This page was generated from
docs/examples/plotting/auto_color_scale.ipynb.
Interactive online version:
![]() .
.
Auto Color Scale¶
TL;DR¶
use
plot_by_id(run_id, auto_color_scale=True, cutoff_percentile=(0.5, 0.6)to enable automatic color scalingthis maximally cuts 0.5% of the low valued data points and 0.6% of the high valued data points.
You can also use it for matplotlib with the supplied auto scaling function.
Set your defaults in
qcodesrc.json.
Table of contents¶
Introduction to the problem and risks¶
It is a fairly common issue that a heat map plot does not properly show the right details due to some outliers that push the range of the color scale beyond the desired limits, as it is shown in the image below: 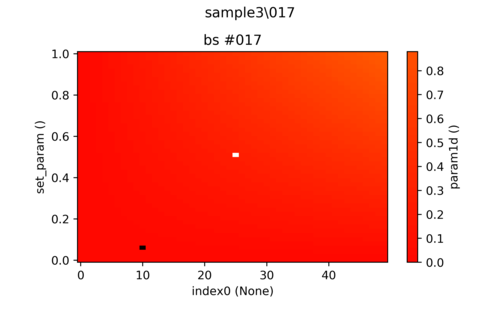 Here there are two pixels (black and white) corresponding to high and low outliers. The remaining data is uniformly displayed as red and the actual structure of it is drowned. One can of course specify the limits of the color bar manually to view the full structure as shown
here:
Here there are two pixels (black and white) corresponding to high and low outliers. The remaining data is uniformly displayed as red and the actual structure of it is drowned. One can of course specify the limits of the color bar manually to view the full structure as shown
here: 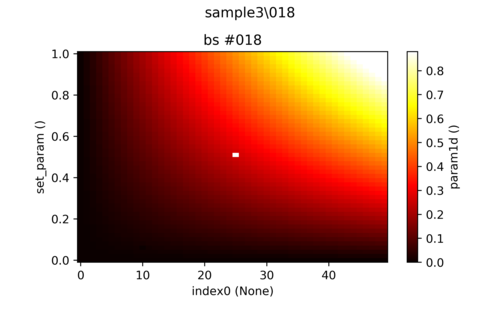 But for measurements that takes a lot of time to perform, manual intervention becomes an unwieldy task.
But for measurements that takes a lot of time to perform, manual intervention becomes an unwieldy task.
In this notebook an automatic color scaling is presented that tries to empower the experimenter to circumvent this difficulty, while keeping possible risks in mind.
The risk narrowing the color scale is clearly that the image representing the data saturates in some regions and is no longer fully representative of the actual data. Especially for automatic color scaling this can become risky because without a theoretical model describing the specific measurement one cannot scientifically argue for the choice of the new limits of the color scale and possible meaningful features might be disregarded.
For this reason automatic color scaling is deactivated by default and has to be activated manually.
Using the automatic color scale¶
The following section presents an example of the usage of the automatic color scaling with the new DataSet and the plot_dataset function for plotting. Let’s first make the necessary imports:
[1]:
# store data in a separate db in order not to spam the actual measurement db
from pathlib import Path
from qcodes.dataset import (
initialise_or_create_database_at,
load_or_create_experiment,
new_data_set,
plot_dataset,
)
initialise_or_create_database_at(Path.cwd().parent / "example_output" / "example.db")
# create an experiment for this tutorial
load_or_create_experiment(
experiment_name="tutorial_auto_color_scale", sample_name="outliers"
)
[1]:
tutorial_auto_color_scale#outliers#1@/home/runner/work/Qcodes/Qcodes/docs/examples/example_output/example.db
------------------------------------------------------------------------------------------------------------
Example 1: outliers in homogeneous data¶
Here we basically reproduce the images of the introduction, where we have some smoothly structured data with some outliers that lie far outside of the range of the remaining data:
[2]:
# first we generate a fake dataset with outliers.
import numpy as np
from qcodes.dataset.descriptions.dependencies import InterDependencies_
from qcodes.parameters import ParamSpecBase
def dataset_with_outliers_generator(
ds, data_offset=5, low_outlier=-3, high_outlier=1, background_noise=True
):
x = ParamSpecBase("x", "numeric", label="Flux", unit="e^2/hbar")
t = ParamSpecBase("t", "numeric", label="Time", unit="s")
z = ParamSpecBase("z", "numeric", label="Majorana number", unit="Anyon")
idps = InterDependencies_(dependencies={z: (x, t)})
ds.set_interdependencies(idps)
ds.mark_started()
npoints = 50
xvals = np.linspace(0, 1, npoints)
tvals = np.linspace(0, 1, npoints)
rng = np.random.default_rng()
for counter, xv in enumerate(xvals):
if background_noise and (
counter < round(npoints / 2.3) or counter > round(npoints / 1.8)
):
data = rng.random(npoints) - data_offset
else:
data = xv * np.linspace(0, 1, npoints)
if counter == round(npoints / 1.9):
data[round(npoints / 1.9)] = high_outlier
if counter == round(npoints / 2.1):
data[round(npoints / 2.5)] = low_outlier
ds.add_results([{"x": xv, "t": tv, "z": z} for z, tv in zip(data, tvals)])
ds.mark_completed()
return ds
[3]:
# create a new dataset with outliers
ds = dataset_with_outliers_generator(
new_data_set("data_with_outliers"),
low_outlier=-3,
high_outlier=3,
background_noise=False,
)
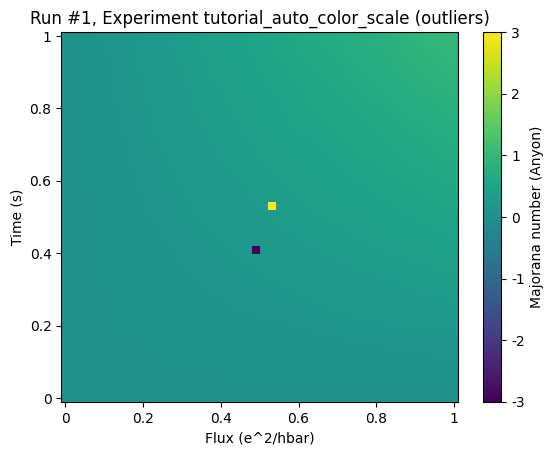
by plotting it simply by plot_dataset we get the full range
[4]:
ax, cb = plot_dataset(ds)
By adding the keyword auto_color_scale=True one activates the scaling:
[5]:
ax, cb = plot_dataset(ds, auto_color_scale=True)
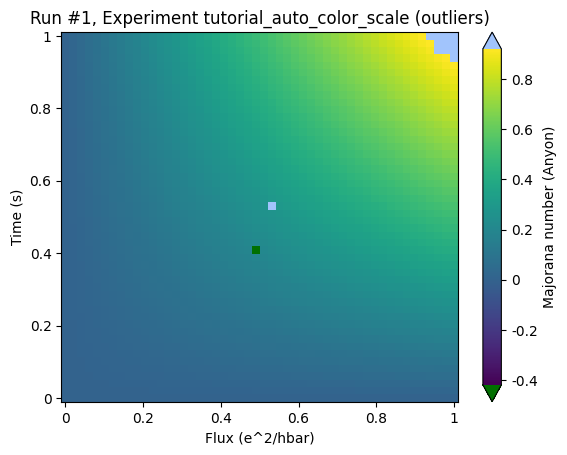
and the actual structure of the data becomes visible.
Please note two further details:
The triangles that appeared at the top and the bottom of the color bar: These indicate that the color bar does not cover the full range of the data spectrum.
The clipped regions are marked with colors that are clearly not part of the color scale in order to clearly separate those regions where we cannot make any claim about any structure.
Details of the calculation¶
The new limits are calculated in three steps:
Determine the inter quartile range (IQR), i.e. the distance between the first (q1) and the third (q3) quartile (see image below).
Expand the region spanned by [q1, q3] by 1.5 x the IQR (yet not beyond the original limits of the min/max of the data).
Limit the amount of data points clipped on each side to an amount that is described by the lower (pl) and upper (pu) cutoff percentiles. E.g. for pu=pl=0.5%, no more the white and gray areas may not take up more than half a percent each of the total area.
To understand how this works lets consider the histogram of the previous example:
[6]:
import matplotlib.pyplot as plt
data = ds.get_parameter_data()["z"]["z"]
pl, q3, q1, pu = np.percentile(data, [97, 75, 25, 3])
fig, ax = plt.subplots(1, 1)
ax.hist(data, bins=100)
# IQR
ax.axvline(q3, color="k")
ax.axvline(q1, color="k")
# cut off
ax.axvline(q1 - 1.5 * (q3 - q1), color="b")
ax.axvline(q3 + 1.5 * (q3 - q1), color="b")
# limit through percentiles
ax.axvline(pl, color="r")
ax.axvline(pu, color="r")
[6]:
<matplotlib.lines.Line2D at 0x7fcc39f66840>
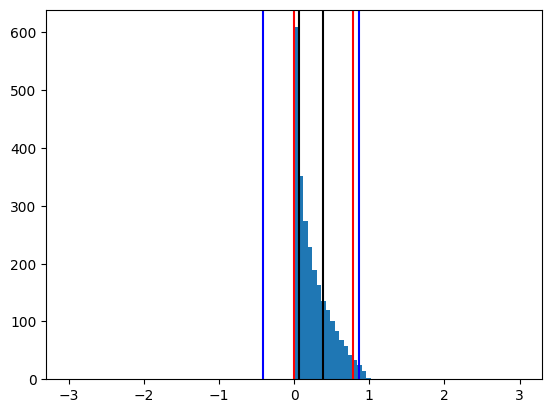
The black lines mark q1 and q3 and the blue lines correspond to the interval widened by 1.5 x IQR. The red lines present the lines of the percentile cutoff, in this case 3% on each side. The red lines limit how much of the data may be cut away through the blue lines. In this specific case of 3% they are not limiting the cutoff through the IQR estimation. Please also note the barely filled bins at +-10, that represent the outliers. The new color scale therefore roughly corresponds to a threefold increase of the steepness of color gradient.
Cutoff Percentiles¶
Limiting the effect of an automatic color scale by the cutoff percentiles can be very important. To understand that consider the following example:
Example 2: data on noisy background with outliers¶
[7]:
# create a new dataset with outliers
ds = dataset_with_outliers_generator(
new_data_set("data_outside_iqr"), data_offset=2, low_outlier=-2, high_outlier=3
)
[8]:
ax, cb = plot_dataset(ds)
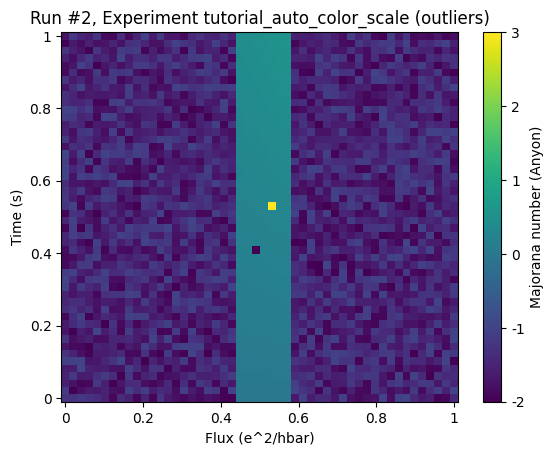
In this example dataset the region of interest shall be represented by the center region. Again there are outliers that render the color grading almost useless.
Looking at the same plot with an automatic color scale without limiting cutoff percentiles (by setting the cutoff to 50% we basically deactivate them) does not give a better result:
[9]:
ax, cb = plot_dataset(ds, auto_color_scale=True, cutoff_percentile=50)
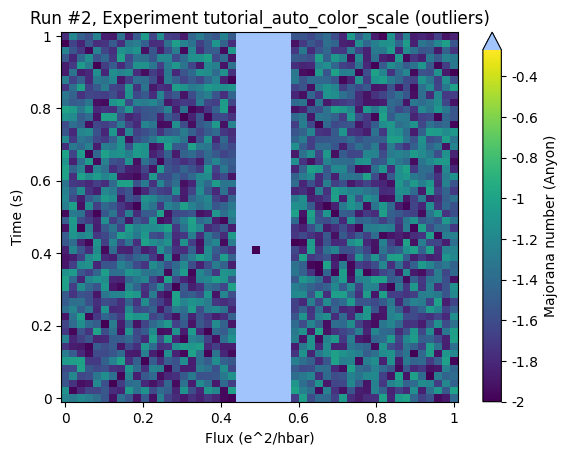
Here all the relevant region is considered as outliers. To make this clearer let’s draw the histogram again:
[10]:
import matplotlib.pyplot as plt
import numpy as np
data = ds.get_parameter_data()["z"]["z"]
pl, q3, q1, pu = np.percentile(data, [99.5, 75, 25, 0.5])
fig, ax = plt.subplots(1, 1)
ax.hist(data, bins=100)
# IQR
ax.axvline(q3, color="k")
ax.axvline(q1, color="k")
# cut off
ax.axvline(q1 - 1.5 * (q3 - q1), color="b")
ax.axvline(q3 + 1.5 * (q3 - q1), color="b")
# limit through percentiles
ax.axvline(pl, color="r")
ax.axvline(pu, color="r")
[10]:
<matplotlib.lines.Line2D at 0x7fcc39bac320>
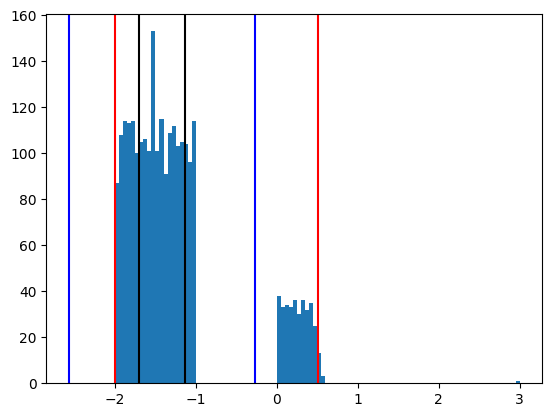
The region of interest is represented by the right hand side structure around 0. The IQR induced limits (blue) does not capture these values. The percentile limits (0.5% here) however save the day:
[11]:
ax, cb = plot_dataset(ds, auto_color_scale=True, cutoff_percentile=0.5)
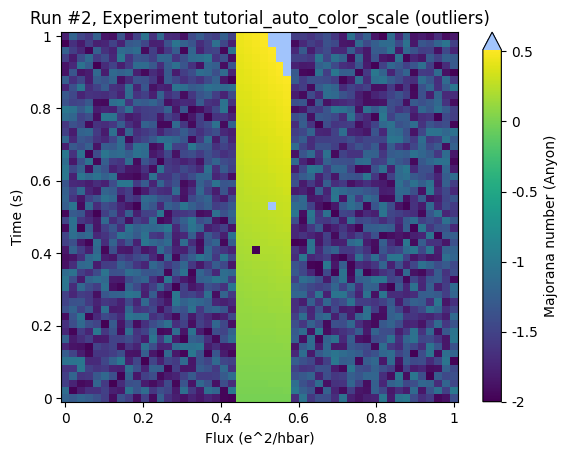
There is some undesired clipping in the top right corner of the ROI but the structure within the ROI is relatively well resolved.
Asymmetric cutoffs¶
Asymmetric cutoffs can be simply defined via a tuples. So for the data of the first example we can disregard the lower outliers that take up up to five percent of the data but not allow any clipping on the upper end:
[12]:
ds = dataset_with_outliers_generator(
new_data_set("data_with_outliers"),
low_outlier=-3,
high_outlier=3,
background_noise=False,
)
ax, cb = plot_dataset(ds, auto_color_scale=True, cutoff_percentile=(0, 5))
Defaults and customizing the auto color scaling¶
The defaults used by plot_dataset can be set in the qcodesrc.json files. The system default is described in qcodes/config/qcodesrc.json (online) To override the default edit these values in your custom qcodesrc.json file in your home directory.
The defaults are (for detailed description see the schema file)
"auto_color_scale":{
"enabled": false,
"cutoff_percentile": [0.5, 0.5],
"color_over": "white",
"color_under": "gray"
}
Because of the possible risks due to auto color scaling it is deactivated by default. Please remember to change the colors marking the outliers in case you should use a color map the includes white and gray.
Using auto color scaling in custom plotting¶
If you are using matplotlib but do not want to rely on plot_dataset, you can simply call: qcodes.utils.plotting.apply_auto_color_scale(colorbar, ...) and provide any matplotlib color bar to achieve the described effects.
If you want to use the qcodes config system for defaults call qcodes.utils.plotting.auto_color_scale_from_config(colorbar,...) instead.
[ ]: