding the result of a MultiParameter it is automatically unpacked into its components.
[35]:
plot_dataset(datasaver.dataset)
[35]:
([<Axes: title={'center': 'Run #6, Experiment performing_meas_using_parameters_and_dataset (no\nsample)'}, xlabel='this setpoint (this setpointunit)', ylabel='that setpoint (that setpointunit)'>,
<Axes: title={'center': 'Run #6, Experiment performing_meas_using_parameters_and_dataset (no\nsample)'}, xlabel='this setpoint (this setpointunit)', ylabel='that setpoint (that setpointunit)'>],
[<matplotlib.colorbar.Colorbar at 0x7fd525d00410>,
<matplotlib.colorbar.Colorbar at 0x7fd525bf55b0>])
[36]:
datasaver.dataset.get_parameter_data("MyDummy_ChanA_that")
[36]:
{'MyDummy_ChanA_that': {'MyDummy_ChanA_that': array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]),
'MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint': array([5., 5., 5., 6., 6., 6., 7., 7., 7., 8., 8., 8., 9., 9., 9.]),
'MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint': array([ 9., 10., 11., 9., 10., 11., 9., 10., 11., 9., 10., 11., 9.,
10., 11.])}}
[37]:
datasaver.dataset.to_pandas_dataframe()
[37]:
| MyDummy_ChanA_that | MyDummy_ChanA_this | ||
|---|---|---|---|
| MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint | MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint | ||
| 5.0 | 9.0 | 1.0 | 0.0 |
| 10.0 | 1.0 | 0.0 | |
| 11.0 | 1.0 | 0.0 | |
| 6.0 | 9.0 | 1.0 | 0.0 |
| 10.0 | 1.0 | 0.0 | |
| 11.0 | 1.0 | 0.0 | |
| 7.0 | 9.0 | 1.0 | 0.0 |
| 10.0 | 1.0 | 0.0 | |
| 11.0 | 1.0 | 0.0 | |
| 8.0 | 9.0 | 1.0 | 0.0 |
| 10.0 | 1.0 | 0.0 | |
| 11.0 | 1.0 | 0.0 | |
| 9.0 | 9.0 | 1.0 | 0.0 |
| 10.0 | 1.0 | 0.0 | |
| 11.0 | 1.0 | 0.0 |
[38]:
datasaver.dataset.to_xarray_dataset()
[38]:
<xarray.Dataset> Size: 304B
Dimensions: (
MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint: 5,
MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint: 3)
Coordinates:
* MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint (MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint) float64 40B ...
* MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint (MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint) float64 24B ...
Data variables:
MyDummy_ChanA_that (MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint, MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint) float64 120B ...
MyDummy_ChanA_this (MyDummy_ChanA_multi_2d_setpoint_param_this_setpoint, MyDummy_ChanA_multi_2d_setpoint_param_that_setpoint) float64 120B ...
Attributes: (12/14)
ds_name: results
sample_name: no sample
exp_name: performing_meas_using_parameters_and_dataset
snapshot: {"station": {"instruments": {"dmm": {"functions...
guid: 5dbf4c78-0000-0000-0000-019e1fd4191a
run_timestamp: 2026-05-13 05:34:14
... ...
captured_counter: 6
run_id: 6
run_description: {"version": 3, "interdependencies": {"paramspec...
parent_dataset_links: []
run_timestamp_raw: 1778650454.3069472
completed_timestamp_raw: 1778650454.3114161Avoiding verbosity of the Measurement context manager for simple measurements¶
For simple 1D/2D grid-type of measurements, it may feel like an overkill to use the verbose and flexible Measurement context manager construct. For this case, so-called doNd functions come ti rescue - convenient one- or two-line calls, read more about them in Using doNd functions.
Optimizing measurement time¶
There are measurements that are data-heavy or time consuming, or both. QCoDeS provides some features and tools that should help in optimizing the measurement time. Some of those are:
Setting more appropriate
paramtypewhen registering parameters, see Paramtypes explainedAdding result to datasaver by creating threads per instrument, see Threaded data acquisition
The power of the Measurement context manager construct¶
This new form is so free that we may easily do thing impossible with the old Loop construct.
Say, that from the plot of the above 1D measurement, we decide that a voltage below 1 V is uninteresting, so we stop the sweep at that point, thus, we do not know in advance how many points we’ll measure.
[39]:
meas = Measurement(exp=exp)
meas.register_parameter(dac.ch1) # register the first independent parameter
meas.register_parameter(dmm.v1, setpoints=(dac.ch1,)) # now register the dependent oone
with meas.run() as datasaver:
for set_v in np.linspace(0, 25, 25):
dac.ch1.set(set_v)
get_v = dmm.v1.get()
datasaver.add_result((dac.ch1, set_v), (dmm.v1, get_v))
if get_v < 1:
break
dataset = datasaver.dataset
Starting experimental run with id: 7.
[40]:
ax, cbax = plot_dataset(dataset)
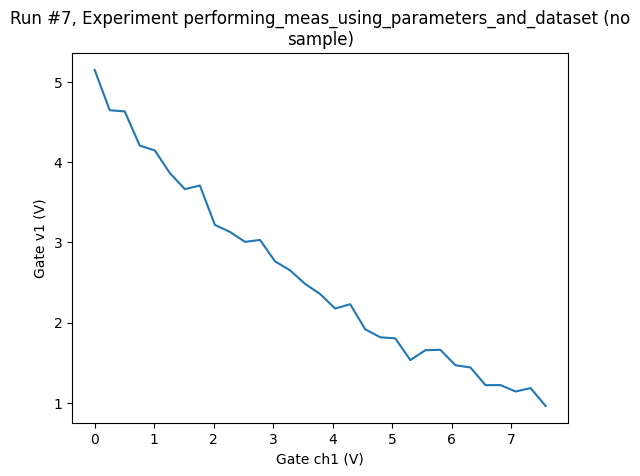
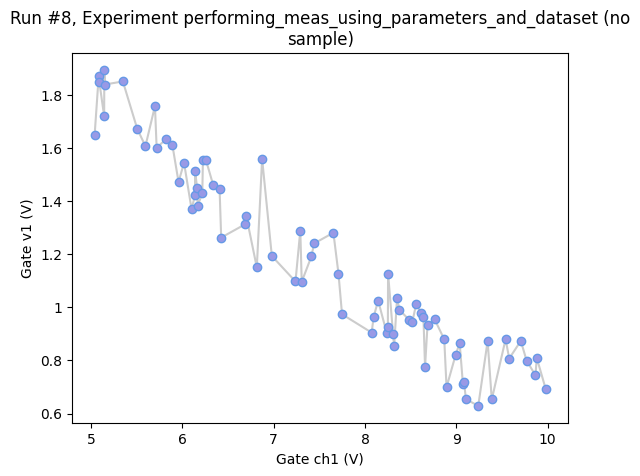
Or we might want to simply get as many points as possible in 10 s randomly sampling the region between 0 V and 10 V (for the setpoint axis).
[41]:
rng = np.random.default_rng()
with meas.run() as datasaver:
t_start = monotonic()
while monotonic() - t_start < 1:
set_v = 10 / 2 * (rng.random() + 1)
dac.ch1.set(set_v)
# some sleep to not get too many points (or to let the system settle)
sleep(0.04)
get_v = dmm.v1.get()
datasaver.add_result((dac.ch1, set_v), (dmm.v1, get_v))
dataset = datasaver.dataset # convenient to have for plotting
Starting experimental run with id: 8.
[42]:
axes, cbax = plot_dataset(dataset)
# we slightly tweak the plot to better visualise the highly non-standard axis spacing
axes[0].lines[0].set_marker("o")
axes[0].lines[0].set_markerfacecolor((0.6, 0.6, 0.9))
axes[0].lines[0].set_markeredgecolor((0.4, 0.6, 0.9))
axes[0].lines[0].set_color((0.8, 0.8, 0.8))
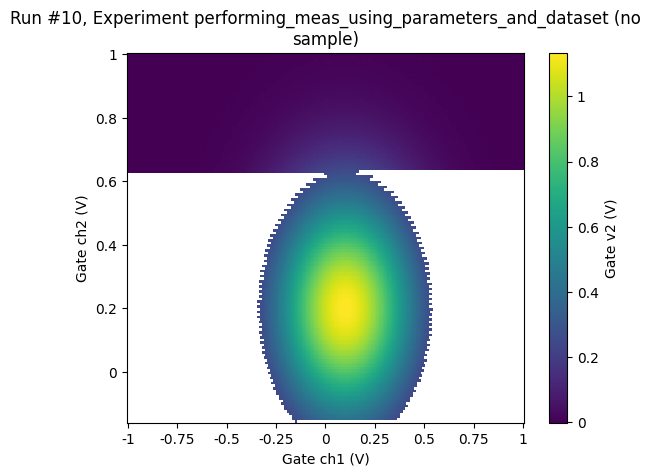
Finer sampling in 2D¶
Looking at the plot of the 2D measurement above, we may decide to sample more finely in the central region:
[43]:
meas = Measurement(exp=exp)
meas.register_parameter(dac.ch1) # register the first independent parameter
meas.register_parameter(dac.ch2) # register the second independent parameter
meas.register_parameter(
dmm.v2, setpoints=(dac.ch1, dac.ch2)
) # now register the dependent oone
[43]:
<qcodes.dataset.measurements.Measurement at 0x7fd525d24140>
[44]:
with meas.run() as datasaver:
v1points = np.concatenate(
(
np.linspace(-1, -0.5, 5),
np.linspace(-0.51, 0.5, 30),
np.linspace(0.51, 1, 5),
)
)
v2points = np.concatenate(
(
np.linspace(-1, -0.25, 5),
np.linspace(-0.26, 0.5, 30),
np.linspace(0.51, 1, 5),
)
)
for v1 in v1points:
for v2 in v2points:
dac.ch1(v1)
dac.ch2(v2)
val = dmm.v2.get()
datasaver.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v2, val))
dataset = datasaver.dataset # convenient to have for plotting
Starting experimental run with id: 9.
[45]:
ax, cbax = plot_dataset(dataset)
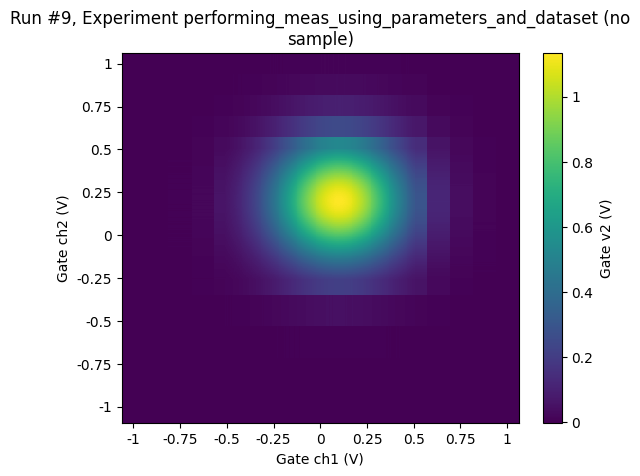
Simple adaptive 2D sweep¶
[46]:
v1_points = np.linspace(-1, 1, 50)
v2_points = np.linspace(1, -1, 50)
threshold = 0.25
with meas.run() as datasaver:
# Do normal sweeping until the peak is detected
for v2ind, v2 in enumerate(v2_points):
for v1ind, v1 in enumerate(v1_points):
dac.ch1(v1)
dac.ch2(v2)
val = dmm.v2.get()
datasaver.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v2, val))
if val > threshold:
break
else:
continue
break
print(v1ind, v2ind, val)
print("-" * 10)
# now be more clever, meandering back and forth over the peak
doneyet = False
rowdone = False
v1_step = 1
while not doneyet:
v2 = v2_points[v2ind]
v1 = v1_points[v1ind + v1_step - 1]
dac.ch1(v1)
dac.ch2(v2)
val = dmm.v2.get()
datasaver.add_result((dac.ch1, v1), (dac.ch2, v2), (dmm.v2, val))
if val < threshold:
if rowdone:
doneyet = True
v2ind += 1
v1_step *= -1
rowdone = True
else:
v1ind += v1_step
rowdone = False
dataset = datasaver.dataset # convenient to have for plotting
Starting experimental run with id: 10.
26 9 0.2501357563995864
----------
[47]:
ax, cbax = plot_dataset(dataset)
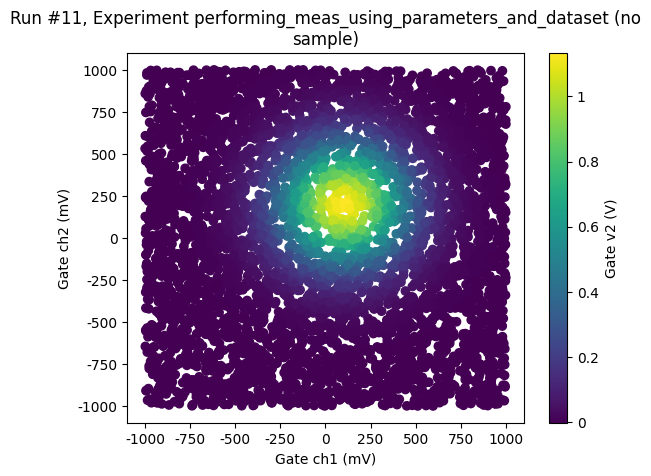
Random sampling¶
We may also chose to sample completely randomly across the phase space
[48]:
rng = np.random.default_rng()
meas2 = Measurement(exp=exp, name="random_sampling_measurement")
meas2.register_parameter(dac.ch1)
meas2.register_parameter(dac.ch2)
meas2.register_parameter(dmm.v2, setpoints=(dac.ch1, dac.ch2))
threshold = 0.25
npoints = 500
with meas2.run() as datasaver:
for i in range(npoints):
x = 2 * (rng.random() - 0.5)
y = 2 * (rng.random() - 0.5)
dac.ch1(x)
dac.ch2(y)
z = dmm.v2()
datasaver.add_result((dac.ch1, x), (dac.ch2, y), (dmm.v2, z))
dataset = datasaver.dataset # convenient to have for plotting
Starting experimental run with id: 11.
[49]:
ax, cbax = plot_dataset(dataset)
[50]:
datasaver.dataset.to_pandas_dataframe()[0:10]
[50]:
| dmm_v2 | ||
|---|---|---|
| dac_ch1 | dac_ch2 | |
| 0.187529 | 0.152993 | 1.047160 |
| -0.163596 | -0.380619 | 0.043242 |
| -0.237297 | 0.011216 | 0.342809 |
| -0.330509 | -0.946925 | 0.001284 |
| 0.299645 | 0.657176 | 0.153665 |
| 0.865500 | 0.574724 | 0.003532 |
| 0.503840 | -0.330451 | 0.032651 |
| 0.873760 | 0.070598 | 0.007508 |
| 0.337266 | 0.667493 | 0.124701 |
| 0.141021 | -0.389276 | 0.068573 |
Unlike the data measured above, which lies on a grid, here, all the measured data points have an unique combination of the two dependent parameters. When exporting to XArray NaN’s will therefore replace all the missing combinations of dac_ch1 and dac_ch2 and the data is unlikely to be useful in this format.
[51]:
datasaver.dataset.to_xarray_dataset()
[51]:
<xarray.Dataset> Size: 16kB
Dimensions: (multi_index: 500)
Coordinates:
* multi_index (multi_index) object 4kB MultiIndex
* dac_ch1 (multi_index) float64 4kB 0.1875 -0.1636 ... -0.4137 -0.6758
* dac_ch2 (multi_index) float64 4kB 0.153 -0.3806 ... -0.6092 -0.2364
Data variables:
dmm_v2 (multi_index) float64 4kB 1.047 0.04324 ... 0.0005347 0.002029
Attributes: (12/14)
ds_name: random_sampling_measurement
sample_name: no sample
exp_name: performing_meas_using_parameters_and_dataset
snapshot: {"station": {"instruments": {"dmm": {"functions...
guid: bd5ddcd2-0000-0000-0000-019e1fd422b0
run_timestamp: 2026-05-13 05:34:16
... ...
captured_counter: 11
run_id: 11
run_description: {"version": 3, "interdependencies": {"paramspec...
parent_dataset_links: []
run_timestamp_raw: 1778650456.7585168
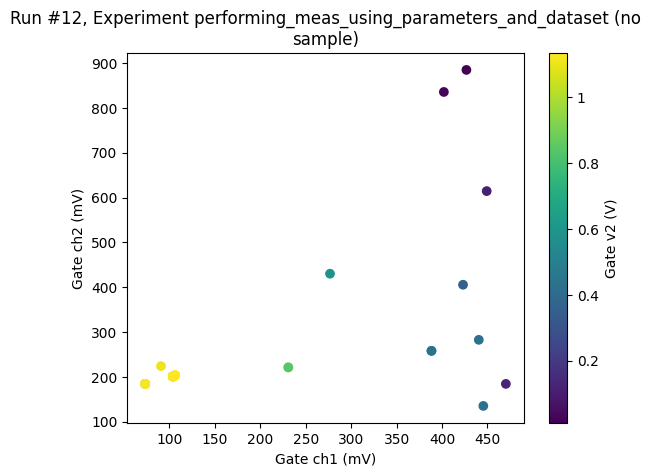
completed_timestamp_raw: 1778650456.8150656Optimiser¶
An example to show that the algorithm is flexible enough to be used with completely unstructured data such as the output of an downhill simplex optimization. The downhill simplex is somewhat more sensitive to noise and it is important that ‘fatol’ is set to match the expected noise.
[52]:
from scipy.optimize import minimize
[53]:
def set_and_measure(*xk):
dac.ch1(xk[0])
dac.ch2(xk[1])
return dmm.v2.get()
noise = 0.0005
x0 = [np.random.default_rng().random(), np.random.default_rng().random()]
with meas.run() as datasaver:
def mycallback(xk):
dac.ch1(xk[0])
dac.ch2(xk[1])
datasaver.add_result(
(dac.ch1, xk[0]), (dac.ch2, xk[1]), (dmm.v2, dmm.v2.cache.get())
)
res = minimize(
lambda x: -set_and_measure(*x),
x0,
method="Nelder-Mead",
tol=1e-10,
callback=mycallback,
options={"fatol": noise},
)
dataset = datasaver.dataset # convenient to have for plotting
Starting experimental run with id: 12.
[54]:
res
[54]:
message: Optimization terminated successfully.
success: True
status: 0
fun: -0.0012351801138589227
x: [ 9.747e-01 8.805e-01]
nit: 61
nfev: 162
final_simplex: (array([[ 9.747e-01, 8.805e-01],
[ 9.747e-01, 8.805e-01],
[ 9.747e-01, 8.805e-01]]), array([-1.235e-03, -8.667e-04, -8.033e-04]))
[55]:
ax, cbax = plot_dataset(dataset)
Subscriptions¶
The Measurement object can also handle subscriptions to the dataset. Subscriptions are, under the hood, triggers in the underlying SQLite database. Therefore, the subscribers are only called when data is written to the database (which happens every write_period).
When making a subscription, two things must be supplied: a function and a mutable state object. The function MUST have a call signature of f(result_list, length, state, **kwargs), where result_list is a list of tuples of parameter values inserted in the dataset, length is an integer (the step number of the run), and state is the mutable state object. The function does not need to actually use these arguments, but the call signature must match this.
Let us consider two generic examples:
Subscription example 1: simple printing¶
[56]:
def print_which_step(results_list, length, state):
"""
This subscriber does not use results_list nor state; it simply
prints how many results we have added to the database
"""
print(f"The run now holds {length} rows")
meas = Measurement(exp=exp)
meas.register_parameter(dac.ch1)
meas.register_parameter(dmm.v1, setpoints=(dac.ch1,))
meas.write_period = 0.2 # We write to the database every 0.2s
meas.add_subscriber(print_which_step, state=[])
with meas.run() as datasaver:
for n in range(7):
datasaver.add_result((dac.ch1, n), (dmm.v1, n**2))
print(f"Added points to measurement, step {n}.")
sleep(0.05)
Starting experimental run with id: 13.
Added points to measurement, step 0.
Added points to measurement, step 1.
Added points to measurement, step 2.
Added points to measurement, step 3.
The run now holds 4 rows
The run now holds 5 rows
Added points to measurement, step 4.
Added points to measurement, step 5.
Added points to measurement, step 6.
The run now holds 7 rows
The run now holds 7 rows
The run now holds 7 rows
Subscription example 2: using the state¶
We add two subscribers now.
[57]:
def get_list_of_first_param(results_list, length, state):
"""
Modify the state (a list) to hold all the values for
the first parameter
"""
param_vals = [parvals[0] for parvals in results_list]
state += param_vals
meas = Measurement(exp=exp)
meas.register_parameter(dac.ch1)
meas.register_parameter(dmm.v1, setpoints=(dac.ch1,))
meas.write_period = 0.2 # We write to the database every 0.2s
first_param_list = []
meas.add_subscriber(print_which_step, state=[])
meas.add_subscriber(get_list_of_first_param, state=first_param_list)
with meas.run() as datasaver:
for n in range(10):
datasaver.add_result((dac.ch1, n), (dmm.v1, n**2))
print(f"Added points to measurement, step {n}.")
print(f"First parameter value list: {first_param_list}")
sleep(0.02)
Starting experimental run with id: 14.
Added points to measurement, step 0.
First parameter value list: []
Added points to measurement, step 1.
First parameter value list: []
Added points to measurement, step 2.
First parameter value list: []
Added points to measurement, step 3.
First parameter value list: []
Added points to measurement, step 4.
First parameter value list: []
Added points to measurement, step 5.
First parameter value list: []
Added points to measurement, step 6.
First parameter value list: []
Added points to measurement, step 7.
First parameter value list: []
Added points to measurement, step 8.
First parameter value list: []
Added points to measurement, step 9.
First parameter value list: []
The run now holds 8 rows
The run now holds 10 rows
The run now holds 10 rows
The run now holds 10 rows
[ ]: